> ## Documentation Index
> Fetch the complete documentation index at: https://gcore.com/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview
Managed Kubernetes in GPU Cloud is a fully managed Kubernetes service for GPU-intensive and mixed-workload clusters. The control plane — the API server, scheduler, controller manager, and etcd — is operated by Gcore, while node pools and workloads remain under the operator's control. Gcore is a [CNCF certified](https://www.cncf.io/training/certification/software-conformance/) Kubernetes provider, so existing tooling, manifests, and operators work without modification.
## Cluster architecture
Each cluster consists of a Gcore-managed control plane and one or more node pools. The control plane manages scheduling, cluster state, and API access. Node pools are groups of worker nodes with identical configuration — instance type, volume settings, and network interface — where workloads run.
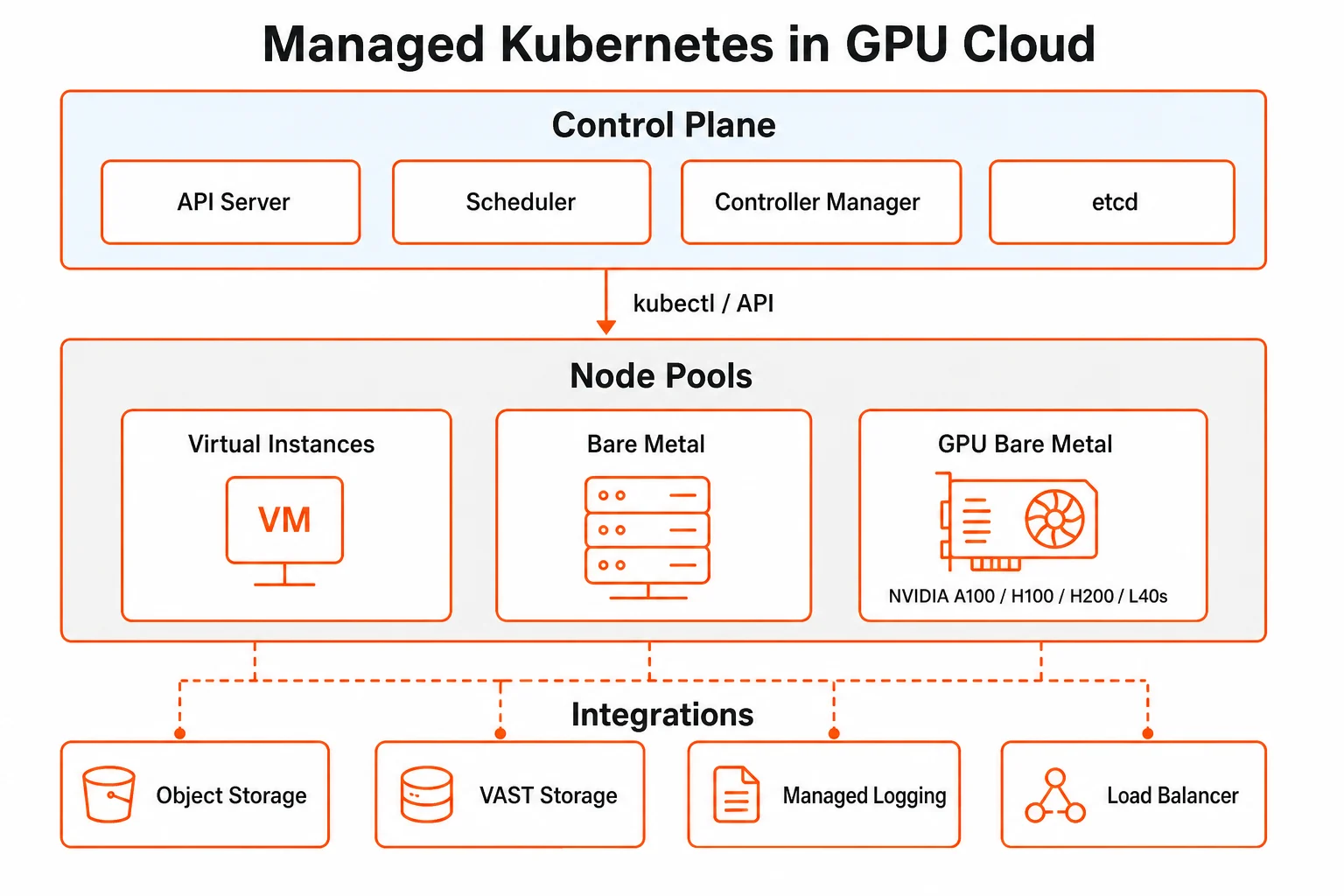 Pools within the same cluster can use different instance types, allowing GPU and CPU workloads to run side by side. The cluster autoscaler adjusts pool size based on pending pod demand and node utilization, within the min/max limits configured per pool.
## Node types
A cluster can include any combination of the following node types:
| Type | Hardware | Use case |
| ------------------------ | -------------------------------------------------------- | --------------------------------------- |
| Virtual instances | Standard VMs | Development, testing, general workloads |
| Bare metal instances | Dedicated physical servers | High-performance CPU workloads |
| GPU bare metal instances | NVIDIA A100, H100, H200, L40s with built-in NVMe storage | Model training, inference at scale |
Available GPU models and bare metal configurations depend on the selected region.
## Integrations
Clusters connect to Object Storage for artifact and dataset storage and to [VAST Storage](/cloud/file-shares/configure-file-shares) for high-performance NFS file shares optimized for GPU workloads. Managed Logging collects and stores cluster logs in OpenSearch Dashboards; Load Balancer integrates with the Kubernetes cloud controller manager for native traffic distribution.
Pools within the same cluster can use different instance types, allowing GPU and CPU workloads to run side by side. The cluster autoscaler adjusts pool size based on pending pod demand and node utilization, within the min/max limits configured per pool.
## Node types
A cluster can include any combination of the following node types:
| Type | Hardware | Use case |
| ------------------------ | -------------------------------------------------------- | --------------------------------------- |
| Virtual instances | Standard VMs | Development, testing, general workloads |
| Bare metal instances | Dedicated physical servers | High-performance CPU workloads |
| GPU bare metal instances | NVIDIA A100, H100, H200, L40s with built-in NVMe storage | Model training, inference at scale |
Available GPU models and bare metal configurations depend on the selected region.
## Integrations
Clusters connect to Object Storage for artifact and dataset storage and to [VAST Storage](/cloud/file-shares/configure-file-shares) for high-performance NFS file shares optimized for GPU workloads. Managed Logging collects and stores cluster logs in OpenSearch Dashboards; Load Balancer integrates with the Kubernetes cloud controller manager for native traffic distribution.