
Das Domain Name System (DNS) ist eine Namensdatenbank, die Computern erlaubt, einen Domainnamen (z. B. google.com) zu identifizieren und in eine IP-Adresse (z. B. 74.125.226.72) zu übersetzen. DNS-Zonen sind bestimmte Teile des DNS, die von einer bestimmten Organisation oder einem Administrator verwaltet werden. Diese DNS-Zonen sind für das DNS als Ganzes von entscheidender Bedeutung, da sie die Verwaltung von DNS-Einträgen in großen, verteilten Netzwerken vereinfachen. In diesem Artikel befassen wir uns ausführlich mit DNS-Zonen. Wir erklären, was DNS-Zonen sind, wie sie funktionieren und warum sie für die Verwaltung von DNS-Einträgen wichtig sind.
Die Grundlagen von DNS-Zonen
Eine DNS-Zone ist eine logische Einheit, die sich auf eine bestimmte Domain und ihre Subdomains bezieht, die von einem einzigen Administrator verwaltet werden. Dieses Konzept ist recht komplex, also schlüsseln wir es zunächst auf.
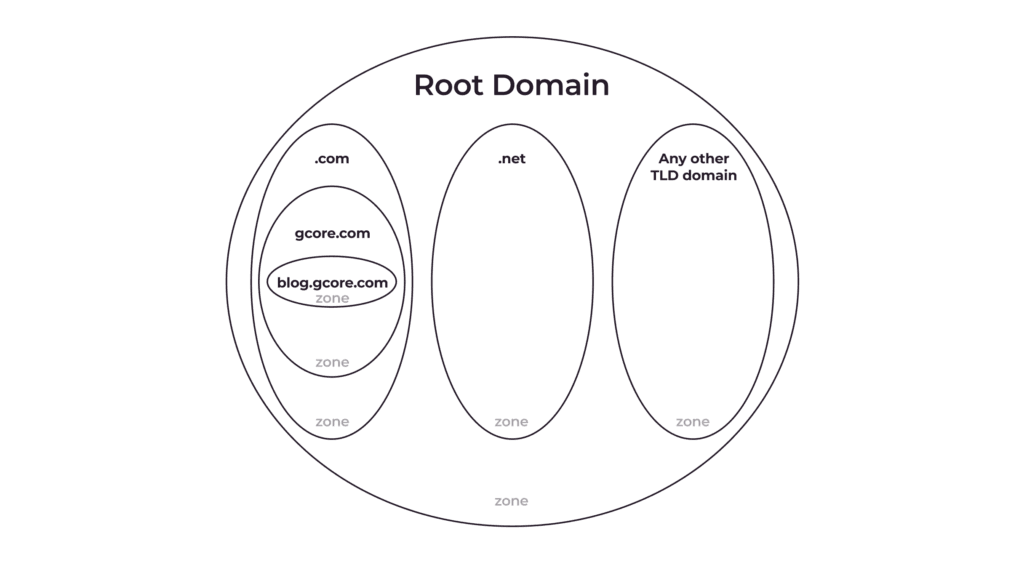
Was genau ist eine DNS-Zone?
Eine DNS-Zone ist keine materielle Einheit. Der Begriff wird verwendet, um anzuzeigen, dass eine bestimmte Domain – oder ein Teil davon (eine Subdomain/Subdomains) – von einem einzigen Administrator verwaltet wird. Der Administrator kann DNS-Einträge in Bezug auf seine DNS-Zone verwalten, indem er Einträge ändert, hinzufügt oder löscht.
Wenn Sie eine Domain kaufen, erhalten Sie automatisch die Kontrolle über ihre DNS-Zone; Sie können den DNS-Eintrag dieser Domain und ihrer Subdomains verwalten. Wenn Sie möchten, können Sie jedoch einige Subdomains abtrennen (delegieren), sodass sie von jemand anderem verwaltet werden. Eine solche Trennung bedeutet, dass Sie eine neue DNS-Zone erstellen, die nur die abgetrennten Subdomains enthält.
Wozu eine separate DNS-Zone?
Der Domaininhaber kann Subdomains trennen und eine neue DNS-Zone erstellen, um die Verwaltung der DNS-Einträge zu erleichtern. gcore.com hat beispielsweise einige Subdomains, darunter:
- account.gcore.com
- api.gcore.com
- speedtest.gcore.com
Nehmen wir an, ein spezielles Team ist für den Speedtest verantwortlich. Um ihnen Autonomie zu gewähren, können wir speedtest.gcore.com in eine eigene DNS-Zone auslagern und das Speedtest-Team zum Administrator machen. Wenn sie den Geschwindigkeitstest auf einen anderen Server verschieben oder vielleicht mit einem Mailserver verknüpfen möchten, können sie dies selbst tun, ohne die Hauptseite zu beeinträchtigen oder eine externe Genehmigung zu benötigen.
Häufig gestellte Fragen zu DNS-Zonen
Welche Bestandteile umfasst eine DNS-Zone?
Eine DNS-Zone enthält Ressourceneinträge als Bestandteile. Ein SOA- und zwei NS-Einträge sind obligatorisch.
Sind Top-Level-Domains auch DNS-Zonen?
Ja. Sie delegieren einfach die Kontrolle über ihre Subdomains (d. h. Second-Level-Domains) an die Eigentümer dieser Subdomains.
Wie lassen sich Subdomains in eine separate DNS-Zone aufteilen?
Sie müssen der Hauptdomain NS-Einträge für die entsprechenden Subdomains hinzufügen. Weitere Informationen finden Sie im Abschnitt DNS-Zonendelegation in diesem Artikel.
Entspricht jede DNS-Zone einer Datei mit DNS-Einträgen?
Ja. Eine DNS-Zone entspricht einer Datei, die alle DNS-Einträge für diese spezielle DNS-Zone enthält.
Kann eine DNS-Zone verschiedene Second-Level-Domains enthalten?
Nein, sie kann nur Subdomains derselben Domain oder die Domain selbst enthalten.
Sind DNS-Zonen an bestimmte DNS-Server gebunden?
Nein. Eine DNS-Zone entspricht einer Datei mit DNS-Einträgen. Eine solche Datei kann auf jedem DNS-Server gespeichert werden. Mit anderen Worten: es können verschiedene Dateien für verschiedene DNS-Zonen auf demselben Server gespeichert werden.
Was ist eine DNS-Zonendatei?
Eine DNS-Zonendatei wird in der Regel in Form einer reinen Textdatei präsentiert, die alle wichtigen Informationen über einen Domainnamen enthält. Sie enthält Ressourceneinträge, die zur Zuordnung und Verknüpfung von Domainnamen mit entsprechenden Anfragen verwendet werden.
Eine DNS-Zonendatei enthält in der Regel einen SOA- (Start of Authority) und einen NS-Eintrag sowie andere relevante Ressourceneinträge (RRs), einschließlich – aber nicht beschränkt auf – MX-, CNAME-, A- und TXT-Einträge. Schauen wir uns kurz an, was die gängigsten Arten von Einträgen tun.
| Ressourceneinträge in DNS-Zonendateien | Funktion(en) |
| SOA-Einträge (Start of Authority) | Geben die primäre Autoritätsquelle für die Domain an, einschließlich aller wichtigen Informationen wie dem primären DNS-Server, der Kontakt-E-Mail-Adresse und den Einstellungen, die den Betrieb der Domain steuern |
| NS-Einträge (Nameserver) | Geben die IP-Adressen der autorisierenden Nameserver an und welche Server für die Bereitstellung von DNS-Informationen über die Domain verantwortlich sind |
| A-Einträge (Adresse) | Ordnen die Domainnamen den zugehörigen IP-Adressen zu |
| MX-Einträge (Mail Exchange) | Identifizieren die Mailserver, die für die Bearbeitung von E-Mails für die Domain zuständig sind |
| CNAME-Einträge (kanonischer Name) | Geben einen Alias mit einem tatsächlichen Domainnamen für bestehende A-Einträge an |
| TXT-Einträge (Text) | Enthalten textbasierte Informationen, die mit der Domain verknüpft sind, wie z.B. SPF-Einträge (Sender Policy Framework), die für die Überprüfung der Domaininhaberschaft verwendet werden |
Wie sieht eine DNS-Zonendatei aus?
Hier ist ein Beispiel dafür, wie eine DNS-Zonendatei für gcore.com im BIND-Format aussehen könnte:
$TTL 1h@ IN SOA dns1.gcore.com. hostmaster.gcore.com. ( 20211209 1d 2h 4w 1h ) IN NS dns1.gcore.com. IN NS dns2.gcore.com. IN MX 10 mail.gcore.com.dns1 IN A 192.168.0.1dns2 IN A 192.168.0.2mail IN A 192.168.0.3web IN A 192.168.0.4www IN CNAME webftp IN CNAME web@ IN TXT "v=spf1 a mx include:spf.gcore.com ~all"spf IN TXT "v=spf1 include:spf.protection.outlook.com include:spf.emailsignatures365.com -all"In diesem Beispiel beginnt die DNS-Zonendatei mit einer Time-to-Live-Direktive, die die Dauer für die Zwischenspeicherung von DNS-Einträgen festlegt. Das Symbol „@“ steht für die Root (Wurzel) der Domain. Als Nächstes folgt der SOA-Eintrag (Start of Authority), der den primären DNS-Server für die Domain identifiziert und die E-Mail-Adresse des Administrators enthält. Mit dem Befehl IN NS (Internet Nameserver) werden zwei Nameserver angegeben, und es wird ein MX-Eintrag hinzugefügt, um den Mailserver zu benennen und ihm einen Prioritätswert von 10 zuzuweisen.
Es sind mehrere A-Einträge enthalten, um die IP-Adresse verschiedener Server zu definieren. Diese A-Einträge geben die IP-Adressen des DNS-Servers, des Mailservers und des Webservers an. Die Zonendatei enthält auch CNAME-Einträge, die als Aliase oder alternative Namen für den Webserver dienen. So können verschiedene Domainnamen auf denselben Webserver verweisen. Schließlich wird ein TXT-Eintrag eingefügt, um den SPF-Eintrag (Sender Policy Framework) für die E-Mail-Authentifizierung anzugeben. Mit diesem Eintrag können Sie überprüfen, ob die eingehenden E-Mails von autorisierten Servern stammen.
Durch die Strukturierung der DNS-Zonendateien auf diese Weise können Administratoren die DNS-Einträge für ihre Domain effektiv verwalten. Dies gewährleistet die ordnungsgemäße Weiterleitung von E-Mails, den Zugriff auf die Website und die E-Mail-Authentifizierung.
DNS-Zonendelegation
Die Delegation von DNS-Zonen ist ein Prozess, bei dem eine größere DNS-Zone in kleinere Zonen unterteilt und diesen verschiedenen DNS-Servern zugewiesen werden. Dieses Verfahren ermöglicht eine effizientere und lokalisierte Bearbeitung von DNS-Anfragen, insbesondere für größere Organisationen mit mehreren Subdomains. Durch die Delegierung von Zonen wird die Belastung eines einzelnen Servers verringert, was zu einer verbesserten Leistung und Verfügbarkeit der gesamten DNS-Infrastruktur führt.
Betrachten wir ein Szenario, in dem ein großes Unternehmen eine primäre Domain (z.B. example.com) sowie mehrere Subdomains (z.B. it.example.com, europe.example.com, us.example.com, usw.). Um den DNS-Betrieb zu optimieren, kann das Unternehmen jede Subdomain an separate DNS-Server delegieren, um die Arbeitslast zu verteilen und die Effizienz zu steigern.
Delegieren einer DNS-Zone
Um eine DNS-Zone zu delegieren, müssen bestimmte Schritte befolgt werden. Der Administrator muss NS-Einträge (Nameserver) für die Subdomain erstellen. Diese NS-Einträge weisen die autorisierenden Server zu, die für die Bearbeitung von DNS-Anfragen für die Subdomain zuständig sind. Wenn der Administrator zum Beispiel die Subdomain it.example.com delegiert, muss ein NS zur Zonendatei example.com hinzugefügt werden. Dieser NS-Eintrag bedeutet, dass die Zonendatei, die die Subdomain „it“ verwaltet, die Berechtigung hat, alle damit verbundenen DNS-Anfragen zu bearbeiten.
Wie arbeiten DNS-Zonen?
Stellen Sie sich vor, Sie besitzen die Domain example.com. Wenn jemand example.com in seinen Webbrowser eingibt, sendet sein Gerät eine DNS-Anfrage an einen Server, der die IP-Adresse Ihrer Website anfordert. Der Server sucht dann nach autoritativen DNS-Zonen für Ihre Domain und fragt diese nach der IP-Adresse Ihrer Website. Sobald diese IP-Adresse ermittelt wurde, wird sie verwendet, um eine Verbindung zwischen dem Gerät des Besuchers und dem Server, der Ihre Website hostet, herzustellen.
Als Eigentümer oder Administrator einer Website können Sie mit DNS-Zonen DNS-Einträge für bestimmte Teile Ihrer Domain verwalten. Sie können zum Beispiel separate DNS-Zonen für mail.example.com oder blog.example.com haben, ohne die Einträge für die gesamte Domain example.com zu beeinflussen.
Um eine solche DNS-Zone zu erstellen, müssen Sie im Control Panel des Servers die Subdomain angeben, die Sie verwalten möchten, und NS-Einträge für die Subdomain erstellen. Der NS-Eintrag kann die Form eines „A“-Eintrags haben, der die Subdomain mit einer IP-Adresse verknüpft, oder eines „MX“-Eintrags, der den Mailserver für die Bearbeitung von E-Mails für die Subdomain angibt.
Was sind DNS-Zonenänderungen?
DNS-Zonenänderungen sind Änderungen an den DNS-Informationen, die mit einer bestimmten Domain verbunden sind. Dazu gehören Änderungen an der IP-Adresse des Servers, der für das Hosting der Website zuständig ist, die Anpassung der Mailserver-Einstellungen oder das Hinzufügen neuer Server. Diese Änderungen können absichtlich oder versehentlich erfolgen, wenn der Domaininhaber oder sein Vertreter sie vornimmt. Es ist jedoch wichtig zu wissen, dass DNS-Zonenänderungen von Cyberkriminellen böswillig herbeigeführt werden können.
Wozu DNS-Zonenänderungen verfolgen?
Die Verfolgung von DNS-Zonenänderungen ist entscheidend für den reibungslosen Betrieb und die Sicherheit einer Website. Änderungen an DNS-Einträgen können erhebliche Auswirkungen auf die Funktionalität einer Website haben. Ein Paradebeispiel ist der Facebook-Ausfall 2021, bei dem die Website etwa sieben Stunden lang nicht erreichbar war. Der Ausfall wurde durch den Verlust von IP-Routen zu den DNS-Servern von Facebook verursacht. Der daraus resultierende Umsatzverlust für Facebook lag zwischen 60-100 Millionen US-Dollar.
Darüber hinaus können böswillige DNS-Zonenänderungen ernsthafte Risiken darstellen. Sie können Besucher auf nicht autorisierte Websites umleiten und so die Sicherheit der Nutzer gefährden. Diese Änderungen können auch Hintertüren für das Eindringen in Datenbanken und potenzielle Verletzungen des Datenschutzes öffnen, die oft durch DDoS-Angriffe ausgelöst werden.
Unternehmen können Änderungen an den DNS-Einträgen ihrer Domain überwachen, indem sie DNS-Zonenänderungen aktiv verfolgen. Diese Überwachung ermöglicht Unternehmen, unautorisierte oder unerwartete Änderungen sofort zu erkennen und zu beheben, was für die Sicherung der Online-Präsenz und den Schutz des Vertrauens der Benutzer unerlässlich ist.
Verfolgen von DNS-Zonenänderungen
Es gibt fünf Techniken, die Unternehmen einsetzen können, um DNS-Zonenänderungen zu verfolgen:
| Methode | Funktionsweise |
| Zone Change Notification (ZCN) | Mit dieser Funktion können DNS-Server Benachrichtigungen an andere DNS-Server senden, wenn eine Änderung in einer DNS-Zone erfolgt. Durch die Aktivierung von ZCN können DNS-Server mit ihren Zoneninformationen auf dem neuesten Stand bleiben und bei Bedarf zur Replikation von Zonen verwendet werden. |
| DNS-Protokollierung | Viele DNS-Server bieten Protokollierungsfunktionen, die DNS-Anfragen und -Updates überwachen. Diese Protokolle enthalten eine Aufzeichnung der DNS-Zonenänderungen und ermöglichen es, Probleme, die durch DNS-Zonenänderungen entstehen, zu identifizieren und zu beheben. |
| Externe Überwachungsdienste | Diese Dienste verwenden automatische Tools, um fortlaufend DNS-Antworten zu überwachen. Sie erkennen Änderungen, wie z. B. das Hinzufügen oder Entfernen von DNS-Einträgen, und senden Echtzeitwarnungen, wenn DNS-Zonenänderungen auftreten. So können Sie schnell auf mögliche Probleme reagieren. |
| Dig | Mit diesem Befehlszeilentool können Sie DNS-Informationen abrufen, einschließlich DNS-Einträge, Nameserver und IP-Adressen. Dig kann auch verwendet werden, um DNS-Zonenänderungen zu verfolgen, indem DNS-Anfragen an DNS-Server vor und nach der Zonenänderung verglichen werden, was dem Benutzer hilft, Unterschiede festzustellen. |
| DNS Query Analysis | Diese Technik analysiert DNS-Anfragen, die von DNS-Servern empfangen werden, um Änderungen in DNS-Zonen zu verfolgen. Sie bietet wertvolle Einblicke in die abgefragten Domains und Subdomains, die Art der Abfragen und die Häufigkeit der Abfragen zu bestimmten DNS-Einträgen. Die Überwachung dieser Muster kann Änderungen an den entsprechenden DNS-Zonen anzeigen. |
Wozu DNS-Zonenänderungen überwachen?
Die Überwachung von DNS-Zonenänderungen hat drei Hauptvorteile: Unerlaubte Änderungen werden sofort erkannt, die Genauigkeit der DNS-Einträge wird sichergestellt und die Verwaltung der IT-Ressourcen wird verbessert.
Sofortige Erkennung von nicht autorisierten Änderungen
Nicht autorisierte Änderungen an DNS-Zonen, ob versehentlich oder böswillig, können zu DNS-Fehlern, langsamen Antwortzeiten bei Abfragen und sogar zu Fehlern bei der Auflösung von Domainnamen führen. Angreifer können versuchen, DNS-Einträge zu ändern, um Benutzer auf Phishing-Seiten umzuleiten, den Traffic abzufangen oder sensible Daten zu kompromittieren. Die aktive Überwachung von DNS-Zonenänderungen trägt dazu bei, diese Risiken zu minimieren, indem sie unautorisierte Änderungen sofort identifiziert und DNS-Administratoren in die Lage versetzt, sofortige Maßnahmen zu ergreifen.
Genauigkeit von DNS-Einträgen
Wenn eine Website oder die IP-Adresse eines Servers geändert wird, sind entsprechende Aktualisierungen der DNS-Einträge erforderlich, um einen nahtlosen Benutzerzugriff auf den neuen Server zu gewährleisten. Falsche oder veraltete DNS-Einträge können zu Ausfallzeiten der Website, langsamen Ladezeiten oder sogar zur vollständigen Unerreichbarkeit der Website führen. Durch die Überwachung von DNS-Zonenänderungen können Unternehmen die Richtigkeit von DNS-Einträgen überprüfen, was für eine nahtlose Benutzererfahrung und die proaktive Vermeidung potenzieller Probleme entscheidend ist.
Bessere Verwaltung der IT-Ressourcen
Die regelmäßige Überwachung von DNS-Zonenänderungen hilft bei der effizienten Zuweisung von IT-Ressourcen. Indem sie sich über Änderungen auf dem Laufenden halten, können Teams ihre Aktivitäten optimieren, Ausfallzeiten minimieren und Betriebskosten senken.
Was ist eine Reverse Lookup Zone?
Eine Reverse Lookup Zone ermöglicht die Identifizierung von Domainnamen, die mit bestimmten IP-Adressen verbunden sind. Sie arbeitet gegensätzlich zur gebräuchlicheren Forward Lookup Zone, die die mit einem Domainnamen verknüpfte IP-Adresse findet.
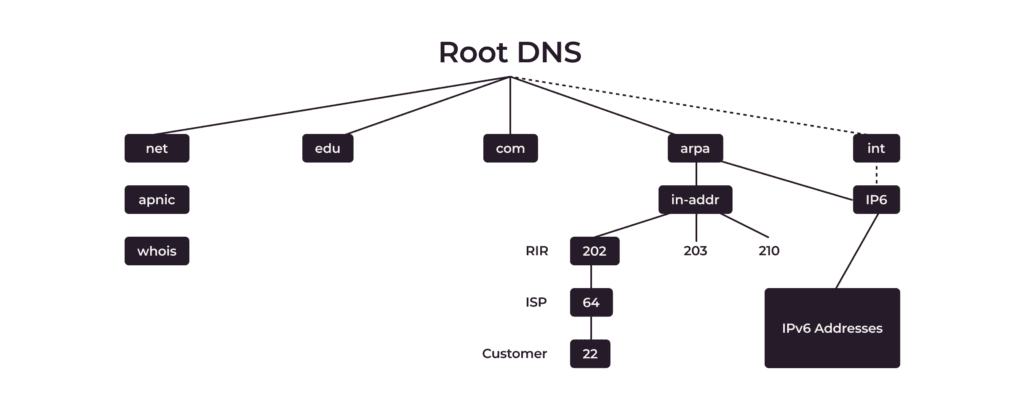
Eine Reverse Lookup Zone verwendet spezielle PTR-Einträge (Pointer). Sie verwendet die Domain in-addr.appa, und die IP-Adressen sind von den weniger spezifischen zu den spezifischeren angeordnet, während die Domainnamen von den spezifischeren zu den weniger spezifischen angeordnet sind. In der obigen Abbildung lautet die IP-Adresse des Clients zum Beispiel 22.64.202.in-addr.appa.
PTR werden immer in der Reverse Zone verwaltet (nicht in der Forward Zone), wie etwa in-addr.arpaoder ip6.arpa z.B. <octet_2>.<octet_1>.in-addr.arpa. Ihr Internetanbieter muss die Zone an Ihre NS delegieren. Wenn Sie also einen Reverse Lookup durchführen, sucht der DNS-Server nach dem PTR-Eintrag, der der von Ihnen angegebenen IP-Adresse entspricht, und ruft den zugehörigen Domainnamen ab.
Reverse Lookup Zonen sind besonders in größeren Netzwerken mit zahlreichen IP-Adressen für die Fehlersuche bei Netzwerkproblemen nützlich. Wenn Sie beispielsweise verdächtige Aktivitäten feststellen, die von einer bestimmten IP-Adresse im Netzwerk Ihres Unternehmens ausgehen, ist es einfach, den mit dieser IP-Adresse verbundenen Domainnamen visuell zu ermitteln.
Außerdem sind PTR-Einträge in öffentlichen Netzwerken weit verbreitet. Sie können den Namen identifizieren, der mit einer IP-Adresse verbunden ist, und eine faire Vermutung darüber anstellen, wer für den Teil des Netzwerks verantwortlich ist, der überlastet ist oder bösartigen Traffic erzeugt. Beispiel:
traceroute to 1.1.1.1 (1.1.1.1), 64 hops max, 52 byte packets 1 192.168.31.1 (192.168.31.1) 10.842 ms 3.846 ms 3.389 ms 2 192.168.178.1 (192.168.178.1) 5.021 ms 5.808 ms 5.727 ms 3 dhcp-077-249-057-001.chello.nl (77.249.57.1) 16.033 ms 13.006 ms 15.976 ms 4 212.142.51.25 (212.142.51.25) 11.897 ms 14.024 ms 12.946 ms 5 asd-tr0021-cr101-be112-2.core.as33915.net (213.51.7.92) 15.071 ms 14.261 ms 15.145 ms 6 nl-ams14a-ri1-ae51-0.core.as9143.net (213.51.64.186) 18.707 ms 16.519 ms 23.037 ms 7 213.46.191.210 (213.46.191.210) 15.810 ms 16.197 ms 16.946 ms 8 172.71.96.2 (172.71.96.2) 15.055 ms 172.70.44.2 (172.70.44.2) 14.475 ms 172.71.180.2 (172.71.180.2) 16.163 ms 9 one.one.one.one (1.1.1.1) 19.013 ms 17.318 ms 21.799 msSie werden feststellen, dass einige Adressen keine zugehörigen PTR-Einträge haben. In der Regel handelt es sich dabei um Adressen aus privaten IP-Bereichen, die auf internen Schnittstellen der Router verwendet werden. Obwohl wir ihren Namen nicht öffentlich sehen können, haben die meisten Anbieter PTRs für sie auf ihren eigenen Nameservern, und sie werden aufgelöst, wenn diese Nameserver in Gebrauch sind, z. B. innerhalb des Netzwerks des Providers.
Es ist auch erwähnenswert, dass ein PTR-Eintrag nicht zwingend mit dem Forward-Eintrag übereinstimmen muss und im Allgemeinen ein beliebiger Domainname sein kann. So kann jeder, der Zugriff auf die Subzone in-addr.arpagoogle.com hat, PTR für oder jeden anderen Domainnamen erstellen, was wiederum einen Benutzer oder Netzwerkadministrator in die Irre führen kann.
Fazit
DNS-Zonen spielen eine wichtige Rolle im breiteren DNS-System und ermöglichen eine effiziente Verwaltung bestimmter Untergruppen von DNS-Einträgen. Eine effektive DNS-Verwaltung ist unerlässlich, um die Zugänglichkeit von Websites und die Zustellung von E-Mails aufrechtzuerhalten und verschiedene Online-Aktivitäten zu unterstützen. Eine schlechte DNS-Verwaltung kann zu einem Rückgang des Traffics, zu Umsatzeinbußen und zu einem schwindenden Vertrauen der Nutzer führen. Glücklicherweise können Unternehmen die DNS-Verwaltung durch den Einsatz geeigneter Tools und Ressourcen optimieren und so sowohl die Effizienz als auch die Sicherheit der Kommunikation zwischen Benutzergeräten und den von ihnen gewählten Servern verbessern.
Gcore bietet fortschrittliche Funktionen, die Unternehmen ermöglichen, DNS-Zonen zu verfolgen, nicht autorisierte Änderungen zu erkennen und Probleme schnell zu lösen. Die Dienste von Gcore umfassen umfassende Tracking-, Überwachungs- und Sicherheitsfunktionalitäten. Gcore bietet außerdem schnelle, robustes und zuverlässiges Enterprise-Grade-DNS-Hosting. Mit Gcore können Unternehmen die DNS-Verwaltung optimieren und ein sicheres, nahtloses Online-Erlebnis für ihre Nutzer gewährleisten.
Ähnliche Artikel


Die Fehlermeldung „403 Forbidden“ auf einer Website bedeutet, dass der Inhalt, auf den ein Benutzer zuzugreifen versucht, blockiert wird. Dieses frustrierende Hindernis hat seinen Ursprung oft auf der Seite des Website-Besuchers, aber die U




Melden Sie sich für unseren Newsletter an
Erhalten Sie die neuesten Branchentrends, exklusive Einblicke und Gcore-Updates direkt in Ihren Posteingang.