
This is the final part of our Kubernetes logging series. In case you missed part 1 you can find it here. In this tutorial, we will learn about configuring Filebeat to run as a DaemonSet in our Kubernetes cluster in order to ship logs to the Elasticsearch backend. We are using Filebeat instead of FluentD or FluentBit because it is an extremely lightweight utility and has a first-class support for Kubernetes. It is best for production-level setups.
1. Deployment Architecture
Filebeat will run as a DaemonSet in our Kubernetes cluster. It will be:
- Deployed in a separate namespace called Logging.
- Pods will be scheduled on both Master nodes and Worker Nodes.
- Master Node pods will forward api-server logs for audit and cluster administration purposes.
- Client Node pods will forward workload related logs for application observability.
2.1 Creating Filebeat ServiceAccount and ClusterRole
Deploy the following manifest to create the required permissions for Filebeat pods.
apiVersion: v1kind: Namespacemetadata: name: logging---apiVersion: v1kind: ServiceAccountmetadata: name: filebeat namespace: logging labels: k8s-app: filebeat---apiVersion: rbac.authorization.k8s.io/v1beta1kind: ClusterRolemetadata: name: filebeat namespace: logging labels: k8s-app: filebeatrules:- apiGroups: [""] # "" indicates the core API group resources: - namespaces - pods verbs: - get - watch - list---apiVersion: rbac.authorization.k8s.io/v1beta1kind: ClusterRoleBindingmetadata: name: filebeat namespace: loggingsubjects:- kind: ServiceAccount name: filebeat namespace: kube-systemroleRef: kind: ClusterRole name: filebeat apiGroup: rbac.authorization.k8s.ioWe should make sure that ClusterRole permissions are as limited as possible from a security point of view. If either of the pod associated with this service account gets compromised then the attacker would not be able to gain access entire cluster or applications running in it.
2.2 Creating Filebeat ConfigMap
Use the following manifest to create a ConfigMap which will be used by Filebeat pods.
apiVersion: v1kind: Namespacemetadata: name: logging---apiVersion: v1kind: ConfigMapmetadata: name: filebeat-config namespace: logging labels: k8s-app: filebeat kubernetes.io/cluster-service: "true"data: filebeat.yml: |- filebeat.config: # inputs: # path: ${path.config}/inputs.d/*.yml # reload.enabled: true modules: path: ${path.config}/modules.d/*.yml reload.enabled: true filebeat.autodiscover: providers: - type: kubernetes hints.enabled: true include_annotations: ["artifact.spinnaker.io/name","ad.datadoghq.com/tags"] include_labels: ["app.kubernetes.io/name"] labels.dedot: true annotations.dedot: true templates: - condition: equals: kubernetes.namespace: myapp #Set the namespace in which your app is running, can add multiple conditions in case of more than 1 namespace. config: - type: docker containers.ids: - "${data.kubernetes.container.id}" multiline: pattern: '^[A-Za-z ]+[0-9]{2} (?:[01]\d|2[0123]):(?:[012345]\d):(?:[012345]\d)'. #Timestamp regex for the app logs. Change it as per format. negate: true match: after - condition: equals: kubernetes.namespace: elasticsearch config: - type: docker containers.ids: - "${data.kubernetes.container.id}" multiline: pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}|^[0-9]{4}-[0-9]{2}-[0-9]{2}T' negate: true match: after processors: - add_cloud_metadata: ~ - drop_fields: when: has_fields: ['kubernetes.labels.app'] fields: - 'kubernetes.labels.app' output.elasticsearch: hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']Important concepts for the Filebeat ConfigMap:
- hints.enabled: This activates Filebeat’s hints module for Kubernetes. By using this we can use pod annotations to pass config directly to Filebeat pod. We can specify different multiline patterns and various other types of config. More about this can be read here.
- include_annotations: Setting this to true enables Filebeat to retain any pod annotation for a particular log entry. These annotations can be later used to filter logs in the Kibana console.
- include_labels: Setting this to true enables Filebeat to retain any pod labels for a particular log entry. These labels can be later used to filter logs in the Kibana console.
- We can also filter logs for a particular namespace and then can process the log entries accordingly. Here docker log processor is used. We can also use different multiline patterns for different namespaces.
- The output is set to Elasticsearch because we are using Elasticsearch as the storage backend. Alternatively, this can also point to Redis, Logstash, Kafka or even a File. More this can be read here.
- Cloud metadata processor includes some host-specific fields in the log entry. This is helpful when we try to filter logs specific to a particular worker node.
2.3 Deploying Filebeat DaemonSet
Use the manifest below to deploy the Filebeat DaemonSet.
apiVersion: v1kind: Namespacemetadata: name: logging---apiVersion: extensions/v1beta1kind: DaemonSetmetadata: name: filebeat namespace: logging labels: k8s-app: filebeatspec: template: metadata: labels: k8s-app: filebeat spec: serviceAccountName: filebeat terminationGracePeriodSeconds: 30 tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master containers: - name: filebeat image: elastic/filebeat:6.5.4 args: [ "-c", "/usr/share/filebeat/filebeat.yml", "-e", ] env: - name: ELASTICSEARCH_HOST value: elasticsearch.elasticsearch - name: ELASTICSEARCH_PORT value: "9200" securityContext: runAsUser: 0 # If using Red Hat OpenShift uncomment this: #privileged: true resources: limits: memory: 200Mi requests: cpu: 100m memory: 100Mi volumeMounts: - name: config mountPath: /usr/share/filebeat/filebeat.yml readOnly: true subPath: filebeat.yml - name: inputs mountPath: /usr/share/filebeat/inputs.d readOnly: true - name: data mountPath: /usr/share/filebeat/data - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true volumes: - name: config configMap: defaultMode: 0600 name: filebeat-config - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: inputs configMap: defaultMode: 0600 name: filebeat-inputs # data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart - name: data hostPath: path: /var/lib/filebeat-data type: DirectoryOrCreate---Let’s see what is going on here:
- Logs for each pod are written to /var/log/docker/containers. We are mounting this directory from the host to the Filebeat pod and then Filebeat processes the logs according to the provided configuration.
- We have set the env var ELASTICSEARCH_HOST to elasticsearch.elasticsearch to refer to the Elasticsearch client service which was created in part 1 of this article. In case you already have an Elasticsearch cluster running, the
envvar should be set to point to it.
Please note the following setting in the manifest:
... tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master...This makes sure that our Filebeat DaemonSet schedules a pod on the master node as well.
Once the Filebeat DaemonSet is deployed we can check if our pods get scheduled properly.
root$ kubectl -n logging get pods -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESfilebeat-4kchs 1/1 Running 0 6d 100.96.8.2 ip-10-10-30-206.us-east-2.compute.internal <none> <none>filebeat-6nrpc 1/1 Running 0 6d 100.96.7.6 ip-10-10-29-252.us-east-2.compute.internal <none> <none>filebeat-7qs2s 1/1 Running 0 6d 100.96.1.6 ip-10-10-30-161.us-east-2.compute.internal <none> <none>filebeat-j5xz6 1/1 Running 0 6d 100.96.5.3 ip-10-10-28-186.us-east-2.compute.internal <none> <none>filebeat-pskg5 1/1 Running 0 6d 100.96.64.4 ip-10-10-29-142.us-east-2.compute.internal <none> <none>filebeat-vjdtg 1/1 Running 0 6d 100.96.65.3 ip-10-10-30-118.us-east-2.compute.internal <none> <none>filebeat-wm24j 1/1 Running 0 6d 100.96.0.4 ip-10-10-28-162.us-east-2.compute.internal <none> <none>root$ kubectl -get nodes -o wideNAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIMEip-10-10-28-162.us-east-2.compute.internal Ready master 6d v1.14.8 10.10.28.162 <none> Debian GNU/Linux 9 (stretch) 4.9.0-9-amd64 docker://18.6.3ip-10-10-28-186.us-east-2.compute.internal Ready node 6d v1.14.8 10.10.28.186 <none> Debian GNU/Linux 9 (stretch) 4.9.0-9-amd64 docker://18.6.3ip-10-10-29-142.us-east-2.compute.internal Ready master 6d v1.14.8 10.10.29.142 <none> Debian GNU/Linux 9 (stretch) 4.9.0-9-amd64 docker://18.6.3ip-10-10-29-252.us-east-2.compute.internal Ready node 6d v1.14.8 10.10.29.252 <none> Debian GNU/Linux 9 (stretch) 4.9.0-9-amd64 docker://18.6.3ip-10-10-30-118.us-east-2.compute.internal Ready master 6d v1.14.8 10.10.30.118 <none> Debian GNU/Linux 9 (stretch) 4.9.0-9-amd64 docker://18.6.3ip-10-10-30-161.us-east-2.compute.internal Ready node 6d v1.14.8 10.10.30.161 <none> Debian GNU/Linux 9 (stretch) 4.9.0-9-amd64 docker://18.6.3ip-10-10-30-206.us-east-2.compute.internal Ready node 6d v1.14.8 10.10.30.206 <none> Debian GNU/Linux 9 (stretch) 4.9.0-9-amd64 docker://18.6.3If we tail the logs for one of the pods we can clearly see that it connected to Elasticsearch and has started harvester for the files. The snippet below shows this:
2019-11-19T06:22:03.435Z INFO log/input.go:138 Configured paths: [/var/lib/docker/containers/c2b29f5e06eb8affb2cce7cf2501f6f824a2fd83418d09823faf4e74a5a51eb7/*.log]2019-11-19T06:22:03.435Z INFO input/input.go:114 Starting input of type: docker; ID: 4134444498769889169 2019-11-19T06:22:04.786Z INFO input/input.go:149 input ticker stopped2019-11-19T06:22:04.786Z INFO input/input.go:167 Stopping Input: 41344444987698891692019-11-19T06:22:19.295Z INFO [monitoring] log/log.go:144 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":641680,"time":{"ms":16}},"total":{"ticks":2471920,"time":{"ms":180},"value":2471920},"user":{"ticks":1830240,"time":{"ms":164}}},"handles":{"limit":{"hard":1048576,"soft":1048576},"open":20},"info":{"ephemeral_id":"007e8090-7c62-4b44-97fb-e74e8177dc54","uptime":{"ms":549390018}},"memstats":{"gc_next":47281968,"memory_alloc":29021760,"memory_total":156062982472}},"filebeat":{"events":{"added":111,"done":111},"harvester":{"closed":2,"open_files":15,"running":13}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":108,"batches":15,"total":108},"read":{"bytes":69},"write":{"bytes":123536}},"pipeline":{"clients":1847,"events":{"active":0,"filtered":3,"published":108,"total":111},"queue":{"acked":108}}},"registrar":{"states":{"current":87,"update":111},"writes":{"success":18,"total":18}},"system":{"load":{"1":0.98,"15":1.71,"5":1.59,"norm":{"1":0.0613,"15":0.1069,"5":0.0994}}}}}}2019-11-19T06:22:49.295Z INFO [monitoring] log/log.go:144 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":641720,"time":{"ms":44}},"total":{"ticks":2472030,"time":{"ms":116},"value":2472030},"user":{"ticks":1830310,"time":{"ms":72}}},"handles":{"limit":{"hard":1048576,"soft":1048576},"open":20},"info":{"ephemeral_id":"007e8090-7c62-4b44-97fb-e74e8177dc54","uptime":{"ms":549420018}},"memstats":{"gc_next":47281968,"memory_alloc":38715472,"memory_total":156072676184}},"filebeat":{"events":{"active":12,"added":218,"done":206},"harvester":{"open_files":15,"running":13}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":206,"batches":24,"total":206},"read":{"bytes":102},"write":{"bytes":269666}},"pipeline":{"clients":1847,"events":{"active":12,"published":218,"total":218},"queue":{"acked":206}}},"registrar":{"states":{"current":87,"update":206},"writes":{"success":24,"total":24}},"system":{"load":{"1":1.22,"15":1.7,"5":1.58,"norm":{"1":0.0763,"15":0.1063,"5":0.0988}}}}}}2019-11-19T06:23:19.295Z INFO [monitoring] log/log.go:144 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":641750,"time":{"ms":28}},"total":{"ticks":2472110,"time":{"ms":72},"value":2472110},"user":{"ticks":1830360,"time":{"ms":44}}},"handles":{"limit":{"hard":1048576,"soft":1048576},"open":20},"info":{"ephemeral_id":"007e8090-7c62-4b44-97fb-e74e8177dc54","uptime":{"ms":549450017}},"memstats":{"gc_next":47281968,"memory_alloc":43140256,"memory_total":156077100968}},"filebeat":{"events":{"active":-12,"added":43,"done":55},"harvester":{"open_files":15,"running":13}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":55,"batches":12,"total":55},"read":{"bytes":51},"write":{"bytes":70798}},"pipeline":{"clients":1847,"events":{"active":0,"published":43,"total":43},"queue":{"acked":55}}},"registrar":{"states":{"current":87,"update":55},"writes":{"success":12,"total":12}},"system":{"load":{"1":0.99,"15":1.67,"5":1.49,"norm":{"1":0.0619,"15":0.1044,"5":0.0931}}}}}}2019-11-19T06:23:25.261Z INFO log/harvester.go:255 Harvester started for file: /var/lib/docker/containers/ccb7dc75ecc755734f6befc4965b9fdae74d59810914101eadf63daa69eb62e2/ccb7dc75ecc755734f6befc4965b9fdae74d59810914101eadf63daa69eb62e2-json.log2019-11-19T06:23:49.295Z INFO [monitoring] log/log.go:144 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":641780,"time":{"ms":28}},"total":{"ticks":2472310,"time":{"ms":196},"value":2472310},"user":{"ticks":1830530,"time":{"ms":168}}},"handles":{"limit":{"hard":1048576,"soft":1048576},"open":21},"info":{"ephemeral_id":"007e8090-7c62-4b44-97fb-e74e8177dc54","uptime":{"ms":549480018}},"memstats":{"gc_next":47789200,"memory_alloc":31372376,"memory_total":156086697176,"rss":-1064960}},"filebeat":{"events":{"active":16,"added":170,"done":154},"harvester":{"open_files":16,"running":14,"started":1}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":153,"batches":24,"total":153},"read":{"bytes":115},"write":{"bytes":207569}},"pipeline":{"clients":1847,"events":{"active":16,"filtered":1,"published":169,"total":170},"queue":{"acked":153}}},"registrar":{"states":{"current":87,"update":154},"writes":{"success":25,"total":25}},"system":{"load":{"1":0.87,"15":1.63,"5":1.41,"norm":{"1":0.0544,"15":0.1019,"5":0.0881}}}}}}Once we have all our pods running, then we can create an index pattern of the type filebeat-* in Kibana. Filebeat indexes are generally timestamped. As soon as we create the index pattern, all the searchable available fields can be seen and should be imported.
Lastly, we can search through our application logs and create dashboards if needed.
It is highly recommended to have JSON logger in our applications because it makes log processing extremely easy and messages can be parsed easily.
Conclusion
This concludes our logging set-up. All of the provided configuration files have been tested in production environments and are readily deployable.
Related articles

Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial
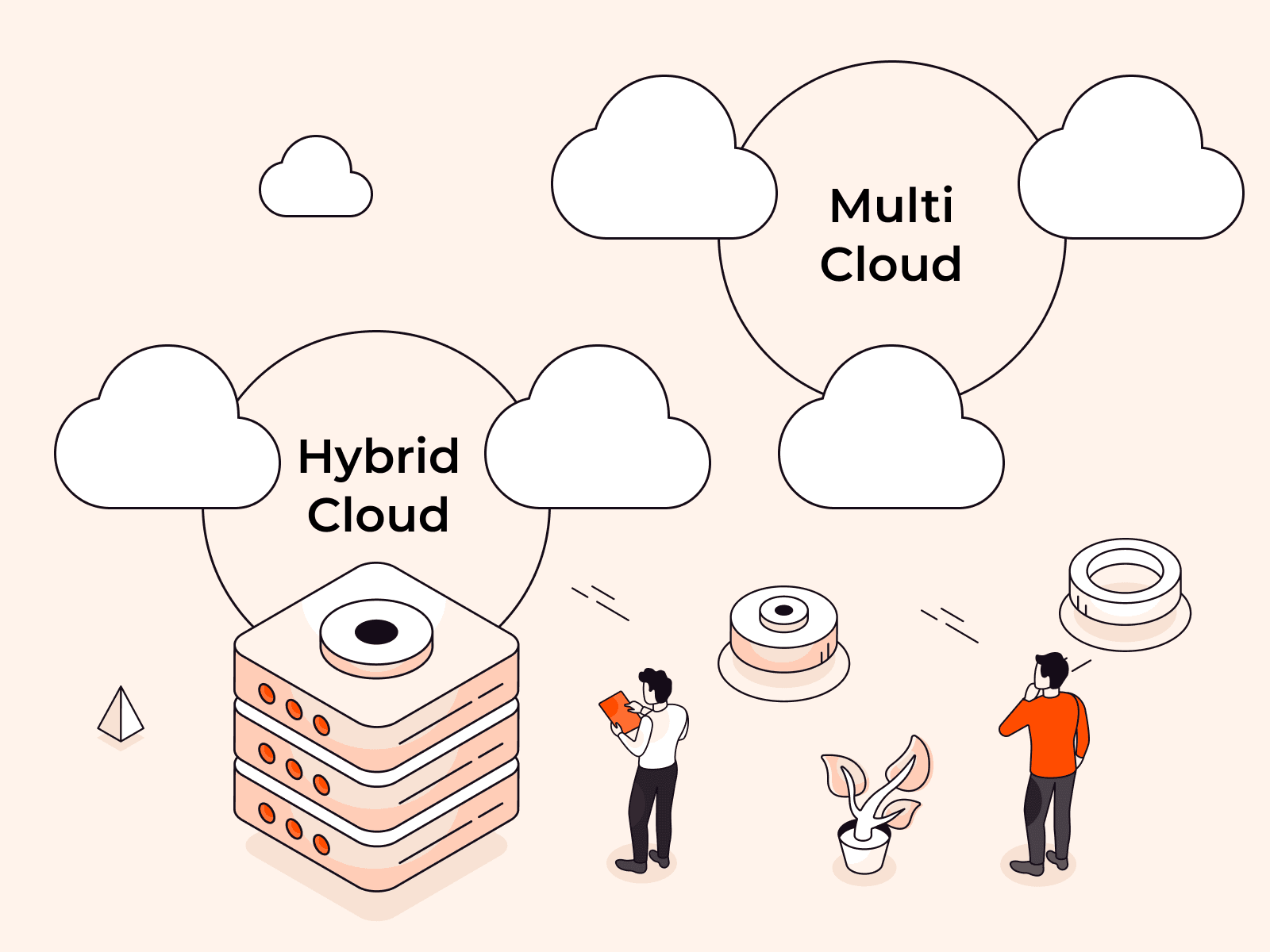
Multi-cloud and hybrid cloud represent two distinct approaches to distributed computing architecture that build upon the foundation of cloud computing to help organizations improve their IT infrastructure.Multi-cloud environments involve us
Multi-cloud is a cloud usage model where an organization utilizes public cloud services from two or more cloud service providers, often combining public, private, and hybrid clouds, as well as different service models, such as Infrastructur
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.