
Einleitung
Der Erfolg einer Anwendung kann ihr gleichzeitig auch zum Verhängnis werden, wenn sie nicht auch bei Tausenden von täglichen Benutzern entsprechend effektiv funktioniert. Wenn die Kapazität der Anwendungsinfrastruktur zu Beginn zu niedrig eingestellt wurde, müssen Sie Ihr System mit der zunehmenden Beliebtheit Ihrer Anwendung umgestalten und neu implementieren, um dem zusätzlichen Datenverkehr gerecht zu werden. Daher ist es äußerst wichtig, dass Ihre Anwendung automatisch skalierbar ist. Mit der Autoskalierung können die Server-Ressourcen Ihrer Anwendung automatisch erweitert werden, wenn die Anzahl an Benutzeranfragen steigt. Wenn es weniger Anfragen gibt, können die Server-Ressourcen stattdessen reduziert werden, damit Sie die Kosten Ihrer Infrastruktur optimieren können. In diesem Artikel erläutern wir, was Autoskalierung ist, wie sie funktioniert und wie und wieso Sie Autoskalierung effektiv und einfach für Ihre zukünftigen Anwendungen verwenden können.
Was ist die Autoskalierung?
Autoskalierung ist eine Funktion, mit der Sie Ihre Anwendungen automatisch auf eine variierende Anzahl an Benutzeranfragen anpassen können. Wenn es wenige Benutzeranfragen gibt, werden Ihre Server-Ressourcen automatisch reduziert, um Kosten zu sparen. Wenn die Anzahl an Anfragen zunimmt, werden Ihrem Anwendungsserver automatisch neue Ressourcen hinzugefügt, damit die Anfragen effizient verarbeitet werden können.
Bei der traditionellen Infrastrukturverwaltung müssen Sie die Server-Ressourcen Ihrer Anwendung manuell skalieren, wenn Sie eine zunehmende Anzahl an Benutzeranfragen bemerken. Dies ist keine einfache Aufgabe, da Ihre App unter Umständen viele Systemkomponenten enthält; während Sie die Server skalieren, müssen Ihre Benutzer erhebliche Ausfallzeiten in Kauf nehmen. Nachdem Sie die Ressourcen für Ihre Server erweitert haben, kann es zuweilen vorkommen, dass die Anzahl der Benutzeranfragen in gewissen Zeiträumen wieder sinkt ‒ beispielsweise an Wochentagen oder mitten in der Nacht. Wenn Ihre Anwendungsserver kontinuierlich auf hoher Kapazität betrieben werden, steigen Ihre Kosten unnötigerweise.
Arten der Autoskalierung
Es gibt zwei Arten von Autoskalierung:
- Vertikale Autoskalierung
- Horizontale Autoskalierung
Sehen wir uns die beiden Optionen der Reihe nach an.
Vertikale Autoskalierung
Bei der vertikalen Autoskalierung wird die Größe Ihres Servers automatisch erhöht, wenn mehr Ressourcen benötigt werden. Sehen wir uns dies am Beispiel eines Blog-Dienstes an. Um mehr API-Anfragen von Benutzern verarbeiten zu können, muss die Größe des Servers, auf dem Ihre PostgreSQL-Datenbank gehostet wird, erweitert werden, indem mehr CPUs, RAM und Festplatten installiert werden.
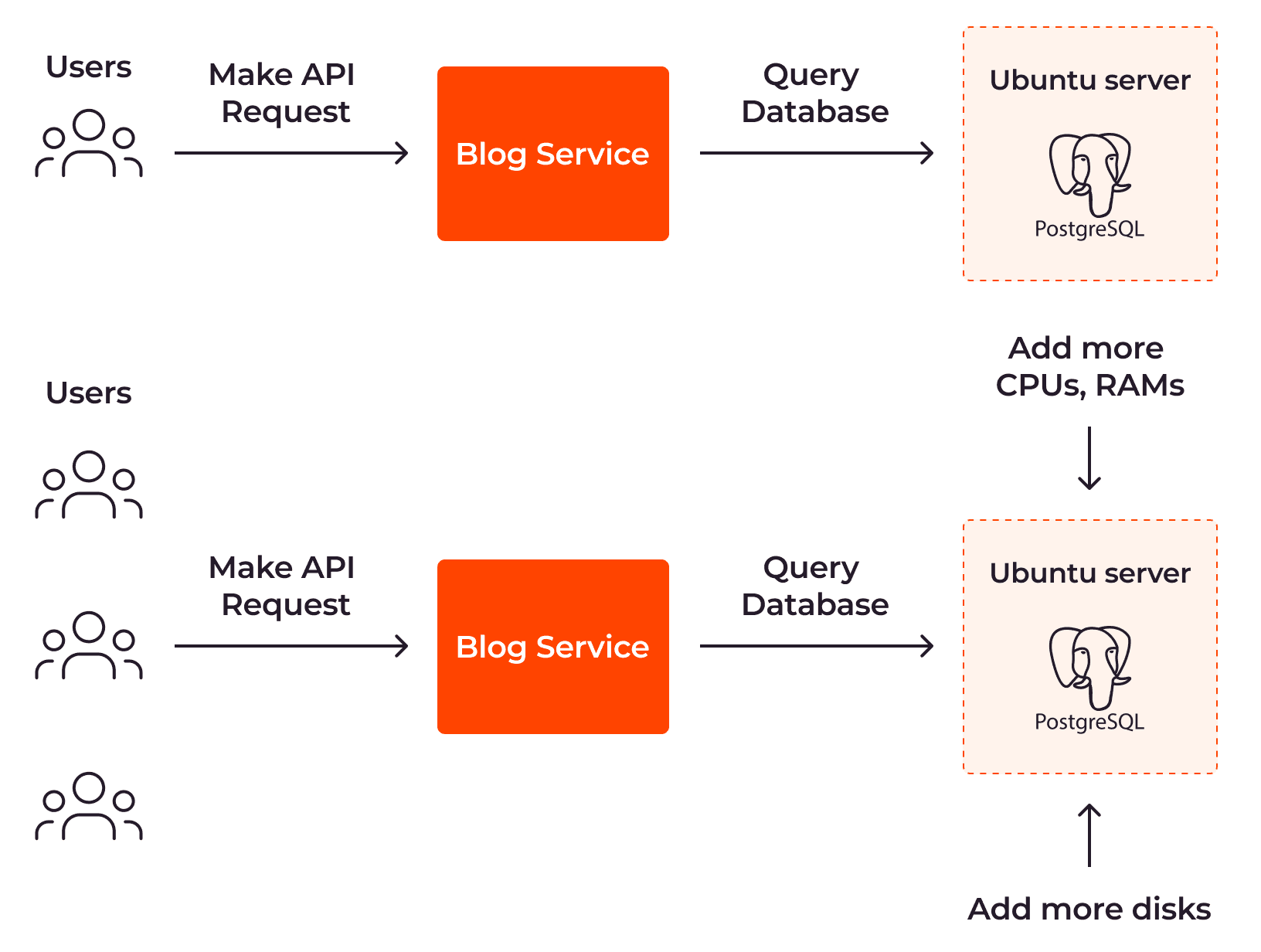
Wir verwenden oft Begriffe wie „Skalierung nach oben“ oder „Skalierung nach unten“, wenn wir über vertikale Skalierbarkeit sprechen. Wenn Sie nach oben skalieren, werden Ihre Ressourcen erweitert, damit sie mehr Arbeitsspeicher oder mehr CPUs haben, um mehr Anfragen zu verarbeiten. Wenn Sie nach unten skalieren, werden Ihre Ressourcen verkleinert und verwenden somit weniger Arbeitsspeicher oder CPUs, um die Kosten zu reduzieren.
Vertikale Autoskalierung wird für gewöhnlich für zentralisierte Systeme verwendet, da sie nicht darauf ausgelegt sind, über mehrere Instanzen hinweg verteilt zu sein. Sie werden üblicherweise auf einer einzelnen Instanz oder auf einer eng verknüpften Gruppe von Instanzen ausgeführt, was den Einsatz einer horizontalen Skalierung schwierig gestaltet.
Horizontale Autoskalierung
Bei der horizontalen Autoskalierung wird die Anzahl der Server automatisch und reaktiv angepasst. Bei diesem Ansatz wird ein PostgreSQL-Knoten hinzugefügt, um die steigende Anzahl an Benutzeranfragen zu verarbeiten.
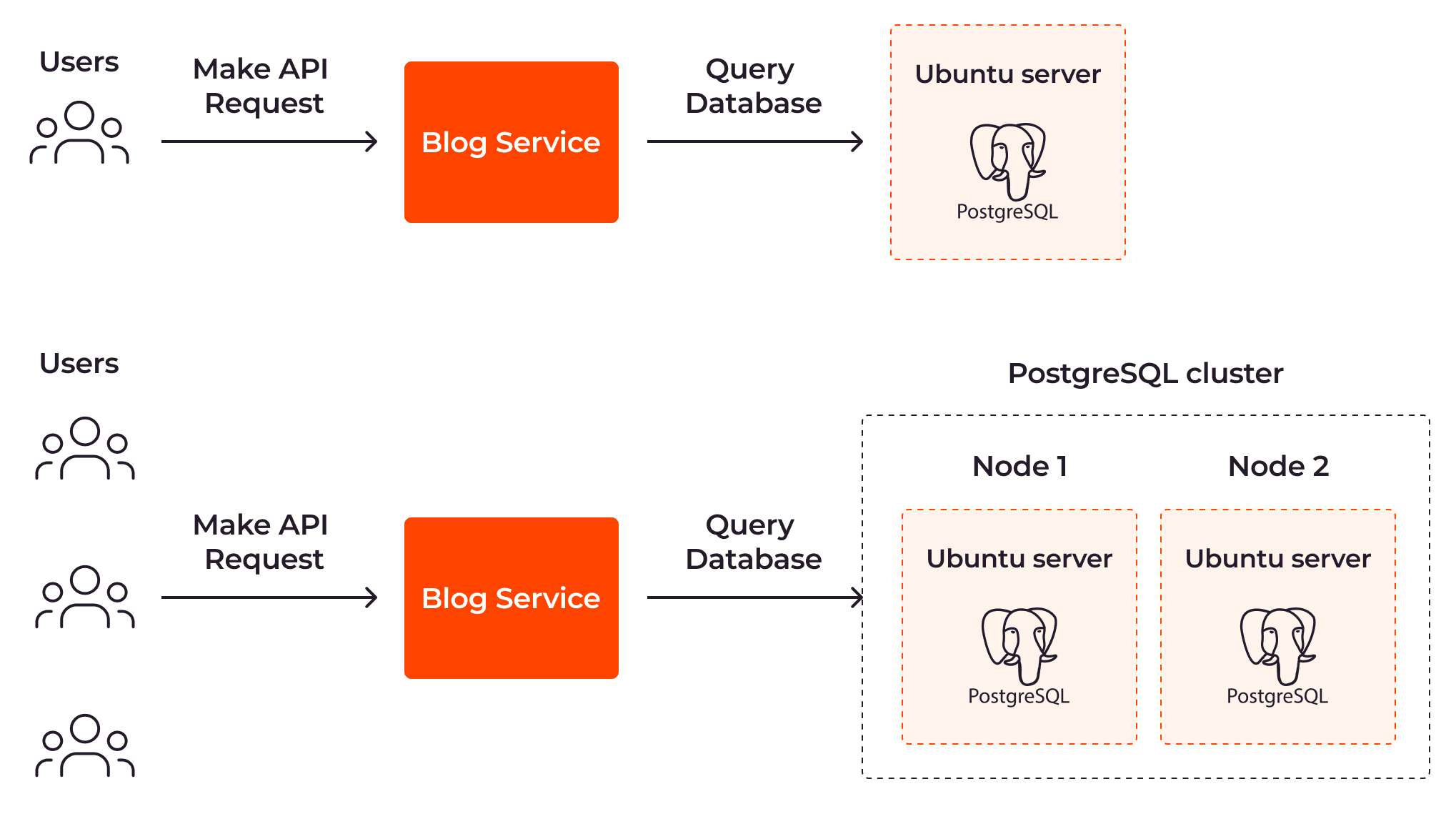
Die Begriffe „Skalierung nach außen“ und „Skalierung nach innen“ beziehen sich auf die horizontale Skalierbarkeit. Bei der Skalierung nach außen werden mehr Instanzen für Ihre Ressourcen geschaffen; bei einer Skalierung nach Innen werden existierende Instanzen entfernt.
Die horizontale Autoskalierung wird oft bei verteilten Systemen eingesetzt. Verteilte Systeme sind darauf ausgelegt, die Arbeit mit mehreren Instanzen an unterschiedlichen geografischen Standorten effizienter zu gestalten. Dank der horizontalen Autoskalierung können verteilte Systeme effizient skaliert werden und die Fehlertoleranz wird verbessert, indem die Arbeitslast auf mehrere Knoten verteilt wird.
Wie funktioniert die Autoskalierung?
Die Autoskalierung erfolgt durch eine dynamische Anpassung der Server-Ressourcen entsprechend der aktuellen Arbeitslast, die die Benutzer generieren.
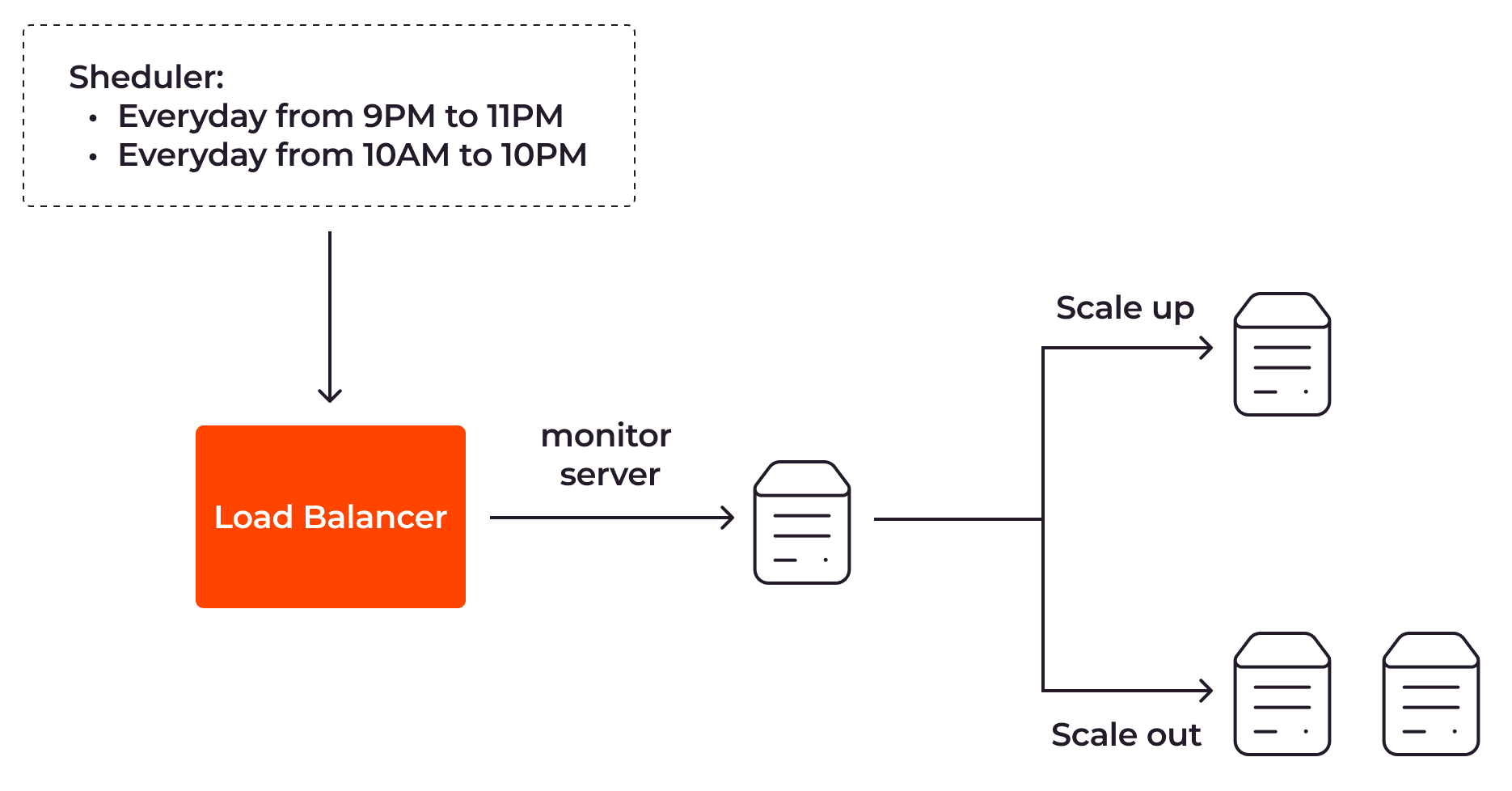
Um die Autoskalierung zu nutzen, müssen mehrere Aufgaben ausgeführt werden, darunter die Überwachung der Server, das Auslösen der Autoskalierung und das Ausgleichen des Benutzerdatenverkehrs. Sehen wir uns diese Aufgaben genauer an, um besser zu verstehen, wie die Autoskalierung hinter den Kulissen abläuft.
Die Überwachung
Die Autoskalierung verwendet Überwachungstools zur kontinuierlichen Erfassung von Server-Metriken wie der CPU-Optimierung, der Arbeitsspeichernutzung, der Antwortzeit oder des Netzwerkverkehrs. Jede Metrik bringt ihre eigenen Vor- und Nachteile mit sich. Beispielsweise lassen sich CPU-Optimierungsdaten leicht erfassen und geben üblicherweise Aufschluss über die aktuelle Arbeitslast. Diese Metrik reicht jedoch nicht für Dienste, bei denen viele Grafikkarten verwendet werden, wie beispielsweise die Modellierung. In diesem Fall sollte sowohl die GPU- als auch die CPU-Optimierung überwacht werden. Daher sollte der Mechanismus zur Autoskalierung basierend auf einer Reihe von unterschiedlichen Metriken eingerichtet werden, anstatt sich nur auf eine einzige Metrik zu beziehen.
Das Auslösen
Je nach bestehender Autoskalierungsmethode (mehr dazu im Abschnitt Autoskalierungsmethoden) löst die Autoskalierung den Skalierungsprozess entweder mithilfe von vordefinierten Terminen, Warnungen oder Ereignissen aus. Wenn Sie eine geplante Autoskalierung verwenden, wird die Skalierung der Anwendung anhand eines vordefinierten Zeitplans ausgeführt. Wenn Sie die reaktive Autoskalierung verwenden und die Schwellen für Server-Metriken überschritten werden, wird eine Warnung erzeugt, um den Skalierungsprozess einzuleiten. Wenn Sie die vorausschauende Autoskalierung nutzen (dabei handelt es sich um die Skalierungsmethode, bei der künstliche Intelligenz oder Maschinenlerndienste verwendet werden, um zu ermitteln, ob die Anwendung mehr Ressourcen benötigt), wird stattdessen ein Ereignis erstellt, der die Skalierung auslöst.
Die Anpassung
Je nach genutzter Plattform erfolgt die Anpassung der Server-Ressourcen über verschiedene Komponenten. Sehen wir uns beispielsweise Kubernetes an. Mit Kubernetes passt der Pod-Controller für die horizontale Autoskalierung (Teil der Kubernetes-Steuerebene) die Anzahl der Pods an, um die Arbeitslast der Anwendung zu verarbeiten. Um die Pods vertikal zu skalieren, passt der Pod-Controller für die vertikale Autoskalierung in der Kubernetes-Steuerebene stattdessen die CPU-Anzahl und die Größe des Arbeitsspeichers für den aktuellen Pod an.
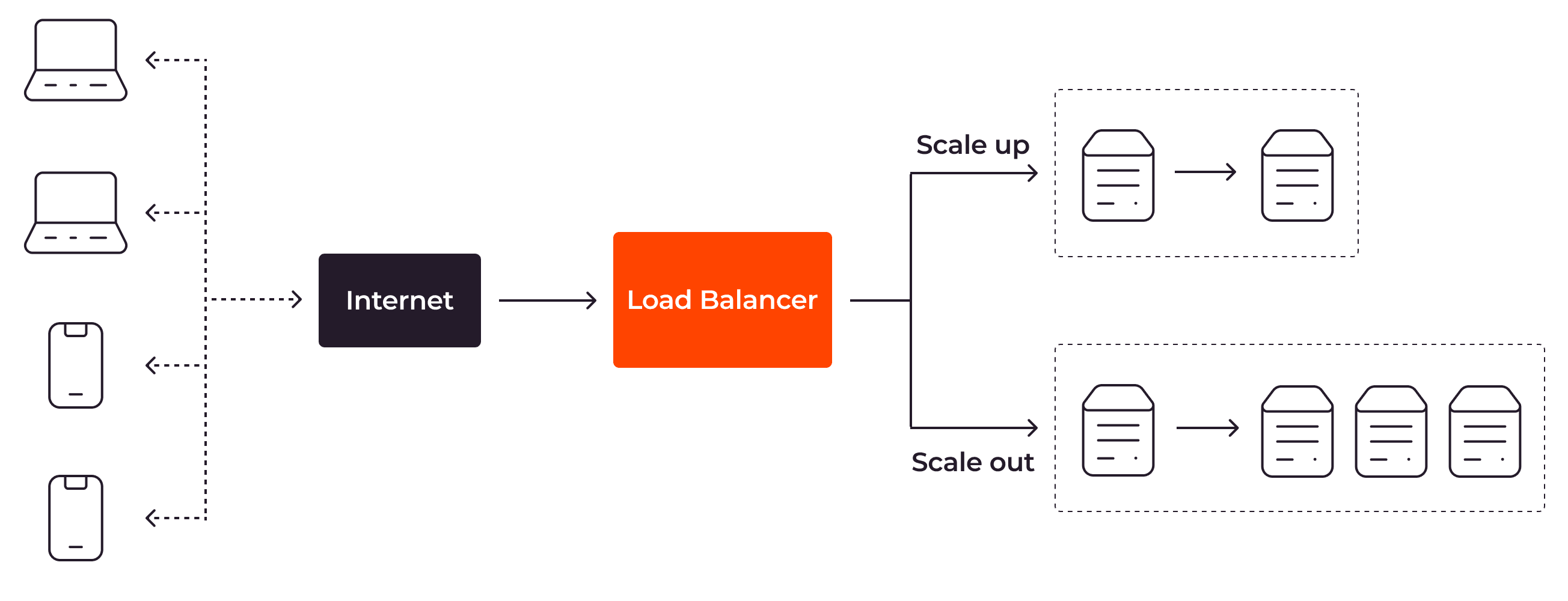
Load Balancing
Der Load Balancer verteilt die Benutzeranfragen anhand von bestimmten Regeln über mehrere Server-Instanzen hinweg. Das verhindert, dass ein einzelner Server überlastet wird.
Die Autoskalierungsmethoden
Sie können zwischen drei Autoskalierungsmethoden für Ihre App wählen: geplante Autoskalierung, reaktive Autoskalierung und vorausschauende Autoskalierung.
Geplante Autoskalierung
Bei der geplanten Autoskalierung werden Ihre Anwendungsserver entsprechend eines im Voraus vordefinierten Zeitplans skaliert.
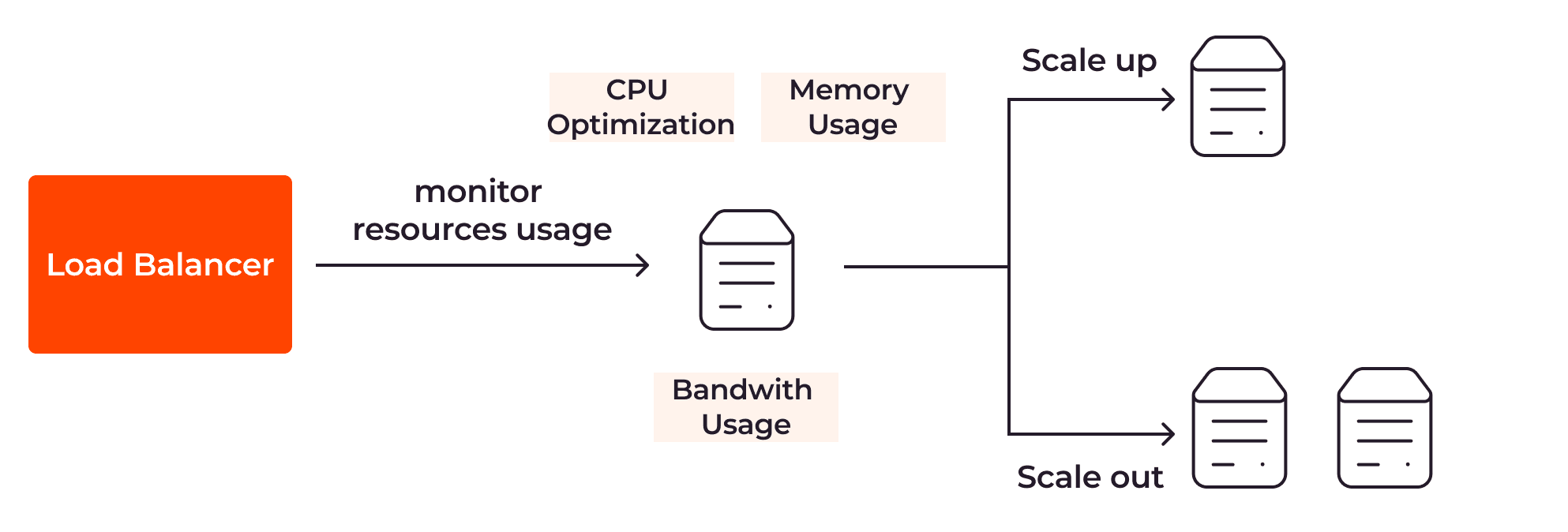
Gehen wir zum Beispiel davon aus, dass Sie eine Web-App zum Online-Shopping haben, über die Ihre Kunden Schuhe und Krawatten kaufen können. Anhand Ihrer Anwendungsprotokolle und Metriken bemerken Sie, dass Ihre Kunden an den Wochenenden oftmals zwischen 10:00 Uhr und 22:00 Uhr und unter der Woche zwischen 21:00 Uhr und 23:00 Uhr Ihren Shop besuchen. Mit der geplanten Autoskalierung können Sie Ihren Load Balancer anweisen, in diesen Zeiträumen zwei Server zu verwenden. Außerhalb dieser Zeiträume sollte eine einzige Server-Instanz ausreichen.
Die geplante Autoskalierung lässt sich leicht einrichten und eignet sich optimal für kleinere Anwendungen mit einfachen Funktionen. Für komplexe Anwendungen, die global verteilt sind und Benutzer auf der ganzen Welt haben, ist diese Art von Skalierung jedoch nicht wirksam. In diesem Fall würden wir Ihnen die reaktive Autoskalierung empfehlen.
Reaktive Autoskalierung
Bei der reaktiven Autoskalierung werden die App-Server anhand von Metriken wie der CPU-Optimisierung, der Arbeitsspeichernutzung und des verfügbaren Speicherplatzes skaliert.
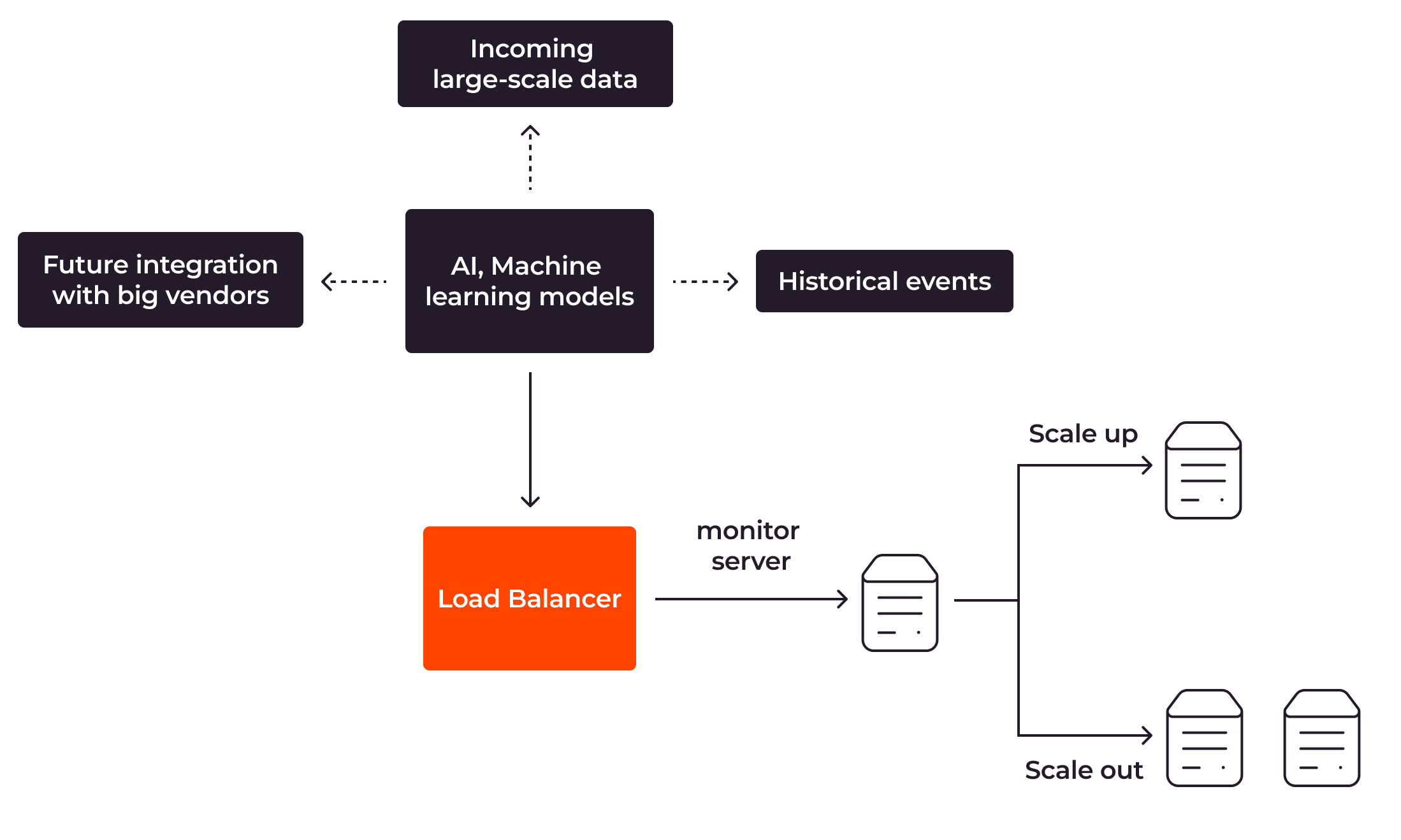
Um die reaktive Autoskalierung zu nutzen, müssen Sie die Schwellenwerte bzw. die Bedingungen für Ihre Server festlegen. Sie können zum Beispiel festlegen, dass der Load Balancer eine weitere Server-Instanz hinzufügen soll, wenn der CPU-Optimisierungswert von 90 % überschritten wird. Und wenn der Wert unter 50 % fällt, soll der Load Balancer einen Server aus der Server-Gruppe entfernen.
Die reaktive Autoskalierung ermöglicht die flexible Skalierung Ihrer Anwendung als Reaktion auf die Interaktionen der Benutzer mit Ihren Anwendungen. Die reaktive Autoskalierung bringt jedoch ein Problem mit sich: Die Server-Ressourcen können unter Umständen nicht schnell genug skaliert werden, um auf eine schnelle Zunahme der Benutzeranfragen zu reagieren. Folglich verschlechtert sich unter Umständen das Benutzererlebnis, oder es kommt gar zu Ausfallzeiten.
Vorausschauende Autoskalierung
Die vorausschauende Autoskalierung verwendet künstliche Intelligenz oder maschinelles Lernen. Es werden historische Ereignisse und Prognosetechniken eingesetzt, um die erwartete Arbeitslast und Systemressourcenanforderungen abzuschätzen.
Mit der vorausschauenden Autoskalierung kann Ihre Anwendung skaliert werden, kurz bevor es notwendig wird. Wenn sie wirksam eingesetzt wird, kann Ihre App effizient skaliert werden, ohne Leistungsprobleme oder Ausfälle zu verursachen. Jedoch ist die Einrichtung einer vorausschauenden Autoskalierung ein kompliziertes Unterfangen, das sich schwer effektiv umsetzen lässt, da die Skalierung stark von der Relevanz der gesammelten historischen Daten und von der Wirksamkeit der Prognosemodelle abhängt.
Autoskalierung von null
Die meisten Autoskalierungsmethoden erfordern von Anfang an mindestens einen Server-Knoten. Bei der Autoskalierung von null können Sie jedoch bereits ohne vorhandene Knoten loslegen, solange noch keine Server-Ressourcen erforderlich sind, und mit Knoten nach Außen skalieren, wenn der Bedarf nach Ressourcen steigt.
Die Autoskalierung von null ist hilfreich bei Anwendungsfunktionen, die eine hohe Rechenleistung und fortschrittliche Technologien erfordern, wie beispielsweise bei der Sequenzierung des vollständigen Genoms im menschlichen Körper. Wenn es sich um solche Aufgaben handelt, steigen die Kosten schnell ins Unermessliche, wenn der Server ständig betrieben werden muss, auch wenn dafür kein Bedarf besteht. Dank der Autoskalierung von null können Sie die Kosten Ihrer Infrastruktur in allen Aspekten optimieren.
Wenn Sie an der Autoskalierung von null für Ihre Anwendung interessiert sind, sehen Sie sich Function as a Service (FaaS) von Gcore an. Mit FaaS von Gcore können Sie Ihren Code in einer cloud-generierten Umgebung mit der ultimativen Flexibilität ausführen und aktualisieren. FaaS skaliert Ihre Anwendung automatisch und passt sie an die erforderliche Arbeitslast an, wenn Ihre Anwendung neue Benutzer dazugewinnt. Somit können Sie mit FaaS von Gcore optimierte Infrastrukturkosten und die Möglichkeit zur Autoskalierung von null genießen.
Die Einrichtung der Autoskalierung für Anwendungen
Beim effizienten Betrieb einer Anwendung spielen viele Komponenten eine Rolle, darunter beispielsweise Netzwerksysteme, Load Balancers, Datenbanken, Backend-Dienste oder Frontend-Dienste. Die Autoskalierung einer Anwendung erfordert all diese Komponenten im entsprechenden Ausmaß. Davon sind Datenbanken und Dienste am wichtigsten, weil sie für umfangreiche Rechenaufgaben wie das Ausführen von komplizierten Anfragen oder komplexen Modellen für maschinelles Lernen zuständig sind.
Autoskalierung für Datenbanken
Damit Datenbanken wirksam betrieben werden können, müssen ihre Leistung und ihr Datenspeicher autoskalierbar sein.
Autoskalierung zur Erweiterung der Leistungskapazitäten
Die Autoskalierung der Leistungskapazitäten ermöglicht eine vertikale Skalierung der Datenbanken, indem der Mechanismus angewiesen wird, automatisch neue Server-Ressourcen wie CPUs oder RAM zum aktuellen Datenbankknoten hinzuzufügen.
Bei verteilten Systemen sollten Sie die Datenbanken autoskalieren, indem Sie horizontale Skalierungstechniken wie Lesereplikate oder Datenbank-Clustering einsetzen. Wenn Sie Lesereplikate verwenden, werden die replizierten Datenbankknoten mit dem primären Knoten synchronisiert. Dies trägt zu einer Entlastung der Leseanfragen oder des Analyse-Datenverkehrs vom primären Knoten bei, während beim Datenbank-Clustering mehr Server zum Cluster hinzugefügt werden, damit dieses als eine einzelne leistungsfähige Datenbank agieren kann.
Autoskalierung zur Erweiterung des Speichers
Die Autoskalierung des Datenspeichers gewährleistet, dass der Datenspeicher automatisch erweitert wird, wenn der Speicherplatz zum Speichern von neuen Daten nicht mehr ausreicht. Wenn Sie beispielsweise mit einem großen Hadoop-Cluster arbeiten, um strukturierte und unstrukturierte Daten zu speichern, können Sie den Autoskalierungsmechanismus anweisen, mehr Speicherknoten zum bestehenden Cluster hinzuzufügen, wenn der aktuelle Speicherplatz bald ausgelastet ist.
Autoskalierung für Dienste
Wenn Sie die Autoskalierung für Backend- oder Frontend-Dienste verwenden möchten, ist der Zugriff auf die Anwendung und die Server-Metriken wie die Antwortzeit, die Bandbreitennutzung oder die Speichernutzung erforderlich. Basierend auf diesen Metriken können Sie die Autoskalierung auslösen, indem Sie mehr Server-Ressourcen direkt zum bestehenden Server hinzufügen. Alternativ können Sie Ihre Anwendung horizontal skalieren, indem Sie mehr Dienstinstanzen für mehr Benutzeranfragen erstellen.
Die Vorteile der Autoskalierung
Die Autoskalierung Ihrer Anwendung ist eine anspruchsvolle Aufgabe, die Überwachungs-, Auslöse- und Load-Balancing-Prozesse für unterschiedliche Datenbanken und Dienste erfordert. Wenn Sie sich jedoch die Mühe machen, werden sich die Ergebnisse sehen lassen.
Kostenoptimierung
Wenn Sie die Möglichkeit haben, Ihre Anwendung nach innen bzw. nach unten zu skalieren, wenn weniger Anfragen an den Server gesendet werden, dann können Sie die Server-Kosten in Grenzen halten, indem Sie verschwendete Kosten reduzieren. Dies ist sowohl für Startup-Unternehmen mit begrenzten Mitteln als auch für globale Unternehmen mit Millionen von Benutzern ein entscheidender Faktor.
Reduzierte Ausfälle
Dank der Autoskalierung können sofort neue Server-Instanzen hinzugefügt werden, wenn sich auf den vorhandenen Servern Leistungsprobleme bemerkbar machen. Folglich müssen Endbenutzer keine Ausfälle mehr in Kauf nehmen, da der Server nicht mehr manuell skaliert werden muss.
Leistungsoptimierung
Die Autoskalierung verbessert die Leistung Ihrer Anwendung, indem Server-Ressourcen hinzugefügt werden, bevor Probleme auftreten.
Niedrigerer Energieverbrauch
Indem Server-Ressourcen nach innen bzw. nach unten skaliert werden, wenn sie nicht benötigt werden, reduziert die Autoskalierung den Stromverbrauch und die Netzwerkbandbreite. Sie verlängert zudem die Lebensdauer der Serveranlagen. Folglich kann man durchaus behaupten, dass die Autoskalierung einen Beitrag zur Nachhaltigkeit in der Welt der Technik leistet.
Automatisierung
Die Autoskalierung ermöglicht eine automatische Skalierung Ihrer Anwendung ohne menschliches Eingreifen. Dadurch müssen die Anwendungsmetriken und Systemressourcen nicht mehr kontinuierlich überwacht werden, was zeitaufwändig und mental anstrengend ist. Stattdessen können Sie nun Ihre freie Zeit mit anderen Aufgaben verbringen und beispielsweise die Infrastruktur für ein neues Projekt einrichten.
Bewährte Verfahren der Autoskalierung
Um von den Vorzügen der Autoskalierung zu profitieren, sollten Sie diese fünf bewährten Verfahren befolgen:
#1 Vergewissern Sie sich, dass sich der minimale und der maximale Knotenwert für die Autoskalierungskonfiguration unterscheiden. Wenn Sie den Autoskalierungsmechanismus konfigurieren, müssen Sie üblicherweise die Mindest- und Höchstanzahl der Knoten für Ihre Server definieren. Indem Sie die minimale Anzahl an Knoten festlegen, sorgen Sie dafür, dass Ihre Anwendung immer ausreichend Systemressourcen für deren Betrieb hat, auch wenn nur ganz wenige Anfragen an den Server gesendet werden. Indem Sie die maximale Anzahl an Knoten festlegen, stellen Sie sicher, dass das System nicht zu viele Server hinzufügt, wenn Anwendungsfehler oder Sicherheitsverletzungen wie DDoS-Angriffe auftreten. Wenn die minimale und maximale Anzahl an Knoten auf denselben Wert festgelegt sind, wird Ihre Autoskalierung nicht funktionieren, da die Anzahl der Knoten unabhängig von der Arbeitslast des Servers immer gleich sein wird.
#2 Wählen Sie die passenden Leistungsmetriken entsprechend Ihrer Anwendungsanforderungen. Sie müssen die geeigneten Metriken für Ihre App verwenden, damit die Autoskalierung effizient arbeitet. Dies ist besonders bei der reaktiven Autoskalierung auf Grundlage der Anwendungs- und Server-Daten wie der CPU-Optimierung, der Antwortzeit oder der Speichernutzung wichtig. Zum Beispiel sollten bei Anwendungen für Echtzeit-Spiele die Metriken der gleichzeitig teilnehmenden Spieler sowie andere allgemeine Metriken wie die CPU-Optimierung oder Speichernutzung zurate gezogen werden, damit der Autoskalierungsmechanismus effizient betrieben werden kann.
#3 Legen Sie eine konservative Schwelle für Ihre Metriken fest und behalten Sie dabei die Pufferung im Hinterkopf. Das Auslösen der Autoskalierung geht üblicherweise mit einer Verzögerung einher, somit ist es immer empfehlenswert, bei der Festlegung der Schwellenwerte die Pufferzeit zu berücksichtigen. Bei Anwendungen mit einem hohen Datenverkehr sollten Sie beispielsweise die CPU-Optimierung auf 80 % einstellen, sodass die vorhandenen Server die Arbeitslast weiterhin bewältigen können, auch wenn bei der Autoskalierung Ihrer Server eine Verzögerung auftritt.
#4 Richten Sie Meldungen für die Autoskalierung ein. Legen Sie Meldungen für die Autoskalierung an und erhalten Sie Benachrichtigungen, wenn Probleme auftreten. Sie sollten beispielsweise eine Meldung erhalten, wenn der Autoskalierungsmechanismus in kurzer Zeit neue Server hinzufügt, um auf eine steigende Anzahl an Anfragen zu reagieren. Wenn Ihnen diese Information vorliegt, können Sie schnell einen potenziellen DDOS-Angriff erkennen und die erforderlichen Schritte einleiten.
#5 Wählen Sie die reaktive oder vorausschauende Autoskalierung anstatt einer geplanten Autoskalierung. Die geplante Autoskalierung lässt sich zwar einfach einrichten, doch sie kann auch schnell Probleme verursachen und zu Leistungseinbußen oder Ausfällen führen, wenn unerwartete Ereignisse auftreten. So könnte beispielsweise ein lokaler Online-Shop vor einem anstehenden Fußballspiel eine unerwartet hohe Nachfrage nach Fußball-T-Shirts verzeichnen.
Häufig gestellte Fragen zur Autoskalierung
1. Was ist der Unterschied zwischen der Autoskalierung und Load Balancing?
Diese beiden Prozesse haben zwar einige Funktionen gemeinsam, dennoch unterscheiden sie sich voneinander. Bei der Autoskalierung handelt es sich um die Einrichtung einer automatischen Skalierung für Ihre Anwendung. Load Balancing ist nur ein Schritt in diesem Prozess: die Verteilung der Arbeitslast über mehrere Server-Instanzen hinweg entsprechend festgelegten Regeln.
2. Was ist der Unterschied zwischen der Autoskalierung und einer hohen Verfügbarkeit?
Mit der Autoskalierung kann Ihre App automatisch skaliert werden. Folglich müssen die Benutzer keine Ausfälle der Anwendung in Kauf nehmen, da Ihre App schnell und effizient skaliert werden kann. Eine hohe Verfügbarkeit sorgt dafür, dass Ihre Anwendung live und aufrufbar ist. Somit müssen sich die Benutzer nicht mit Ausfällen auseinandersetzen. Die Autoskalierung ist einer der Faktoren, die zu einer hohen Verfügbarkeit führen.
3. Kann ich eine unbegrenzte Autoskalierung für meine App anwenden?
Mit der horizontalen Skalierung können Sie Ihre App fast unbegrenzt skalieren, da Sie sich auf Tausende oder gar Millionen von Server-Instanzen verlassen können. Bei der vertikalen Skalierung sind Sie an die Ressourcenbegrenzung eines einzelnen Servers gebunden.
4. Ist es möglich, die Autoskalierung bei einem zentralisierten System zu nutzen?
Ja, sie können die Autoskalierung bei einem zentralisierten System verwenden, wenn Sie einen vertikalen Ansatz nutzen. Beachten Sie jedoch, dass die Skalierung auf einem zentralisierten System im Gegensatz zu einem verteilten System nur begrenzt möglich ist.
Fazit
Dank der Autoskalierung kann Ihre Anwendung die entsprechende Arbeitslast flexibel, reaktiv, vorausschauend und ohne menschliches Eingreifen verarbeiten. Zudem können Sie dadurch Ihre Infrastrukturkosten optimieren ‒ ein wichtiger Faktor für die Betriebseffizienz Ihres Unternehmens.
Wenn Sie Kubernetes für die Orchestrierung Ihrer Anwendungscontainer nutzen, werfen Sie einen Blick auf Managed Kubernetes von Gcore. Mit Managed Kubernetes von Gcore können Sie innerhalb von wenigen Minuten die Autoskalierung Ihres Kubernetes einrichten, damit Sie Ihre Zeit mit der Entwicklung und Bereitstellung von neuen Funktionen verbringen können, anstatt das Kubernetes-Cluster von Grund auf manuell konfigurieren zu müssen. Wenn Sie schnell eine neue Funktion implementieren möchten, um die Funktionalität Ihrer Anwendung zu verlängern ‒ beispielsweise einen Benachrichtigungsservice zum Senden von Nachrichten an Slack, wenn sich ein neuer Benutzer registriert ‒, informieren Sie sich über Function as a Service von Gcore. Mit Gcore FaaS können Sie Ihren Code in einer vorgefertigten Umgebung ausführen und aktualisieren, damit Sie Ihre neue Funktion bereitstellen können, um Ihre Geschäftsanforderungen im Handumdrehen zu erfüllen.
Sind Sie an Gcore Managed Kubernetes und Gcore FaaS interessiert? Jetzt kostenlos testen.
Ähnliche Artikel
Die KI-Infrastruktur, das Rückgrat der modernen Technologie, hat einen bedeutenden Wandel erfahren. Ursprünglich war sie in traditionellen On-Premises-Konfigurationen verwurzelt, hat sich allerdings zu dynamischeren, cloudbasierten und Edge




Melden Sie sich für unseren Newsletter an
Erhalten Sie die neuesten Branchentrends, exklusive Einblicke und Gcore-Updates direkt in Ihren Posteingang.