Why do we use premium technical support?
- October 26, 2018
- 2 min read

We value our clients, that is why we entrust only experienced and friendly technical support specialists to assist them in connecting, integrating, configuring and maintaining our products.
Technical support work principles and feedback from clients
1. Do not hesitate and respond within 10 minutes after the request.
2. Respond with understandable and detailed instructions.
If the client struggles figuring things out, we do not give links to the knowledge base, but explain everything in detail.
Everything is prompt and clear, thanks
Videonow
In the last 2–3 months I have been actively communicating with Gcore’s support by mail and I was extremely surprised by their approach: completeness of responses, not just bits of some professional information, but rather clear instructions for those who only delve into the matter. Work with CDN is mega comfortable. Requests for download and upload speed, cache, Purge, API and other also get easily resolved.
Wargaming
3. Notify about all stages of processing the request.
We continuously monitor the status of sources and immediately inform clients about the performance of their resources.
The most common messages are:
- Client source is unavailable (5xx errors).
- Recommend changing current settings of client’s CDN resource and products.
- Notify that Storage space is running out.
- Notify about changes in current options.
- Offer a subscription to Status Page about current restrictions or system updates.
We also analyze clients’ control panel activity and always offer assistance if we notice that they cannot set up content delivery themselves.
Hello. OK. That is not so urgent. Thank you up updating
Benjamin Y Kweon, RedFox Games
4. Be responsive and helpful in any situation.
I think our conversation is going very well.
Today is the first contact and we’ll see what’s happening next
Angola Cables
It is because Irina gave me excellent support… Thanks Irina
Each of our clients can be sure that we will provide qualified help around the clock, even on holidays and weekends, in English, and soon in Chinese.

Related articles

Some AI jobs require the full power and predictability of dedicated bare metal clusters. Others need something more agile: compute that can be sized up or down quickly, used for a burst of experimentation, powered down when idle, and spun b
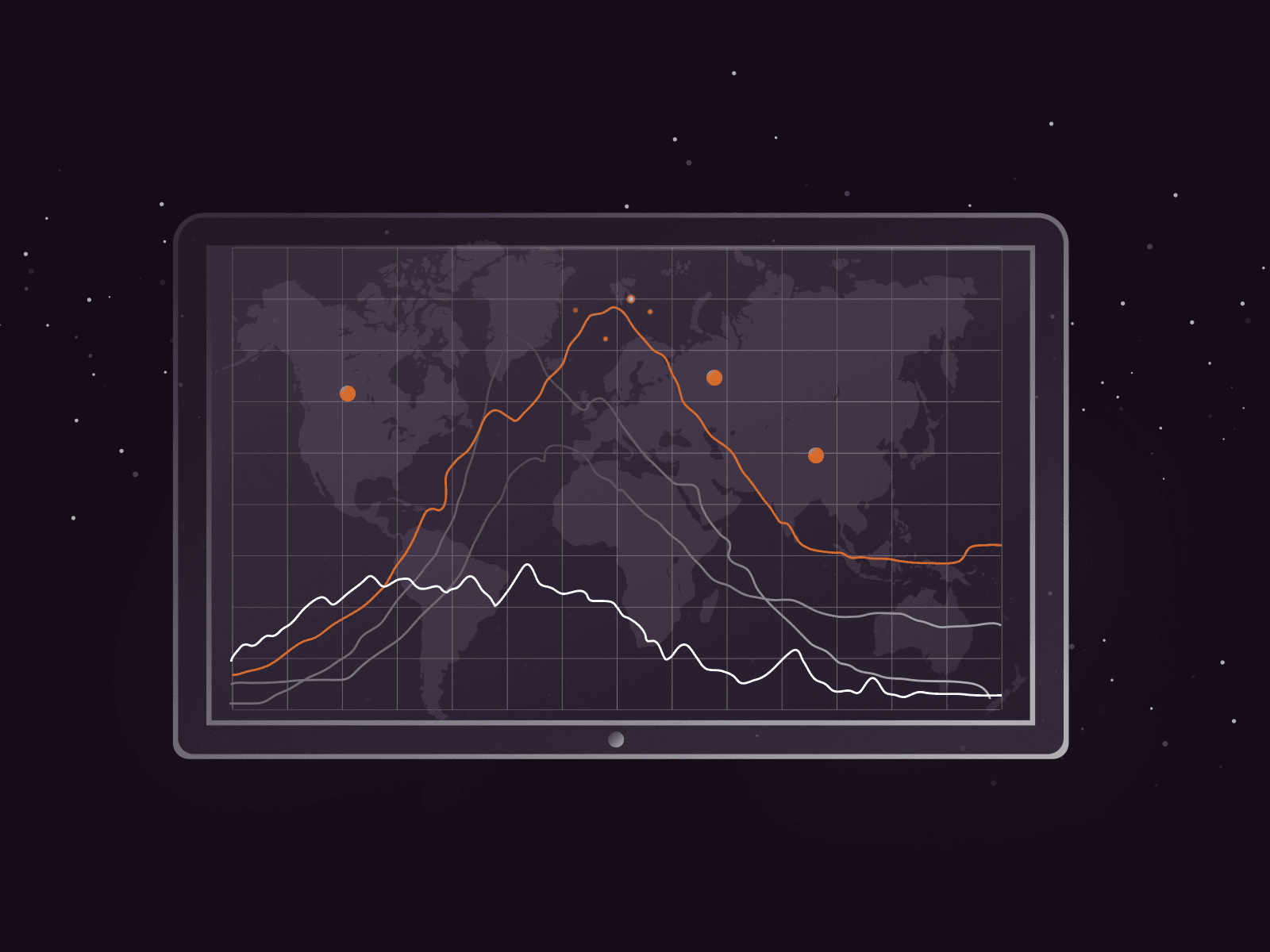
Cyberattacks are not just growing—they're accelerating at an alarming pace. The second half of 2025 marked a dramatic escalation in both the frequency and scale of DDoS attacks, with record-breaking volumes and increasingly sophisticated ta
AI adoption has a fragmentation problem. Organizations routinely stitch together separate tools for development, training, and serving, each with its own infrastructure, access controls, and operational overhead. The result is a patchwork t


Imagine if you could click a button and suddenly your GPUs increase their throughput by 6x. Or reduce latency by 2x. Or route inference requests seamlessly across different GPU types.That's the experience we're bringing to our inference cus
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.
Vione Ltd