
In this article we will explore How you can use your C++ Runtime with Lambda Function. AWS Lambda allows us to use our app in a serverless architecture. As an addition to all the available runtimes in AWS Lambda, AWS announced Custom Runtimes at AWS Re:Invent 2018 where they released open-source custom runtimes for C++.
The advantage of using a custom runtime is that it allows you to use any sort of code in your Lambda function. Though there are few examples to use C++ Api Runtime but there is not enough reference on HOW to use a handler function and send/receive JSON data, which we will explore below.
Prerequisites
You need a Linux-based environment. It will be used for compiling and deploying your code –
##C++11 compiler, either GCC 5.x or later Clang 3.3 or later $ yum install gcc64-c++ libcurl-devel$ export CC=gcc64$ export CXX=g++64##CMake v.3.5 or later.$ yum install cmake3##Git$ yum install gitHere we will install all these tools with Docker. Running the docker build command with Dockerfile will install the necessary AWS Linux machine image’s environment, complying C++ code and deploy to AWS Lambda.
Note –
- This Dockerfile is only for an existing Lambda update, hence please ensure to create your Lambda instance by either the AWS CLI or the AWS Console.
- Please ensure to create the API Gateway and bind with C++ Lambda.
The reason for using Docker is that it will create an isolated place to work, preventing all possible errors and make it simple and re-use.
C++ Lambda Compiler With Dockerfile
Open a project directory which includes all project codes and the Dockerfile, following which create the Docker image in the same directory. An example on how it should look like:
Lets start to build our Docker image from the Dockerfile.
FROM amazonlinux:latest## install required development packagesRUN yum -y groupinstall "Development tools" RUN yum -y install gcc-c++ libcurl-devel cmake3 gitRUN pip3 install awscliThe above will use Amazon Linux for base image and install necessary components.
Following that we will add the C++ API runtime environment. This will let you install and use Lambda libraries for C++ in your code; through the call-handler function you would be able to use the C++ dependencies.
# install C++ runtime environmentRUN git clone https://github.com/awslabs/aws-lambda-cpp.git && \ cd aws-lambda-cpp && mkdir build && cd /aws-lambda-cpp/build && \ cmake3 .. -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=OFF \ -DCMAKE_INSTALL_PREFIX=/out -DCMAKE_CXX_COMPILER=g++ && \ make && make installThis will install the Lambda C++ environment – you do not need to change anything in this part.
CMAKE will handle and use this library creating an output point which our main code will use as a dependency while compiling.
# include C++ source code and build configurationADD adaptiveUpdate.cpp /adaptiveUpdateADD CMakeLists.txt /adaptiveUpdateCopy your main code and the CMAKE file to the Docker container.
# compile & package C++ codeRUN cd /adaptiveUpdate && mkdir build && cd build && \ cmake3 .. -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=OFF \ -DCMAKE_PREFIX_PATH=/out -DCMAKE_CXX_COMPILER=g++ && \ make && make aws-lambda-package-adaptiveUpdateThis will compile our code and make a deployable zip file. You can change your package name and will find it in your build folder which is located under the code directory. Next step is to deploy this zip file as a Lambda function to your AWS account. To make this happen we need to add ENV which defines our user access-id and secret-key.
ENV AWS_DEFAULT_REGION=''ENV AWS_ACCESS_KEY_ID=''ENV AWS_SECRET_ACCESS_KEY=''RUN aws lambda update-function-code --function-name hello-world \--zip-file fileb://adaptiveUpdate/build/adaptiveUpdate.zipAdd your secret key, access id and region to access and deploy your code to AWS. Let us start by creating a Lambda named hello-world. Additional details can be found in the link below:

Handler Method For Lambda
When you start using Lambda, you will notice that Lambda needs handler function, and below we will see how you can import the C++ handler function to your main code and how you retrieve your function as a return. The handler function is used to access lambda function and to send and retrieve JSON data.
Firstly you need to create a main function which will call the handler function.
int main(){ run_handler(my_handler); return 0;}That’s it!
Secondly we will add our code handler function which includes response and request when you invoke Lambda.
invocation_response my_handler(invocation_request const& req){ string json = req.payload; test(json); return invocation_response::success(json, "application/json"); }In the section below, we are receiving the payload of the JSON value which separated from header.
string json = req.payload; JSON value will be similar to:

Create a string variable considering the req.payload JSON value as a string. Use it update the test function.
test(json); string json = req.payload; Return the main function with the updated value. Note that this will return it as JSON format.
return invocation_response::success(json, "application/json"); In the next stage we will invoke Lambda with the API Gateway.
API Gateway to Invoke Lambda
There are several ways to invoke your Lambda function, which can be through CLI, S3 or API Gateway. For the purpose of this article, we are going to use the API Gateway (REST API) method to invoke Lambda. You can configure this gateway through the Swagger Yaml, details of which can be found in the link below:

We are going to use our API Gateway as a proxy for this project. We will create a stage, resources and method, following which we will integrate it with our Lambda function.
- Give a name to your REST API: ours is cppjsonupdate. Leave everything as default. Click on Create API.

- Next is to create new resources for our API. Choose Create Resource under the Actions menu and set a Resource Name as per your choice, and give the path or can leave it as Default. Click on Create Resource.


- Under the Actions menu, add a Method. We are choosing Any for the purpose of this article. Please note to click the green tick to save.
- Deploy your API by clicking Deploy API under the Actions menu. Choose Popup Menu Stage. You will also need to add ARN of the Lambda function which you can find in Lambda service page. Following that choose New Stage and set a Stage Name. Click on Deploy.
arn:aws:lambda:us-east-1:34728394278492:function:adaptiveupdate
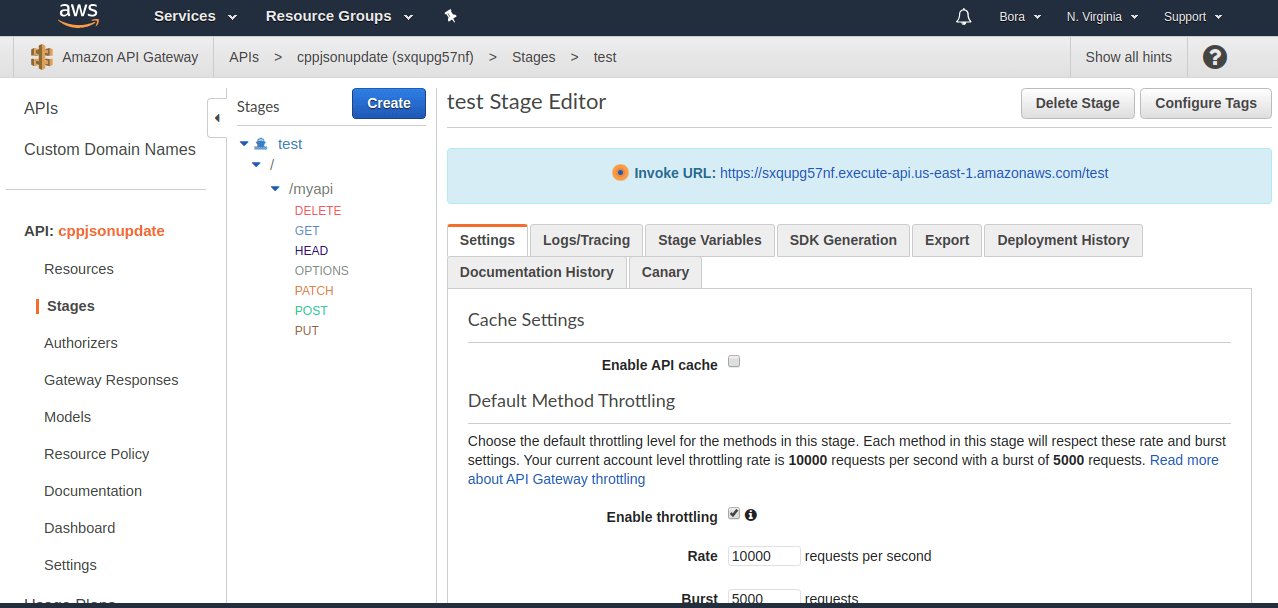
- Your API Gateway is now configured and integrated with C++ lambda. You can use endpoint for invocation. It should be similar to this –

As the final step, you can find the invoke URL under the Stages section as shown below.
Conclusion
Hopefully with the help of this article you can now understand and use your code in Lambda Runtime API to easily manage, create and deploy your function on Docker.
Related articles


Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.