
Artificial intelligence (AI) has become an essential tool in the field of cybersecurity because it excels in key tasks such as malware detection, unauthorized access identification, and the prevention of phishing attacks, reducing human workload in the field. In this article, we will explore how and when AI enhances cybersecurity, look at the challenges these applications present, and understand future trends in AI-driven cybersecurity.
What Is AI for Cybersecurity?
Artificial intelligence enhances cybersecurity by offering smart, adaptable solutions that keep up with changing threats. It constantly learns and evolves, making it a strong line of defense for IT systems. AI can quickly analyze large amounts of past data to understand normal user behavior, device usage, and network activity. This allows AI to spot and react to unusual patterns, as well as identify new or complicated threats like zero-day malware and ransomware attacks.
For instance, an artificial intelligence system could spot a new kind of malware by noticing strange file behavior or unusual network connections among its large database of known attacks. Without AI, this kind of attack might go unnoticed or be hard to stop, since traditional systems are generally set up to deal with known threats.
AI significantly improves our ability to detect and handle cyber threats, even those that slip past traditional security measures. As a result, AI in cybersecurity represents a paradigm shift in cybersecurity—from simply reacting to threats, to actively preventing them.
Key Features of AI Cybersecurity
AI-based cybersecurity solutions have distinct advantages over traditional methods, offering three core features that set them apart:
- Real-time detection: AI responds swiftly to both known and unknown threats as they unfold in real time. Traditional systems may rely on periodic scans or preset rules, but AI continuously monitors network activity, allowing it to identify and mitigate risks as they happen.
- Continuous learning: AI constantly refines its capabilities by learning from new data. This constant evolution enables AI to recognize fresh types of attacks or slight variations of existing ones more effectively than traditional systems. Over time, the AI model becomes increasingly capable of identifying and neutralizing novel threats.
- Deep understanding: AI can uncover complex threats and find intricate patterns that might elude human detection because its vast computational power allows it to sift through massive data sets, uncovering subtle anomalies or connections that might otherwise escape human attention.
How Is AI Used in Cybersecurity?
Artificial intelligence excels in several key areas of cybersecurity, including the ability to uncover complex relationships between different types of threats and enhancing the accuracy and consistency of threat detection. For example, AI can use the MITRE ATT&CK framework to create a straightforward, chronological visualization of an attacker’s actions, helping to illuminate the progression of a threat. Here’s an example of the visualization:
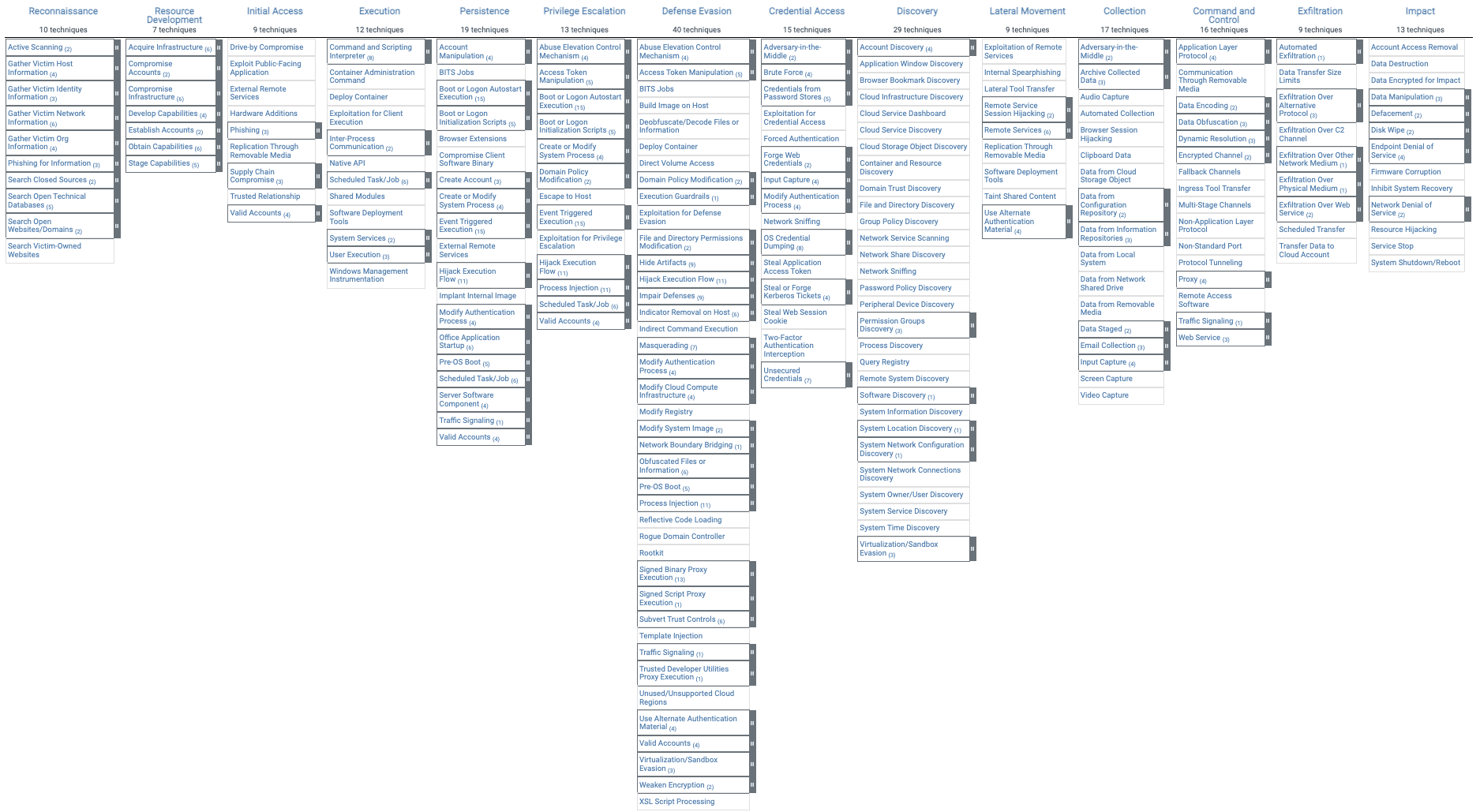
Artificial intelligence streamlines rapid response efforts by prioritizing alerts, assessing threat criticality, and speeding up threat response workflows. It automates routine tasks like log organization and scans, reducing human error and addressing the shortage of skilled cybersecurity professionals.
AI allows organizations to track complex, multi-step cyberattacks by pulling together data from various security platforms. For instance, a cybercriminal may initially infiltrate a network, explore its structure quietly, and then begin data theft. While each of these steps might trigger a warning on individual security platforms, AI combines these alerts to reveal the attacker’s complete strategy. This holistic view enables an organization to take decisive action to stop the attack completely.
Real-World Use Cases of AI in Security and Their Benefits
Utilizing AI-powered cybersecurity tools offers organizations a range of tangible benefits across its various use cases. Let’s take a look at six specific use cases.

Transaction Monitoring for Fraud Prevention
AI analyzes extensive transaction and login data to detect anomalies indicative of fraudulent behavior or unauthorized access. For example, it can scan huge volumes of transaction and login data, flagging unusual activities like new login locations or rapid transactions as potential threats. By connecting seemingly isolated incidents, AI provides human analysts with automated root-cause analyses so that the relevant improvements to security can be made.
Intelligent Endpoint and Network Safeguarding
This means protecting devices connected to a network—computers, mobiles, and servers—and the network itself. For example, when an employee inadvertently downloaded malware onto their work computer, the company’s AI-based security system immediately detected the unusual behavior, flagged the threat, and isolated the affected device from the network, preventing the malware from spreading to other systems.
By learning from historical data, AI identifies malware threats and behavioral anomalies on individual devices. It also cross-references incoming network traffic against known threat indicators, flagging unusual activity swiftly and accurately.
Policy-Compliant Cloud Protection
Within cloud environments, AI monitors cloud configuration settings and permissions in real time, providing alerts for any deviations from security policies. This tightens cloud security, making it easier to comply with both internal guidelines and external regulations, such as the General Data Protection Regulation (GDPR,) the Health Insurance Portability and Accountability Act (HIPAA,) and the Payment Card Industry Data Security Standard (PCI DSS.)
Accelerated Threat Detection and Containment
AI reduces dwell time—the time between a breach starting and being contained—by rapidly analyzing large datasets to identify unusual activities. It cross-references these irregular activities with established threat frameworks like MITRE ATT&CK to make the information easy to read and act upon for human specialists. The resulting reduction in dwell time minimizes damage and yields considerable cost savings: The longer a breach goes undetected, the more damage it can cause, as attackers use this time to steal data, install malware, and disrupt operations. Damage translates into financial loss due to downtime and even regulatory fines.
For example, when a healthcare provider suffered a cyber breach, its AI security tools quickly flagged irregular data transfers and mapped them to the MITRE ATT&CK framework. The cybersecurity team was able to identify and contain the issue with speed and accuracy, minimizing the exposure of patient data and avoiding hefty HIPAA fines.
Data-Driven Risk Management and Security Posture
Due to its capacity for high-speed data analysis, AI significantly reduces both the mean time to detect (MTTD) and mean time to respond (MTTR) to security threats by automating the analysis of vast volumes of threat research data. Security analysts can therefore refocus their efforts from mundane tasks to high-level, strategic threat assessments.
For instance, when a major retail company is hit by a sudden surge of fraudulent transactions, its AI-driven security system quickly identifies the unusual activity so that security analysts can immediately investigate and halt the scam. The result? No financial loss or reputational damage occurs.
Data-Driven, Futureproof Security Protocols
Instead of only using a fixed set of rules for handling security issues, AI can change these rules based on new information. For example, if AI detects an increase in login attempts from a specific geographical location that historically hasn’t shown such activity, it might automatically adjust the security protocols to require additional verification steps for users logging in from that area.
In this way, AI helps security experts keep improving how they handle problems. As a result, the organization gains heightened credibility among customers, stakeholders, and partners for its ability to adeptly manage and mitigate security risks.
Overcoming Challenges in Implementing AI for Cybersecurity
Let’s delve into some challenges of AI for cybersecurity: ensuring AI transparency, addressing bias, and seamlessly integrating AI into existing security systems. We’ll also discuss how thee challenges are being overcome.

Transparency
Artificial intelligence models are often perceived as “black boxes” due to the limited insights available into their decision-making processes, resulting in concerns about their transparency. Understanding how an AI model flags suspicious network activity in cybersecurity is crucial because it helps to validate the model’s decisions, enable improvements, ensure regulatory compliance, build trust, and allow for effective human intervention when needed.
To address this, the industry is moving towards transparent algorithms, such as LIME and SHAP. LIME can demystify a specific AI decision by simulating a simpler model, while SHAP clarifies how each data feature influences the AI’s decision. These approaches are making AI more understandable and accountable.
Bias and Fairness Concerns in AI Models and Data
Bias in AI can lead to erroneous decisions and misjudged threats. For example, AI is trained to identify potentially malicious behavior based on historical data. If the training data primarily consists of cyberattack examples originating from specific geographic locations or IP address ranges, the AI model might develop a bias towards flagging any activity from those locations as malicious, even when it’s not.
To mitigate bias, organizations should focus on diverse and representative training data, rigorous preprocessing, and ongoing evaluation. Fairness-aware learning algorithms and model monitoring can help. Organizations are increasingly dedicating resources to ensure AI-driven cybersecurity solutions are reliable, equitable, and free from unfair discrimination.
Integrating AI Solutions with Existing Security Systems
Successfully integrating artificial intelligence solutions into existing security architectures is possible only when compatibility and organizational needs are accounted for. This may involve custom interfaces that communicate with legacy systems, API integration for real-time data exchange, or choosing AI solutions designed to work with existing firewalls and intrusion detection systems. For a seamless experience, steps like compatibility testing and middleware solutions are crucial. Done right, this integration amplifies overall security effectiveness, as discussed earlier.
Best Practices for AI Implementation in Security
The adoption of AI in cybersecurity requires a strategic and responsible approach, focusing on effectiveness, ethics, and alignment with organizational goals. These best practices serve as the foundation for success in navigating the dynamic landscape of AI for cybersecurity:
Develop an AI Integration Plan
Create a comprehensive plan that addresses specific security challenges. For example, to combat phishing attacks, tailor a machine learning algorithm to detect fraudulent email patterns. Ensure that the AI solution aligns with existing security processes.
Ensure Data Quality and Privacy
The quality of data used for AI training and operation is paramount because poor-quality or incomplete data can result in misidentified threats, false alarms, and potentially disastrous security vulnerabilities. As mentioned before, if training data is from a geographically limited area, real data from that area will be handled differently than real data from elsewhere in the world.
Implement robust data handling, validation, cleaning, and transformation processes. For example, use ETL (extract, transform, load) pipelines to pull raw data from various sources, validate it against pre-set rules for quality (e.g., no missing values or outliers,) clean any anomalies, and then transform it into a unified format suitable for machine learning algorithms.
Safeguard personal and sensitive information through encryption and access restrictions to prevent data-related issues. As an example, encrypt sensitive customer data using AES-256 encryption before storing it in the database, and set up role-based access control so that only designated staff, like system administrators or senior data analysts, can decrypt and view this information.
Establish an Ethical Framework
Develop clear principles, guidelines, and practices to prevent biases and ensure transparency in AI operations. This provides both ethical and operational boundaries, reducing the risk of unjust or misunderstood decisions. Address the potential for AI models to inadvertently learn biases from training data to avoid unfair or discriminatory outcomes when the AI model is deployed, which would affect the integrity of the security measures in place.
For example, an organization could adopt a framework like the AI Ethics Guidelines from the European Union, which sets principles on transparency, fairness, and data governance. The organization could then implement an “AI Ethics Audit” process that involves third-party evaluators reviewing the AI model’s decision-making patterns and training data to ensure compliance with these principles.
Regularly Test and Update
Given the rapidly evolving security landscape, continuously test and update AI models to ensure they remain effective. For instance, if an organization’s AI model is designed to detect ransomware based on network traffic patterns, regular testing might involve exposing the model to new ransomware techniques that mimic legitimate traffic, followed by retraining and updating the model if it fails to identify this new kind of threat.
The Future of AI in Cybersecurity
As advancements in AI and machine learning continue, their applications in cybersecurity will expand, delivering new solutions and refined tools. This evolution may also involve integration with emerging technologies like 5G and the Internet of Things (IoT,) enabling a fusion of data collection and intelligent decision-making to bolster security.
The influence of AI on the cybersecurity landscape extends to the job market. While artificial intelligence automation may render certain roles, such as manual monitoring, obsolete, it concurrently creates fresh opportunities for specialization. Emerging positions like AI security specialists, machine learning engineers, and threat intelligence analysts are gaining prominence. This shift encourages skill development and specialization in these burgeoning fields, contributing to a more dynamic and adaptive security industry.
Conclusion
Cybersecurity threats are constantly evolving, demanding advanced solutions to safeguard digital assets. Artificial intelligence is emerging as a key tool for analyzing and responding to these dynamic risks. By integrating AI into cybersecurity systems, companies can swiftly adapt their cyber defenses by rapidly identifying and responding to emerging threats. This approach adds to, and is sometimes superior to, traditional security measures, leveraging predictive analytics to proactively identify and mitigate potential risks before they escalate.
For organizations seeking an integrated platform to harness the full potential of AI and streamline their machine learning endeavors, Gcore’s AI IPU and GPU Cloud Infrastructure. With features like version control, dataset management, and widespread availability across multiple regions, Gcore’s AI Infrastructure stands poised to elevate AI capabilities and fortify cybersecurity defenses.
Related articles

What if you could ask your infrastructure questions and get real answers?With Gcore’s open-source implementation of the Model Context Protocol (MCP), now you can. MCP turns generative AI into an agent that understands your infrastructure, r
As more AI workloads shift to the edge for lower latency and localized processing, the attack surface expands. Defending a data center is old news. Now, you’re securing distributed training pipelines, mobile inference APIs, and storage envi



Large language models (LLMs) like DeepSeek 70B are revolutionizing industries by enabling more advanced and dynamic conversational AI solutions. Whether you’re looking to build intelligent customer support systems, enhance content generatio

Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.