Deploying highly scalable cloud storage with Rook, Part 1 (Ceph Storage)
- By Gcore
- March 27, 2023
- 6 min read

It goes without saying that if you want to orchestrate containers at this point, Kubernetes is what you use to do it. Sure, there may be a few Docker Swarm holdouts still around, but for the most part, K8s has cemented itself as the industry standard for container orchestration solutions. As Kubernetes matures, the tools that embody its landscape begin to mature along with it. One of the areas we have seen some optimization, in particular, is in cloud-native storage solutions.
What is Rook?
Rook is an open-source cloud-native storage orchestrator, providing the platform, framework, and support for a diverse set of storage solutions to natively integrate with cloud-native environments.
It turns storage software into self-managing, self-scaling, and self-healing storage services. It does this by automating deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management. Rook uses the facilities provided by the underlying cloud-native container management, scheduling, and orchestration platform to perform its duties. It supports a variety of different block, object, and file type storage.
Rook integrates deeply into cloud-native environments leveraging extension points and providing a seamless experience for scheduling, lifecycle management, resource management, security, monitoring, and user experience.
What is Ceph?
Ceph is a distributed storage system that is massively scalable and high-performing with no single point of failure. Ceph is a Software Distributed System (SDS), meaning it can be run on any hardware that matches its requirements.
Ceph consists of multiple components:
- Ceph Monitors (MON) are responsible for forming cluster quorums. All the cluster nodes report to monitor nodes and share information about every change in their state.
- Ceph Object Store Devices (OSD) are responsible for storing objects on local file systems and providing access to them over the network. Usually, one OSD daemon is tied to one physical disk in your cluster. Ceph clients interact with OSDs directly.
- Ceph Manager (MGR) provides additional monitoring and interfaces to external monitoring and management systems.
- Reliable Autonomic Distributed Object Stores (RADOS) are at the core of Ceph storage clusters. This layer makes sure that stored data always remains consistent and performs data replication, failure detection, and recovery among others.
To read/write data from/to a Ceph cluster, a client will first contact Ceph MONs to obtain the most recent copy of their cluster map. The cluster map contains the cluster topology as well as the data storage locations. Ceph clients use the cluster map to figure out which OSD to interact with and initiate a connection with the associated OSD.
Rook enables Ceph storage systems to run on Kubernetes using Kubernetes primitives. The following image illustrates how Ceph Rook integrates with Kubernetes:
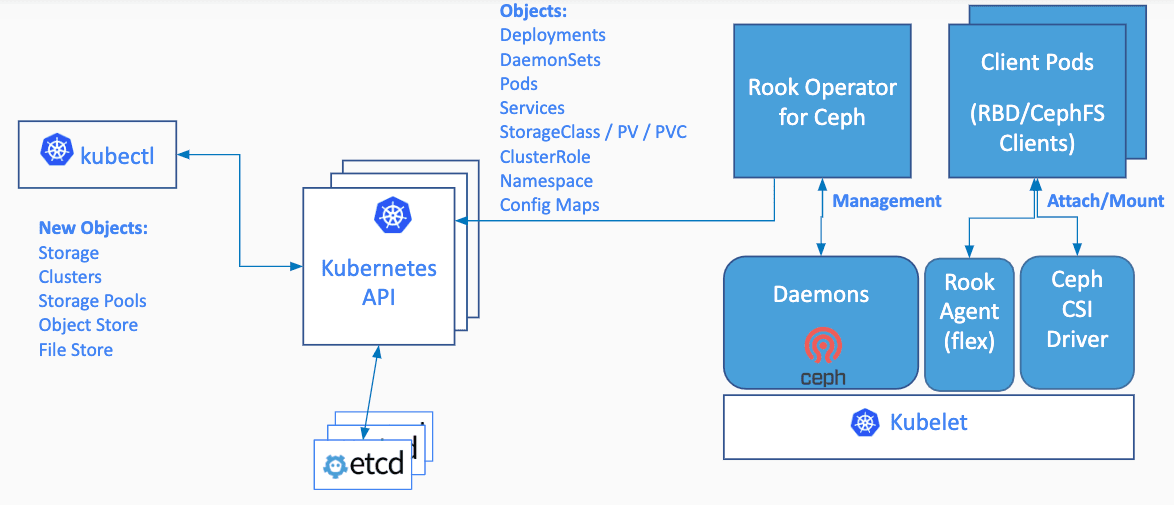
With Ceph running in the Kubernetes cluster, Kubernetes applications can mount block devices and filesystems managed by Rook, or can use the S3/Swift API for object storage. The Rook operator automates configuration of storage components and monitors the cluster to ensure the storage remains available and healthy.
The Rook operator is a simple container that has all that is needed to bootstrap and monitor the storage cluster. The operator will start and monitor Ceph monitor pods, the Ceph OSD daemons to provide RADOS storage, as well as start and manage other Ceph daemons. The operator manages CRDs for pools, object stores (S3/Swift), and filesystems by initializing the pods and other artifacts necessary to run the services.
The operator will monitor the storage daemons to ensure the cluster is healthy. Ceph mons will be started or failed over when necessary, and other adjustments are made as the cluster grows or shrinks. The operator will also watch for desired state changes requested by the api service and apply the changes.

The rook/ceph image includes all necessary tools to manage the cluster – there are no changes to the data path. Rook does not attempt to maintain full fidelity with Ceph. Many of the Ceph concepts like placement groups and crush maps are hidden so you don’t have to worry about them. Instead, Rook creates a much simplified UX for admins that is in terms of physical resources, pools, volumes, filesystems, and buckets. At the same time, an advanced configuration can be applied when needed with the Ceph tools.
Rook is implemented in Golang. Ceph is implemented in C++ where the data path is highly optimized. We believe this combination offers the best of both worlds.
Getting Started
This guide will walk you through the basic setup of a Ceph cluster and enable you to consume block, object, and file storage from other pods running in your cluster.
Minimum Version
Kubernetes v1.10 or higher is supported by Rook.
Prerequisites
To make sure you have a Kubernetes cluster that is ready for Rook, you can follow these instructions.
If you are using dataDirHostPath to persist rook data on Kubernetes hosts, make sure your host has at least 5GB of space available on the specified path.
TL;DR
If you’re feeling lucky, a simple Rook cluster can be created with the following kubectl commands and example yaml files. For the more detailed install, skip to the next section to deploy the Rook operator.
git clone --single-branch --branch release-1.2 https://github.com/rook/rook.gitcd cluster/examples/kubernetes/cephkubectl create -f common.yamlkubectl create -f operator.yamlkubectl create -f cluster-test.yamlAfter the cluster is running, you can create block, object, or file storage to be consumed by other applications in your cluster.
Production Environments
For production environments, it is required to have local storage devices attached to your nodes. In this walkthrough, the requirement of local storage devices is relaxed so you can get a cluster up and running as a “test” environment to experiment with Rook. A Ceph filestore OSD will be created in a directory instead of requiring a device. For production environments, you will want to follow the example in cluster.yaml instead of cluster-test.yaml in order to configure the devices instead of test directories. See the Ceph examples for more details.
Deploy the Rook Operator
The first step is to deploy the Rook operator. Check that you are using the example yaml files that correspond to your release of Rook. For more options, see the examples documentation.
cd cluster/examples/kubernetes/cephkubectl create -f common.yamlkubectl create -f operator.yaml## verify the rook-ceph-operator is in the `Running` state before proceedingkubectl -n rook-ceph get podYou can also deploy the operator with the Rook Helm Chart.
Create a Rook Ceph Cluster
Now that the Rook operator is running we can create the Ceph cluster. For the cluster to survive reboots, make sure you set the dataDirHostPath property that is valid for your hosts. For more settings, see the documentation on configuring the cluster.
Save the cluster spec as cluster-test.yaml:
apiVersion: ceph.rook.io/v1kind: CephClustermetadata: name: rook-ceph namespace: rook-cephspec: cephVersion: # For the latest ceph images, see https://hub.docker.com/r/ceph/ceph/tags image: ceph/ceph:v14.2.5 dataDirHostPath: /var/lib/rook mon: count: 3 dashboard: enabled: true storage: useAllNodes: true useAllDevices: false # Important: Directories should only be used in pre-production environments directories: - path: /var/lib/rookCreate the cluster:
kubectl create -f cluster-test.yamlUse kubectl to list pods in the rook-ceph namespace. You should be able to see the following pods once they are all running. The number of OSD pods will depend on the number of nodes in the cluster and the number of devices and directories configured. If you did not modify the cluster-test.yaml above, it is expected that one OSD will be created per node. The rook-ceph-agent and rook-discover pods are also optional depending on your settings.
$ kubectl -n rook-ceph get podNAME READY STATUS RESTARTS AGErook-ceph-agent-4zkg8 1/1 Running 0 140srook-ceph-mgr-a-d9dcf5748-5s9ft 1/1 Running 0 77srook-ceph-mon-a-7d8f675889-nw5pl 1/1 Running 0 105srook-ceph-mon-b-856fdd5cb9-5h2qk 1/1 Running 0 94srook-ceph-mon-c-57545897fc-j576h 1/1 Running 0 85srook-ceph-operator-6c49994c4f-9csfz 1/1 Running 0 141srook-ceph-osd-0-7cbbbf749f-j8fsd 1/1 Running 0 23srook-ceph-osd-1-7f67f9646d-44p7v 1/1 Running 0 24srook-ceph-osd-2-6cd4b776ff-v4d68 1/1 Running 0 25srook-ceph-osd-prepare-node1-vx2rz 0/2 Completed 0 60srook-ceph-osd-prepare-node2-ab3fd 0/2 Completed 0 60srook-ceph-osd-prepare-node3-w4xyz 0/2 Completed 0 60srook-discover-dhkb8 1/1 Running 0 140sTo verify that the cluster is in a healthy state, connect to the Rook toolbox and run the ceph status command.
- All mons should be in quorum
- A
mgrshould be active - At least one OSD should be active
- If the health is not
HEALTH_OK, the warnings or errors should be investigated
$ ceph status cluster: id: a0452c76-30d9-4c1a-a948-5d8405f19a7c health: HEALTH_OK services: mon: 3 daemons, quorum a,b,c (age 3m) mgr: a(active, since 2m) osd: 3 osds: 3 up (since 1m), 3 in (since 1m)...Create a Block Storage
Block storage allows a single pod to mount storage. This guide shows how to create a simple, multi-tier web application on Kubernetes using persistent volumes enabled by Rook.
Prerequisites
This guide assumes a Rook cluster as explained in the Quickstart.
Provision Storage
Before Rook can provision storage, a StorageClass and CephBlockPool need to be created. This will allow Kubernetes to interoperate with Rook when provisioning persistent volumes.
Save this StorageClass definition as storageclass.yaml:
apiVersion: ceph.rook.io/v1kind: CephBlockPoolmetadata: name: replicapool namespace: rook-cephspec: failureDomain: host replicated: size: 3---apiVersion: storage.k8s.io/v1kind: StorageClassmetadata: name: rook-ceph-block# Change "rook-ceph" provisioner prefix to match the operator namespace if neededprovisioner: rook-ceph.rbd.csi.ceph.comparameters: # clusterID is the namespace where the rook cluster is running clusterID: rook-ceph # Ceph pool into which the RBD image shall be created pool: replicapool # RBD image format. Defaults to "2". imageFormat: "2" # RBD image features. Available for imageFormat: "2". CSI RBD currently supports only `layering` feature. imageFeatures: layering # The secrets contain Ceph admin credentials. csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # Specify the filesystem type of the volume. If not specified, csi-provisioner # will set default as `ext4`. csi.storage.k8s.io/fstype: xfs# Delete the rbd volume when a PVC is deletedreclaimPolicy: DeleteIf you’ve deployed the Rook operator in a namespace other than “rook-ceph” as is common change the prefix in the provisioner to match the namespace you used. For example, if the Rook operator is running in “rook-op” the provisioner value should be “rook-op.rbd.csi.ceph.com”.
Create the storage class.
kubectl create -f cluster/examples/kubernetes/ceph/csi/rbd/storageclass.yamlConsume the storage: WordPress sample
We create a sample app to consume the block storage provisioned by Rook with the classic WordPress and Mysql apps. Both of these apps will make use of block volumes provisioned by Rook.
Start Mysql and WordPress from the cluster/examples/kubernetes folder:
kubectl create -f mysql.yamlkubectl create -f wordpress.yamlBoth of these apps create a block volume and mount it to their respective pod. You can see the Kubernetes volume claims by running the following:
$ kubectl get pvcNAME STATUS VOLUME CAPACITY ACCESSMODES AGEmysql-pv-claim Bound pvc-95402dbc-efc0-11e6-bc9a-0cc47a3459ee 20Gi RWO 1mwp-pv-claim Bound pvc-39e43169-efc1-11e6-bc9a-0cc47a3459ee 20Gi RWO 1mOnce the WordPress and Mysql pods are in the Running state, get the cluster IP of the WordPress app, and enter it in your browser:
$ kubectl get svc wordpressNAME CLUSTER-IP EXTERNAL-IP PORT(S) AGEwordpress 10.3.0.155 <pending> 80:30841/TCP 2mYou should see the WordPress app running.
If you are using Minikube, the WordPress URL can be retrieved with this one-line command:
echo http://$(minikube ip):$(kubectl get service wordpress -o jsonpath='{.spec.ports[0].nodePort}')NOTE: When running in a vagrant environment, there will be no external IP address to reach WordPress with. You will only be able to reach WordPress via the CLUSTER-IP from inside the Kubernetes cluster.
Moving On
Now that you’ve had a chance to play around a bit with using Rook with Ceph, let’s move on to the next part and learn how to set up Minio object storage with Rook!
Related articles

Cloud computing: types, deployment models, benefits, and how it works
Cloud computing is a model for enabling on-demand network access to a shared pool of configurable computing resources, such as networks, servers, storage, applications, and services that can be rapidly provisioned and released with minimal management effort or service provider interaction. According to research by Gartner (2024), the global cloud computing market size is projected to reach $1.25 trillion by 2025, reflecting the rapid growth and widespread adoption of these services.The National Institute of Standards and Technology (NIST) defines five core characteristics that distinguish cloud computing from traditional IT infrastructure. These include on-demand self-service, broad network access, resource pooling, rapid elasticity, and measured service.Each characteristic addresses specific business needs while enabling organizations to access computing resources without maintaining physical hardware on-premises.Cloud computing services are organized into three main categories that serve different business requirements and technical needs. Infrastructure as a Service (IaaS) provides basic computing resources, Platform as a Service (PaaS) offers development environments and tools, and Software as a Service (SaaS) delivers complete applications over the internet. Major cloud providers typically guarantee 99.9% or higher uptime in service level agreements to ensure reliable access to these services.Organizations can choose from four primary use models based on their security, compliance, and operational requirements. Public cloud services are offered over the internet to anyone, private clouds are proprietary networks serving limited users, hybrid clouds combine public and private cloud features, and community clouds serve specific groups with shared concerns. Each model provides different levels of control, security, and cost structures.Over 90% of enterprises use some form of cloud services as of 2024, according to Forrester Research (2024), making cloud computing knowledge important for modern business operations. This widespread adoption reflects how cloud computing has become a cornerstone of digital change and competitive advantage across industries.What is cloud computing?Cloud computing is a model that delivers computing resources like servers, storage, databases, and software over the internet on demand, allowing users to access and use these resources without owning or managing the physical infrastructure. Instead of buying and maintaining your own servers, you can rent computing power from cloud providers and scale resources up or down based on your needs.Over 90% of enterprises now use some form of cloud services, with providers typically guaranteeing 99.9% or higher uptime in their service agreements.The three main service models offer different levels of control and management. Infrastructure as a Service (IaaS) provides basic computing resources like virtual machines and storage. Platform as a Service (PaaS) adds development tools and runtime environments, and Software as a Service (SaaS) delivers complete applications that are ready to use. Each model handles different aspects of the technology stack, so you only manage what you need while the provider handles the rest.Cloud use models vary by ownership and access control. Public clouds serve multiple customers over the internet, private clouds operate exclusively for one organization, and hybrid clouds combine both approaches for flexibility. This variety lets organizations choose the right balance of cost, control, and security for their specific needs while maintaining the core benefits of cloud computing's flexible, elastic infrastructure.What are the main types of cloud computing services?The main types of cloud computing services refer to the different service models that provide computing resources over the internet with varying levels of management and control. The main types of cloud computing services are listed below.Infrastructure as a service (IaaS): This model provides basic computing infrastructure, including virtual machines, storage, and networking resources over the internet. Users can install and manage their own operating systems, applications, and development frameworks while the provider handles the physical hardware.Platform as a service (PaaS): This service offers a complete development and use environment in the cloud, including operating systems, programming languages, databases, and web servers. Developers can build, test, and use applications without managing the underlying infrastructure complexity.Software as a service (SaaS): This model delivers fully functional software applications over the internet through a web browser or mobile app. Users access the software on a subscription basis without needing to install, maintain, or update the applications locally.Function as a service (FaaS): Also known as serverless computing, this model allows developers to run individual functions or pieces of code in response to events. The cloud provider automatically manages server provisioning, scaling, and maintenance while charging only for actual compute time used.Database as a service (DBaaS): This service provides managed database solutions in the cloud, handling database administration tasks like backups, updates, and scaling. Organizations can access database functionality without maintaining physical database servers or hiring specialized database administrators.Storage as a service (STaaS): This model offers flexible cloud storage solutions for data backup, archiving, and file sharing needs. Users can store and retrieve data from anywhere with internet access while paying only for the storage space they actually use.What are the different cloud deployment models?Cloud use models refer to the different ways organizations can access and manage cloud computing resources based on ownership, location, and access control. The cloud use models are listed below.Public cloud: Services are delivered over the internet and shared among multiple organizations by third-party providers. Anyone can purchase and use these services on a pay-as-you-go basis, making them cost-effective for businesses without large upfront investments.Private cloud: Computing resources are dedicated to a single organization and can be hosted on-premises or by a third party. This model offers greater control, security, and customization options but requires higher costs and more management overhead.Hybrid cloud: Organizations combine public and private cloud environments, allowing data and applications to move between them as needed. This approach provides flexibility to keep sensitive data in private clouds while using public clouds for less critical workloads.Community cloud: Multiple organizations with similar requirements share cloud infrastructure and costs. Government agencies, healthcare organizations, or financial institutions often use this model to meet specific compliance and security standards.Multi-cloud: Organizations use services from multiple cloud providers to avoid vendor lock-in and improve redundancy. This plan allows businesses to choose the best services from different providers while reducing dependency on any single vendor.How does cloud computing work?Cloud computing works by delivering computing resources like servers, storage, databases, and software over the internet on an on-demand basis. Instead of owning physical hardware, users access these resources through web browsers or applications, while cloud providers manage the underlying infrastructure in data centers worldwide.The system operates through a front-end and back-end architecture. The front end includes your device, web browser, and network connection that you use to access cloud services.The back end consists of servers, storage systems, databases, and applications housed in the provider's data centers. When you request a service, the cloud infrastructure automatically allocates the necessary resources from its shared pool.The technology achieves its flexibility through virtualization, which creates multiple virtual instances from single physical servers. Resource pooling allows providers to serve multiple customers from the same infrastructure, while rapid elasticity automatically scales resources up or down based on demand.This elastic scaling can reduce resource costs by up to 30% compared to fixed infrastructure, according to McKinsey (2024), making cloud computing both flexible and cost-effective for businesses of all sizes.What are the key benefits of cloud computing?The key benefits of cloud computing refer to the advantages organizations and individuals gain from using internet-based computing services instead of traditional on-premises infrastructure. The key benefits of cloud computing are listed below.Cost reduction: Organizations eliminate upfront hardware investments and reduce ongoing maintenance expenses by paying only for resources they actually use. Cloud providers handle infrastructure management, reducing IT staffing costs and operational overhead.Flexibility and elasticity: Computing resources can expand or contract automatically based on demand, ensuring best performance during traffic spikes. This flexibility prevents over-provisioning during quiet periods and under-provisioning during peak usage.Improved accessibility: Users can access applications and data from any device with an internet connection, enabling remote work and global collaboration. This mobility supports modern work patterns and increases productivity across distributed teams.Enhanced reliability: Cloud providers maintain multiple data centers with redundant systems and backup infrastructure to ensure continuous service availability.Automatic updates and maintenance: Software updates, security patches, and system maintenance happen automatically without user intervention. This automation reduces downtime and ensures systems stay current with the latest features and security protections.Disaster recovery: Cloud services include built-in backup and recovery capabilities that protect against data loss from hardware failures or natural disasters. Recovery times are typically faster than traditional backup methods since data exists across multiple locations.Environmental effectiveness: Shared cloud infrastructure uses resources more effectively than individual company data centers, reducing overall energy consumption. Large cloud providers can achieve better energy effectiveness through economies of scale and advanced cooling technologies.What are the drawbacks and challenges of cloud computing?The drawbacks and challenges of cloud computing refer to the potential problems and limitations organizations may face when adopting cloud-based services. They are listed below.Security concerns: Organizations lose direct control over their data when it's stored on third-party servers. Data breaches, unauthorized access, and compliance issues become shared responsibilities between the provider and customer. Sensitive information may be vulnerable to cyber attacks targeting cloud infrastructure.Internet dependency: Cloud services require stable internet connections to function properly. Poor connectivity or outages can completely disrupt business operations and prevent access to critical applications. Remote locations with limited bandwidth face particular challenges accessing cloud resources.Vendor lock-in: Switching between cloud providers can be difficult and expensive due to proprietary technologies and data formats. Organizations may become dependent on specific platforms, limiting their flexibility to negotiate pricing or change services. Migration costs and technical complexity often discourage switching providers.Limited customization: Cloud services offer standardized solutions that may not meet specific business requirements. Organizations can't modify underlying infrastructure or install custom software configurations. This restriction can force businesses to adapt their processes to fit the cloud platform's limitations.Ongoing costs: Monthly subscription fees can accumulate to exceed traditional on-premise infrastructure costs over time. Unexpected usage spikes or data transfer charges can lead to budget overruns. Organizations lose the asset value that comes with owning physical hardware.Performance variability: Shared cloud resources can experience slower performance during peak usage periods. Network latency affects applications requiring real-time processing or frequent data transfers. Organizations can't guarantee consistent performance levels for mission-critical applications.Compliance complexity: Meeting regulatory requirements becomes more challenging when data is stored across multiple locations. Organizations must verify that cloud providers meet industry-specific compliance standards. Audit trails and data governance become shared responsibilities that require careful coordination.Gcore Edge CloudWhen building AI applications that require serious computational power, the infrastructure you choose can make or break your project's success. Whether you're training large language models, running complex inference workloads, or tackling high-performance computing challenges, having access to the latest GPU technology without performance bottlenecks becomes critical.Gcore's AI GPU Cloud Infrastructure addresses these demanding requirements with bare metal NVIDIA H200. H100. A100. L40S, and GB200 GPUs, delivering zero virtualization overhead for maximum performance. The platform's ultra-fast InfiniBand networking and multi-GPU cluster support make it particularly well-suited for distributed training and large-scale AI workloads, starting from just €1.25/hour. Multi-instance GPU (MIG) support also allows you to improve resource allocation and costs for smaller inference tasks.Discover how Gcore's bare metal GPU performance can accelerate your AI training and inference workloads at https://gcore.com/gpu-cloud.Frequently asked questionsPeople often have questions about cloud computing basics, costs, and how it fits their specific needs. These answers cover the key service models, use options, and practical considerations that help clarify what cloud computing can do for your organization.What's the difference between cloud computing and traditional hosting?Cloud computing delivers resources over the internet on demand, while traditional hosting provides fixed server resources at dedicated locations. Cloud offers elastic growth and pay-as-you-go pricing, whereas traditional hosting requires upfront capacity planning and fixed costs regardless of actual usage.What is cloud computing security?Cloud computing security protects data, applications, and infrastructure in cloud environments through shared responsibility models between providers and users. Cloud providers secure the underlying infrastructure while users protect their data, applications, and access controls.What is virtualization in cloud computing?Virtualization in cloud computing creates multiple virtual machines (VMs) on a single physical server using hypervisor software that separates computing resources. This technology allows cloud providers to increase hardware effectiveness and offer flexible, isolated environments to multiple users simultaneously.Is cloud computing secure for business data?Yes, cloud computing is secure for business data when proper security measures are in place, with major providers offering encryption, access controls, and compliance certifications that often exceed what most businesses can achieve on-premises. Cloud service providers typically guarantee 99.9% or higher uptime in service level agreements while maintaining enterprise-grade security standards.How much does cloud computing cost compared to on-premises infrastructure?Cloud computing typically costs 20-40% less than on-premises infrastructure due to shared resources, reduced hardware purchases, and lower maintenance expenses, according to IDC (2024). However, costs vary primarily based on usage patterns, with predictable workloads sometimes being cheaper on-premises while variable workloads benefit more from cloud's pay-as-you-go model.How do I choose between IaaS, PaaS, and SaaS?Choose based on your control needs. IaaS gives you full infrastructure control, PaaS handles infrastructure so you focus on development, and SaaS provides ready-to-use applications with no technical management required.

Pre-configure your dev environment with Gcore VM init scripts
Provisioning new cloud instances can be repetitive and time-consuming if you’re doing everything manually: installing packages, configuring environments, copying SSH keys, and more. With cloud-init, you can automate these tasks and launch development-ready instances from the start.Gcore Edge Cloud VMs support cloud-init out of the box. With a simple YAML script, you can automatically set up a development-ready instance at boot, whether you’re launching a single machine or spinning up a fleet.In this guide, we’ll walk through how to use cloud-init on Gcore Edge Cloud to:Set a passwordInstall packages and system updatesAdd users and SSH keysMount disks and write filesRegister services or install tooling like Docker or Node.jsLet’s get started.What is cloud-init?cloud-init is a widely used tool for customizing cloud instances during the first boot. It reads user-provided configuration data—usually YAML—and uses it to run commands, install packages, and configure the system. In this article, we will focus on Linux-based virtual machines.How to use cloud-init on GcoreFor Gcore Cloud VMs, cloud-init scripts are added during instance creation using the User data field in the UI or API.Step 1: Create a basic scriptStart with a simple YAML script. Here’s one that updates packages and installs htop:#cloud-config package_update: true packages: - htop Step 2: Launch a new VM with your scriptGo to the Gcore Customer Portal, navigate to VMs, and start creating a new instance (or just click here). When you reach the Additional options section, enable the User data option. Then, paste in your YAML cloud-init script.Once the VM boots, it will automatically run the script. This works the same way for all supported Linux distributions available through Gcore.3 real-world examplesLet’s look at three examples of how you can use this.Example 1: Add a password for a specific userThe below script sets the for the default user of the selected operating system:#cloud-config password: <password> chpasswd: {expire: False} ssh_pwauth: True Example 2: Dev environment with Docker and GitThe following script does the following:Installs Docker and GitAdds a new user devuser with sudo privilegesAuthorizes an SSH keyStarts Docker at boot#cloud-config package_update: true packages: - docker.io - git users: - default - name: devuser sudo: ALL=(ALL) NOPASSWD:ALL groups: docker shell: /bin/bash ssh-authorized-keys: - ssh-rsa AAAAB3Nza...your-key-here runcmd: - systemctl enable docker - systemctl start docker Example 3: Install Node.js and clone a repoThis script installs Node.js and clones a GitHub repo to your Gcore VM at launch:#cloud-config packages: - curl runcmd: - curl -fsSL https://deb.nodesource.com/setup_18.x | bash - - apt-get install -y nodejs - git clone https://github.com/example-user/dev-project.git /home/devuser/project Reusing and versioning your scriptsTo avoid reinventing the wheel, keep your cloud-init scripts:In version control (e.g., Git)Templated for different environments (e.g., dev vs staging)Modular so you can reuse base blocks across projectsYou can also use tools like Ansible or Terraform with cloud-init blocks to standardize provisioning across your team or multiple Gcore VM environments.Debugging cloud-initIf your script doesn’t behave as expected, SSH into the instance and check the cloud-init logs:sudo cat /var/log/cloud-init-output.log This file shows each command as it ran and any errors that occurred.Other helpful logs:/var/log/cloud-init.log /var/lib/cloud/instance/user-data.txt Pro tip: Echo commands or write log files in your script to help debug tricky setups—especially useful if you’re automating multi-node workflows across Gcore Cloud.Tips and best practicesIndentation matters! YAML is picky. Use spaces, not tabs.Always start the file with #cloud-config.runcmd is for commands that run at the end of boot.Use write_files to write configs, env variables, or secrets.Cloud-init scripts only run on the first boot. To re-run, you’ll need to manually trigger cloud-init or re-create the VM.Automate it all with GcoreIf you're provisioning manually, you're doing it wrong. Cloud-init lets you treat your VM setup as code: portable, repeatable, and testable. Whether you’re spinning up ephemeral dev boxes or preparing staging environments, Gcore’s support for cloud-init means you can automate it all.For more on managing virtual machines with Gcore, check out our product documentation.Explore Gcore VM product docs

How to cut egress costs and speed up delivery using Gcore CDN and Object Storage
If you’re serving static assets (images, videos, scripts, downloads) from object storage, you’re probably paying more than you need to, and your users may be waiting longer than they should.In this guide, we explain how to front your bucket with Gcore CDN to cache static assets, cut egress bandwidth costs, and get faster TTFB globally. We’ll walk through setup (public or private buckets), signed URL support, cache control best practices, debugging tips, and automation with the Gcore API or Terraform.Why bother?Serving directly from object storage hits your origin for every request and racks up egress charges. With a CDN in front, cached files are served from edge—faster for users, and cheaper for you.Lower TTFB, better UXWhen content is cached at the edge, it doesn’t have to travel across the planet to get to your user. Gcore CDN caches your assets at PoPs close to end users, so requests don’t hit origin unless necessary. Once cached, assets are delivered in a few milliseconds.Lower billsMost object storage providers charge $80–$120 per TB in egress fees. By fronting your storage with a CDN, you only pay egress once per edge location—then it’s all cache hits after that. If you’re using Gcore Storage and Gcore CDN, there’s zero egress fee between the two.Caching isn’t the only way you save. Gcore CDN can also compress eligible file types (like HTML, CSS, JavaScript, and JSON) on the fly, further shrinking bandwidth usage and speeding up file delivery—all without any changes to your storage setup.Less origin traffic and less data to transfer means smaller bills. And your storage bucket doesn’t get slammed under load during traffic spikes.Simple scaling, globallyThe CDN takes the hit, not your bucket. That means fewer rate-limit issues, smoother traffic spikes, and more reliable performance globally. Gcore CDN spans the globe, so you’re good whether your users are in Tokyo, Toronto, or Tel Aviv.Setup guide: Gcore CDN + Gcore Object StorageLet’s walk through configuring Gcore CDN to cache content from a storage bucket. This works with Gcore Object Storage and other S3-compatible services.Step 1: Prep your bucketPublic? Check files are publicly readable (via ACL or bucket policy).Private? Use Gcore’s AWS Signature V4 support—have your access key, secret, region, and bucket name ready.Gcore Object Storage URL format: https://<bucket-name>.<region>.cloud.gcore.lu/<object> Step 2: Create CDN resource (UI or API)In the Gcore Customer Portal:Go to CDN > Create CDN ResourceChoose "Accelerate and protect static assets"Set a CNAME (e.g. cdn.yoursite.com) if you want to use your domainConfigure origin:Public bucket: Choose None for authPrivate bucket: Choose AWS Signature V4, and enter credentialsChoose HTTPS as the origin protocolGcore will assign a *.gcdn.co domain. If you’re using a custom domain, add a CNAME: cdn.yoursite.com CNAME .gcdn.co Here’s how it works via Terraform: resource "gcore_cdn_resource" "cdn" { cname = "cdn.yoursite.com" origin_group_id = gcore_cdn_origingroup.origin.id origin_protocol = "HTTPS" } resource "gcore_cdn_origingroup" "origin" { name = "my-origin-group" origin { source = "mybucket.eu-west.cloud.gcore.lu" enabled = true } } Step 3: Set caching behaviorSet Cache-Control headers in your object metadata: Cache-Control: public, max-age=2592000 Too messy to handle in storage? Override cache logic in Gcore:Force TTLs by path or extensionIgnore or forward query strings in cache keyStrip cookies (if unnecessary for cache decisions)Pro tip: Use versioned file paths (/img/logo.v3.png) to bust cache safely.Secure access with signed URLsWant your assets to be private, but still edge-cacheable? Use Gcore’s Secure Token feature:Enable Secure Token in CDN settingsSet a secret keyGenerate time-limited tokens in your appPython example: import base64, hashlib, time secret = 'your_secret' path = '/videos/demo.mp4' expires = int(time.time()) + 3600 string = f"{expires}{path} {secret}" token = base64.urlsafe_b64encode(hashlib.md5(string.encode()).digest()).decode().strip('=') url = f"https://cdn.yoursite.com{path}?md5={token}&expires={expires}" Signed URLs are verified at the CDN edge. Invalid or expired? Blocked before origin is touched.Optional: Bind the token to an IP to prevent link sharing.Debug and cache tuneUse curl or browser devtools: curl -I https://cdn.yoursite.com/img/logo.png Look for:Cache: HIT or MISSCache-ControlX-Cached-SinceCache not working? Check for the following errors:Origin doesn’t return Cache-ControlCDN override TTL not appliedCache key includes query strings unintentionallyYou can trigger purges from the Gcore Customer Portal or automate them via the API using POST /cdn/purge. Choose one of three ways:Purge all: Clear the entire domain’s cache at once.Purge by URL: Target a specific full path (e.g., /images/logo.png).Purge by pattern: Target a set of files using a wildcard at the end of the pattern (e.g., /videos/*).Monitor and optimize at scaleAfter rollout:Watch origin bandwidth dropCheck hit ratio (aim for >90%)Audit latency (TTFB on HIT vs MISS)Consider logging using Gcore’s CDN logs uploader to analyze cache behavior, top requested paths, or cache churn rates.For maximum savings, combine Gcore Object Storage with Gcore CDN: egress traffic between them is 100% free. That means you can serve cached assets globally without paying a cent in bandwidth fees.Using external storage? You’ll still slash egress costs by caching at the edge and cutting direct origin traffic—but you’ll unlock the biggest savings when you stay inside the Gcore ecosystem.Save money and boost performance with GcoreStill serving assets direct from storage? You’re probably wasting money and compromising performance on the table. Front your bucket with Gcore CDN. Set smart cache headers or use overrides. Enable signed URLs if you need control. Monitor cache HITs and purge when needed. Automate the setup with Terraform. Done.Next steps:Create your CDN resourceUse private object storage with Signature V4Secure your CDN with signed URLsCreate a free CDN resource now
Bare metal vs. virtual machines: performance, cost, and use case comparison
Choosing the right type of server infrastructure is critical to how your application performs, scales, and fits your budget. For most workloads, the decision comes down to two core options: bare metal servers and cloud virtual machines (VMs). Both can be deployed in the cloud, but they differ significantly in terms of performance, control, scalability, and cost.In this article, we break down the core differences between bare metal and virtual servers, highlight when to choose each, and explain how Gcore can help you deploy the right infrastructure for your needs. If you want to learn about either BM or VMs in detail, we’ve got articles for those: here’s the one for bare metal, and here’s a deep dive into virtual machines.Bare metal vs. virtual machines at a glanceWhen evaluating whether bare metal or virtual machines are right for your company, consider your specific workload requirements, performance priorities, and business objectives. Here’s a quick breakdown to help you decide what works best for you.FactorBare metal serversVirtual machinesPerformanceDedicated resources; ideal for high-performance workloadsShared resources; suitable for moderate or variable workloadsScalabilityOften requires manual scaling; less flexibleHighly elastic; easy to scale up or downCustomizationFull control over hardware, OS, and configurationLimited by hypervisor and provider’s environmentSecurityIsolated by default; no hypervisor layerShared environment with strong isolation protocolsCostHigher upfront cost; dedicated hardwarePay-as-you-go pricing; cost-effective for flexible workloadsBest forHPC, AI/ML, compliance-heavy workloadsStartups, dev/test, fast-scaling applicationsAll about bare metal serversA bare metal server is a single-tenant physical server rented from a cloud provider. Unlike virtual servers, the hardware is not shared with other users, giving you full access to all resources and deeper control over configurations. You get exclusive access and control over the hardware via the cloud provider, which offers the stability and security needed for high-demand applications.The benefits of bare metal serversHere are some of the business advantages of opting for a bare metal server:Maximized performance: Because they are dedicated resources, bare metal servers provide top-tier performance without sharing processing power, memory, or storage with other users. This makes them ideal for resource-intensive applications like high-performance computing (HPC), big data processing, and game hosting.Greater control: Since you have direct access to the hardware, you can customize the server to meet your specific requirements. This is especially important for businesses with complex, specialized needs that require fine-tuned configurations.High security: Bare metal servers offer a higher level of security than their alternatives due to the absence of virtualization. With no shared resources or hypervisor layer, there’s less risk of vulnerabilities that come with multi-tenant environments.Dedicated resources: Because you aren’t sharing the server with other users, all server resources are dedicated to your application so that you consistently get the performance you need.Who should use bare metal servers?Here are examples of instances where bare metal servers are the best option for a business:High-performance computing (HPC)Big data processing and analyticsResource-intensive applications, such as AI/ML workloadsGame and video streaming serversBusinesses requiring enhanced security and complianceAll about virtual machinesA virtual server (or virtual machine) runs on top of a physical server that’s been partitioned by a cloud provider using a hypervisor. This allows multiple VMs to share the same hardware while remaining isolated from each other.Unlike bare metal servers, virtual machines share the underlying hardware with other cloud provider customers. That means you’re using (and paying for) part of one server, providing cost efficiency and flexibility.The benefits of virtual machinesHere are some advantages of using a shared virtual machine:Scalability: Virtual machines are ideal for businesses that need to scale quickly and are starting at a small scale. With cloud-based virtualization, you can adjust your server resources (CPU, memory, storage) on demand to match changing workloads.Cost efficiency: You pay only for the resources you use with VMs, making them cost-effective for companies with fluctuating resource needs, as there is no need to pay for unused capacity.Faster deployment: VMs can be provisioned quickly and easily, which makes them ideal for anyone who wants to deploy new services or applications fast.Who should use virtual machines?VMs are a great fit for the following:Web hosting and application hostingDevelopment and testing environmentsRunning multiple apps with varying demandsStartups and growing businesses requiring scalabilityBusinesses seeking cost-effective, flexible solutionsWhich should you choose?There’s no one-size-fits-all answer. Your choice should depend on the needs of your workload:Choose bare metal if you need dedicated performance, low-latency access to hardware, or tighter control over security and compliance.Choose virtual servers if your priority is flexible scaling, faster deployment, and optimized cost.If your application uses GPU-based inference or AI training, check out our dedicated guide to VM vs. BM for AI workloads.Get started with Gcore BM or VMs todayAt Gcore, we provide both bare metal and virtual machine solutions, offering flexibility, performance, and reliability to meet your business needs. Gcore Bare Metal has the power and reliability needed for demanding workloads, while online virtual machines offers customizable configurations, free egress traffic, and flexibility.Compare Gcore BM and VM pricing now
Optimize your workload: a guide to selecting the best virtual machine configuration
Virtual machines (VMs) offer the flexibility, scalability, and cost-efficiency that businesses need to optimize workloads. However, choosing the wrong setup can lead to poor performance, wasted resources, and unnecessary costs.In this guide, we’ll walk you through the essential factors to consider when selecting the best virtual machine configuration for your specific workload needs.﹟1 Understand your workload requirementsThe first step in choosing the right virtual machine configuration is understanding the nature of your workload. Workloads can range from light, everyday tasks to resource-intensive applications. When making your decision, consider the following:Compute-intensive workloads: Applications like video rendering, scientific simulations, and data analysis require a higher number of CPU cores. Opt for VMs with multiple processors or CPUs for smoother performance.Memory-intensive workloads: Databases, big data analytics, and high-performance computing (HPC) jobs often need more RAM. Choose a VM configuration that provides sufficient memory to avoid memory bottlenecks.Storage-intensive workloads: If your workload relies heavily on storage, such as file servers or applications requiring frequent read/write operations, prioritize VM configurations that offer high-speed storage options, such as SSDs or NVMe.I/O-intensive workloads: Applications that require frequent network or disk I/O, such as cloud services and distributed applications, benefit from VMs with high-bandwidth and low-latency network interfaces.﹟2 Consider VM size and scalabilityOnce you understand your workload’s requirements, the next step is to choose the right VM size. VM sizes are typically categorized by the amount of CPU, memory, and storage they offer.Start with a baseline: Select a VM configuration that offers a balanced ratio of CPU, RAM, and storage based on your workload type.Scalability: Choose a VM size that allows you to easily scale up or down as your needs change. Many cloud providers offer auto-scaling capabilities that adjust your VM’s resources based on real-time demand, providing flexibility and cost savings.Overprovisioning vs. underprovisioning: Avoid overprovisioning (allocating excessive resources) unless your workload demands peak capacity at all times, as this can lead to unnecessary costs. Similarly, underprovisioning can affect performance, so finding the right balance is essential.﹟3 Evaluate CPU and memory considerationsThe central processing unit (CPU) and memory (RAM) are the heart of a virtual machine. The configuration of both plays a significant role in performance. Workloads that need high processing power, such as video encoding, machine learning, or simulations, will benefit from VMs with multiple CPU cores. However, be mindful of CPU architecture—look for VMs that offer the latest processors (e.g., Intel Xeon, AMD EPYC) for better performance per core.It’s also important that the VM has enough memory to avoid paging, which occurs when the system uses disk space as virtual memory, significantly slowing down performance. Consider a configuration with more RAM and support for faster memory types like DDR4 for memory-heavy applications.﹟4 Assess storage performance and capacityStorage performance and capacity can significantly impact the performance of your virtual machine, especially for applications requiring large data volumes. Key considerations include:Disk type: For faster read/write operations, opt for solid-state drives (SSDs) over traditional hard disk drives (HDDs). Some cloud providers also offer NVMe storage, which can provide even greater speed for highly demanding workloads.Disk size: Choose the right size based on the amount of data you need to store and process. Over-allocating storage space might seem like a safe bet, but it can also increase costs unnecessarily. You can always resize disks later, so avoid over-allocating them upfront.IOPS and throughput: Some workloads require high input/output operations per second (IOPS). If this is a priority for your workload (e.g., databases), make sure that your VM configuration includes high IOPS storage options.﹟5 Weigh up your network requirementsWhen working with cloud-based VMs, network performance is a critical consideration. High-speed and low-latency networking can make a difference for applications such as online gaming, video conferencing, and real-time analytics.Bandwidth: Check whether the VM configuration offers the necessary bandwidth for your workload. For applications that handle large data transfers, such as cloud backup or file servers, make sure that the network interface provides high throughput.Network latency: Low latency is crucial for applications where real-time performance is key (e.g., trading systems, gaming). Choose VMs with low-latency networking options to minimize delays and improve the user experience.Network isolation and security: Check if your VM configuration provides the necessary network isolation and security features, especially when handling sensitive data or operating in multi-tenant environments.﹟6 Factor in cost considerationsWhile it’s essential that your VM has the right configuration, cost is always an important factor to consider. Cloud providers typically charge based on the resources allocated, so optimizing for cost efficiency can significantly impact your budget.Consider whether a pay-as-you-go or reserved model (which offers discounted rates in exchange for a long-term commitment) fits your usage pattern. The reserved option can provide significant savings if your workload runs continuously. You can also use monitoring tools to track your VM’s performance and resource usage over time. This data will help you make informed decisions about scaling up or down so you’re not paying for unused resources.﹟7 Evaluate security featuresSecurity is a primary concern when selecting a VM configuration, especially for workloads handling sensitive data. Consider the following:Built-in security: Look for VMs that offer integrated security features such as DDoS protection, WAAP security, and encryption.Compliance: Check that the VM configuration meets industry standards and regulations, such as GDPR, ISO 27001, and PCI DSS.Network security: Evaluate the VM's network isolation capabilities and the availability of cloud firewalls to manage incoming and outgoing traffic.﹟8 Consider geographic locationThe geographic location of your VM can impact latency and compliance. Therefore, it’s a good idea to choose VM locations that are geographically close to your end users to minimize latency and improve performance. In addition, it’s essential to select VM locations that comply with local data sovereignty laws and regulations.﹟9 Assess backup and recovery optionsBackup and recovery are critical for maintaining data integrity and availability. Look for VMs that offer automated backup solutions so that data is regularly saved. You should also evaluate disaster recovery capabilities, including the ability to quickly restore data and applications in case of failure.﹟10 Test and iterateFinally, once you've chosen a VM configuration, testing its performance under real-world conditions is essential. Most cloud providers offer performance monitoring tools that allow you to assess how well your VM is meeting your workload requirements.If you notice any performance bottlenecks, be prepared to adjust the configuration. This could involve increasing CPU cores, adding more memory, or upgrading storage. Regular testing and fine-tuning means that your VM is always optimized.Choosing a virtual machine that suits your requirementsSelecting the best virtual machine configuration is a key step toward optimizing your workloads efficiently, cost-effectively, and without unnecessary performance bottlenecks. By understanding your workload’s needs, considering factors like CPU, memory, storage, and network performance, and continuously monitoring resource usage, you can make informed decisions that lead to better outcomes and savings.Whether you're running a small application or large-scale enterprise software, the right VM configuration can significantly improve performance and cost. Gcore provides flexible online virtual machine options that can meet your unique requirements. Our virtual machines are designed to meet diverse workload requirements, providing dedicated vCPUs, high-speed storage, and low-latency networking across 30+ global regions. You can scale compute resources on demand, benefit from free egress traffic, and enjoy flexible pricing models by paying only for the resources in use, maximizing the value of your cloud investments.Contact us to discuss your VM needs

How to get the size of a directory in Linux
Understanding how to check directory size in Linux is critical for managing storage space efficiently. Understanding this process is essential whether you’re assessing specific folder space or preventing storage issues.This comprehensive guide covers commands and tools so you can easily calculate and analyze directory sizes in a Linux environment. We will guide you step-by-step through three methods: du, ncdu, and ls -la. They’re all effective and each offers different benefits.What is a Linux directory?A Linux directory is a special type of file that functions as a container for storing files and subdirectories. It plays a key role in organizing the Linux file system by creating a hierarchical structure. This arrangement simplifies file management, making it easier to locate, access, and organize related files. Directories are fundamental components that help ensure smooth system operations by maintaining order and facilitating seamless file access in Linux environments.#1 Get Linux directory size using the du commandUsing the du command, you can easily determine a directory’s size by displaying the disk space used by files and directories. The output can be customized to be presented in human-readable formats like kilobytes (KB), megabytes (MB), or gigabytes (GB).Check the size of a specific directory in LinuxTo get the size of a specific directory, open your terminal and type the following command:du -sh /path/to/directoryIn this command, replace /path/to/directory with the actual path of the directory you want to assess. The -s flag stands for “summary” and will only display the total size of the specified directory. The -h flag makes the output human-readable, showing sizes in a more understandable format.Example: Here, we used the path /home/ubuntu/, where ubuntu is the name of our username directory. We used the du command to retrieve an output of 32K for this directory, indicating a size of 32 KB.Check the size of all directories in LinuxTo get the size of all files and directories within the current directory, use the following command:sudo du -h /path/to/directoryExample: In this instance, we again used the path /home/ubuntu/, with ubuntu representing our username directory. Using the command du -h, we obtained an output listing all files and directories within that particular path.#2 Get Linux directory size using ncduIf you’re looking for a more interactive and feature-rich approach to exploring directory sizes, consider using the ncdu (NCurses Disk Usage) tool. ncdu provides a visual representation of disk usage and allows you to navigate through directories, view size details, and identify large files with ease.For Debian or Ubuntu, use this command:sudo apt-get install ncduOnce installed, run ncdu followed by the path to the directory you want to analyze:ncdu /path/to/directoryThis will launch the ncdu interface, which shows a breakdown of file and subdirectory sizes. Use the arrow keys to navigate and explore various folders, and press q to exit the tool.Example: Here’s a sample output of using the ncdu command to analyze the home directory. Simply enter the ncdu command and press Enter. The displayed output will look something like this:#3 Get Linux directory size using 1s -1aYou can alternatively opt to use the ls command to list the files and directories within a directory. The options -l and -a modify the default behavior of ls as follows:-l (long listing format)Displays the detailed information for each file and directoryShows file permissions, the number of links, owner, group, file size, the timestamp of the last modification, and the file/directory name-a (all files)Instructs ls to include all files, including hidden files and directoriesIncludes hidden files on Linux that typically have names beginning with a . (dot)ls -la lists all files (including hidden ones) in long format, providing detailed information such as permissions, owner, group, size, and last modification time. This command is especially useful when you want to inspect file attributes or see hidden files and directories.Example: When you enter ls -la command and press Enter, you will see an output similar to this:Each line includes:File type and permissions (e.g., drwxr-xr-x):The first character indicates the file type- for a regular filed for a directoryl for a symbolic linkThe next nine characters are permissions in groups of three (rwx):r = readw = writex = executePermissions are shown for three classes of users: owner, group, and others.Number of links (e.g., 2):For regular files, this usually indicates the number of hard linksFor directories, it often reflects subdirectory links (e.g., the . and .. entries)Owner and group (e.g., user group)File size (e.g., 4096 or 1045 bytes)Modification date and time (e.g., Jan 7 09:34)File name (e.g., .bashrc, notes.txt, Documents):Files or directories that begin with a dot (.) are hidden (e.g., .bashrc)ConclusionThat’s it! You can now determine the size of a directory in Linux. Measuring directory sizes is a crucial skill for efficient storage management. Whether you choose the straightforward du command, use the visual advantages of the ncdu tool, or opt for the versatility of ls -la, this expertise enhances your ability to uphold an organized and efficient Linux environment.Looking to deploy Linux in the cloud? With Gcore Edge Cloud, you can choose from a wide range of pre-configured virtual machines suitable for Linux:Affordable shared compute resources starting from €3.2 per monthDeploy across 50+ cloud regions with dedicated servers for low-latency applicationsSecure apps and data with DDoS protection, WAF, and encryption at no additional costGet started today
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.