
Virtualization allows multiple operating systems and applications to run on a single physical server, optimizing hardware resources and simplifying management. It comprises two interwoven technologies: containers and virtual machines. While containers are known for their speed, efficiency, and portability, VMs offer robust isolation and security features. This article explains and compares the technologies so you can understand their fit-for-purpose uses and make informed choices about your organization’s infrastructure needs.
Cliff Notes: What’s the Difference Between Containers and VMs?
In the realm of virtualization technologies, containers and virtual machines (VMs) offer distinct approaches to application isolation, resource utilization, and system architecture. Containers leverage OS-level virtualization for high performance and efficient resource sharing, whereas VMs operate on hardware-level virtualization, encapsulating a full guest OS for stronger isolation. These fundamental architectural differences result in varying levels of performance, startup time, and resource utilization.
Both technologies have their own merits and drawbacks when it comes to enterprise deployment, security protocols, and scalability. To understand the pros, cons, and use cases, we first need to look at each technology and its architecture in depth, and then at the end of the article we’ll offer a side-by-side comparison.
What Are Containers?
Containers are virtualized, isolated application packages; they contain everything needed to run a piece of software, including code, system tools, libraries, and settings (called dependencies.) They solve the critical software development and deployment problem of ensuring that software can run properly on different computing environments. This makes the software reliable for end users, an essential feature of any software release. To serve their purpose, containers are portable, meaning they can run across different development environments so that developers can test software on different environments without worrying about conflicts with the underlying system.
Benefits of Containers
Containers have been widely adopted for the following benefits:
- Faster startup: Containers don’t need an operating system to start running. This means they can start almost instantly.
- Efficient resource utilization: Containers utilize their host operating system’s kernel (the core part of the computer’s operating system.) This makes them lightweight and resource-efficient as they do not require the extra cost of a separate operating system installation for each container. This saves space and resources, helping things run fast and smoothly.
- Portability: Containers encapsulate entire applications and their dependencies in a single file, allowing developers to build applications just once and then run them in multiple environments. This portability ensures consistent behavior when containers are moved between development, testing, and production environments, providing flexibility and reducing deployment-related issues.
- Isolation: Multiple containers (and their dependencies) can share a single OS kernel, while running isolatedly in a way as to ensure that the failure of a container does not affect the function of others within the same environment. Dedicated security tools, such as OS security isolation tools, are also available to pinpoint faulty container parts for efficient remediation.
- Scalability: You can run several similar containers to create multiple application instances simultaneously. Containerization also allows running only the containers needed for an application to function efficiently at a specific time. As such, containers can be scaled up or down depending on application load. These features make containers highly scalable and cost-effective.
How Do Containers Work?
Containers isolate applications and their dependencies into portable, self-contained units that can be operated anywhere. A container image—an immutable (unchangeable) file with executable code—creates a container. Container images are created using a Dockerfile (or similar configuration files) and stored in container repositories. When a container is instantiated, the image is pulled from the repository onto the host machine. After that, the image is verified, and any missing layers are fetched from the registry. Once the environment is set up, the runtime starts the container and runs the specific command defined in the image.
But What Is a Runtime?
A container runtime is a software package that leverages a container’s host OS to run the container. It creates the necessary environment for the execution of the container, including required namespaces and control groups (usually referred to as cgroups.) Both namespaces and cgroups facilitate resource efficiency: namespaces organize code into groups, and cgroups limit the utilization of resources. The container then runs within the isolated environment, utilizing the resources and namespaces provided by the host operating system.
Container Architecture
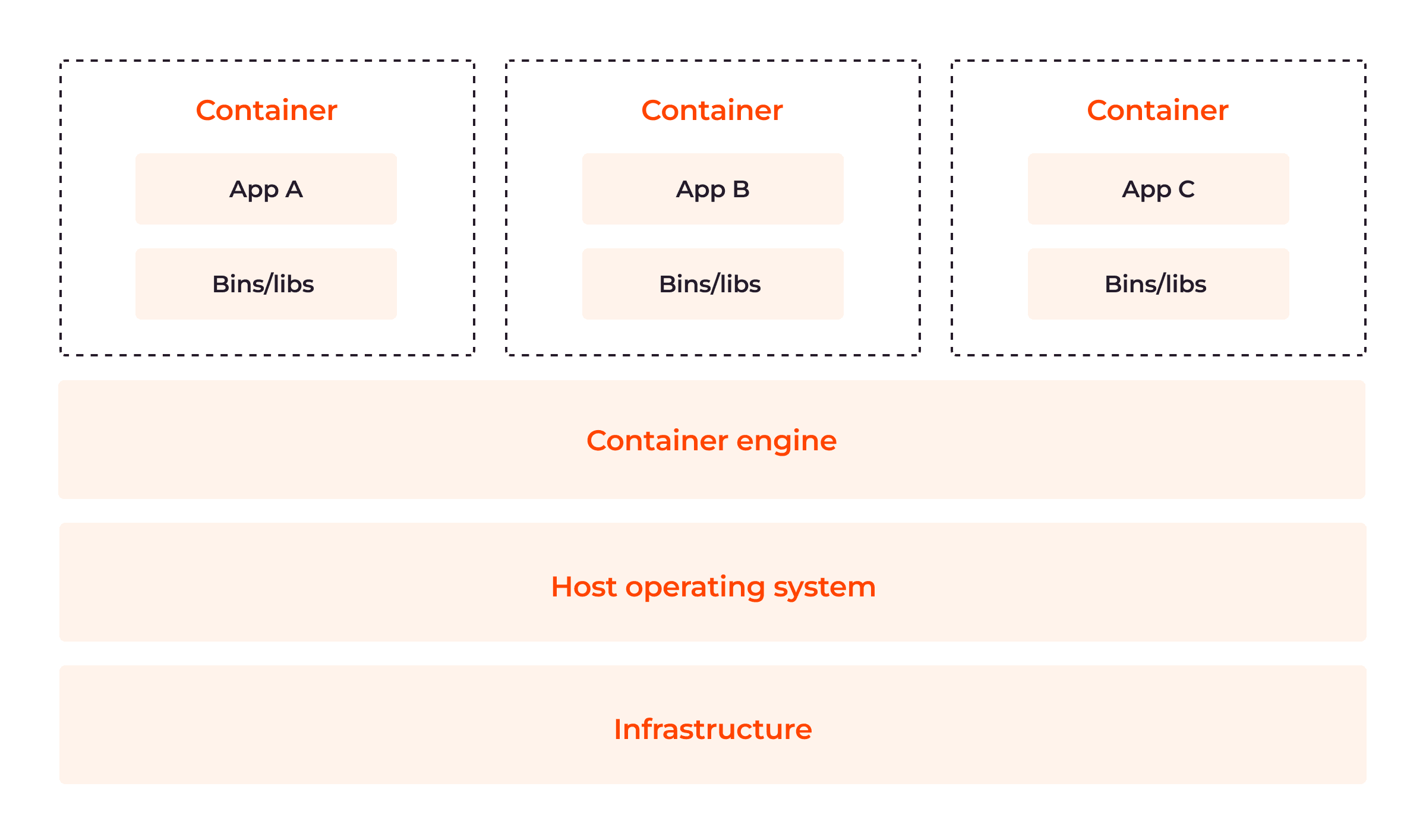
Containers have six major components: container runtimes, container images, registries, container orchestration platforms, control groups and namespaces. Let’s take a look at each in turn.
Container Runtimes
Container runtimes or engines are software components that are responsible for pulling container images from a registry, setting up the necessary execution environment, managing and executing containers on a host machine, and monitoring containers within the cluster environment. The container runtime also orchestrates the creation and execution of containers.
Container Images
Container images are lightweight, immutable snapshots that contain application codes, dependencies, configuration files, libraries and runtime environments required to run applications. Images have one or more layers built on a parent or base image. They are usually built using Dockerfiles, a text file specifying the instructions to create a layered image representing the application and its dependencies.
The layers of container images make their components and configurations reusable. So, developers do not have to create new ones from scratch whenever images are required. When built optimally, these layers can help to minimize container size and enhance performance.
Images (and other artifacts) make up repositories. Container images have names and tags for easy pushing and pulling. A repository and a tag define an image’s name and allow for easy sharing of container images. A single repository can contain several container images. To modify these read-only images, developers must create a layer—containing all changes made—on top of the parent image.
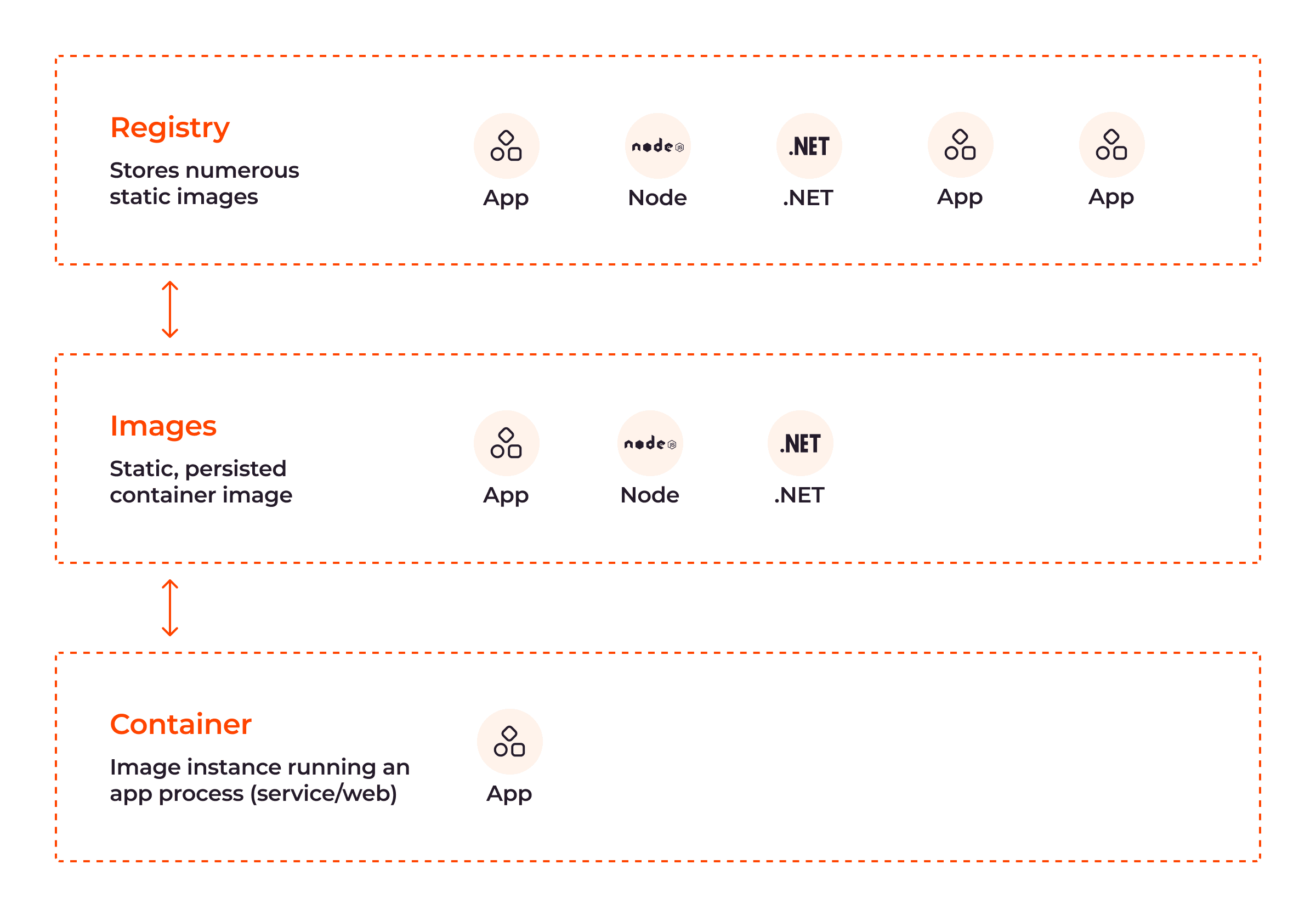
As shown in the above image, container images are stored in registries and can be pulled onto a host machine to create and run containers.
Registries
Registries are central repositories that store and distribute container images to ensure their efficiency. Registries can be public or private.
- Public: This is a vast collection of prebuilt container images developers can use. DockerHub, a general catalog of container images, is an excellent example of a public container registry.
- Private: This is a registry where organizations store and manage their own custom container images for privacy and greater control over them.
When an image is pulled from a registry, it is stored locally on the host machine to ensure that containers can be created without a network connection to the registry.
Container Orchestration Platforms
Container orchestration is an approach to automating and managing the deployment of containers to enhance application performance. Platforms—such as Kubernetes—are used to automate the deployment, scaling and scheduling of containers through several features, such as automated scaling, load balancing, and health monitoring.
The container registry, runtime and orchestration platform are three important components of the container orchestration setup required for managing containers throughout the software development life cycle.
Control Groups (cgroups)
The control group is one of the two main kernel OS features of containers, the other being namespaces (explained below.) cgroups provide the following functions:
- Resource allocation: cgroups limit and prioritize resources (including CPU usage, memory, disk I/O, and network bandwidth) allocated to containers.
- Process control: Because they can instantiate huge volumes of processes concurrently, containers are attack-prone. This is done to influence the volume of processes and deplete container resources. cgroups can be used to start, stop or restrict the number of ongoing processes, thereby preventing attacks and improving application performance.
Namespaces
Namespaces provide process-level isolation within the OS, ensuring that only the kernel OS gets shared; all other resources are isolated between containers. Namespaces enable containers to run with their own file system views, network stacks, process trees, and user privileges. Containers need their own system views, network stacks, process trees and user privileges to isolate themselves from other systems within the environment. For example, containers are typically given limited access to devices on the host, but with raised privileges, they can access the same capabilities as the host OS, ensuring container isolation.
Each container has its associated namespace that gives the illusion of individuality. There are four major namespaces used to allocate resources to containers:
| Namespace | Function |
| PID namespace | Ensures each container has its unique set of process IDs |
| Network namespace | Allows containers to have their own network interface, IP address, and routing table |
| Mount namespace | Allows containers to have their own root file system while avoiding conflicts with files from other containers |
| User namespace | Provides user and group isolation |
The image below shows the relationship between the components of the container architecture explained above:
Use Cases for Containers
Containers have gained significant popularity due to their versatility and applicability across various industries. Let’s explore some of their notable use cases.
Microservices Security
Microservices are an architectural approach to software development and deployment, where applications comprise small independent and specialized services loosely connected via APIs (Application Programming Interfaces) and REST (representational state transfer) interfaces. Microservices deployed directly on a host OS are less secure because security vulnerabilities can easily spread in the OS layer. In contrast, containerized microservices are more secure and efficient, as containers reduce their attack surfaces, allow for independent patching, and offer control over resource allocation.
Application Packaging and Distribution
Since a container image hosts the application and its dependencies, it is easy to deploy across different environments. You only need to spin a YAML declaration of the container image and deploy it to any environment you choose. This eliminates the “works on my machine” problem often encountered with traditional deployments.
Continuous Integration and Continuous Deployment (CI/CD)
Developers leverage container images to facilitate CI/CD. CI is the practice of continuously making changes to software code and testing for its semantic correctness via an automated process. In-depth integration tests can be expensive, underscoring the value of containerization.
By encapsulating their applications into containers, developers can instantiate them from images throughout different stages of the development lifecycle. This approach, spanning from unit testing to staging and production, saves costs associated with setting up and running CI/CD servers while boosting efficiency.
Hybrid and Multicloud Environments
With containers, applications can be easily migrated across different cloud providers or on-premise infrastructure without extensive application reconfiguration.
Machine Learning, Edge Computing, and Internet of Things
This is another important use case of containers. Containers have increasingly been adopted in edge computing and internet of things (IoT) because they allow for lightweight deployment and enable different services to run on individual containers, thereby reducing the possibility of issues in one service affecting other services. Additionally, with the help of containerized environments, data scientists can ensure experiments are reproducible, easily share their work, and create consistent development environments for machine learning, artificial intelligence, and collaborative projects.
Now that we’ve covered containers, let’s turn to virtual machines.
What Are Virtual Machines?
A virtual machine (VM) is a virtualized emulation of an entire computer system within a host machine, including its hardware and operating system. It provides an environment that isolates the guest OS and applications from the underlying hardware and host operating system to prevent vulnerabilities of one component from affecting the entire cloud environment. A VM is built on a hypervisor, a software layer responsible for creating VMs and managing/allocating the physical resources of a host machine to virtualized guest systems based on their relative importance.
Benefits of Virtual Machines
Virtual machines offer several benefits:
- Full isolation: A VM runs its own guest OS and application within its isolated environment in a way that ensures applications within one VM do not interfere with or impact applications in another VM.
- Security: VMs provide strong security boundaries due to their full isolation feature. Compromised applications or vulnerabilities within one VM are generally contained within that specific VM and do not affect other VMs or the host system. This isolation helps protect sensitive data and mitigates the security risks associated with shared infrastructure.
- OS flexibility: VMs allow different operating systems—including various versions of Windows, Linux and macOS—to be run on the same physical hardware. This flexibility enables organizations to run applications requiring specific operating systems or legacy software compatibility.
- Resource partitioning: VMs enable the partitioning of physical resources, such as CPU, memory, and disks, among different virtual machines. This facilitates efficient workload management.
- Snapshot capabilities: VMs offer the ability to take snapshots that capture the state of a VM at a specific point in time. These snapshots can be used for backup, disaster recovery, or testing.
- Migration capabilities: VMs allow for seamless migration between host machines without service disruption, allowing IT teams to shift workloads or move between servers and machines. Migration is commonly done when VM host systems, including software and hardware, require patching or updating.
- Hardware abstraction: VMs provide hardware abstraction by rendering physical hardware unnecessary, which helps to ensure software compatibility across different servers, as VMs shield applications from variations in hardware configurations. This helps to save costs associated with physical storage.
How Do Virtual Machines Work?
VMs work as fully isolated guest systems with their own operating systems and applications. They leverage the hypervisor to create and manage multiple isolated virtual environments on a single physical host. When a virtual machine is powered on, the hypervisor intercepts and translates the guest operating system’s instructions to the appropriate physical hardware.
This is enabled by hardware virtualization techniques, such as binary translation and hardware-assisted virtualization. Binary translation is a software virtualization technique in which an interpreter is used to translate the binary machine language code of an application into that of the host OS. Meanwhile, hardware-assisted virtualization involves using a computer’s physical components to provide the software architectural support that VMs need to function properly. Both techniques help to appropriately link and facilitate communication between VMs and the host OS.
Virtual Machine Architecture
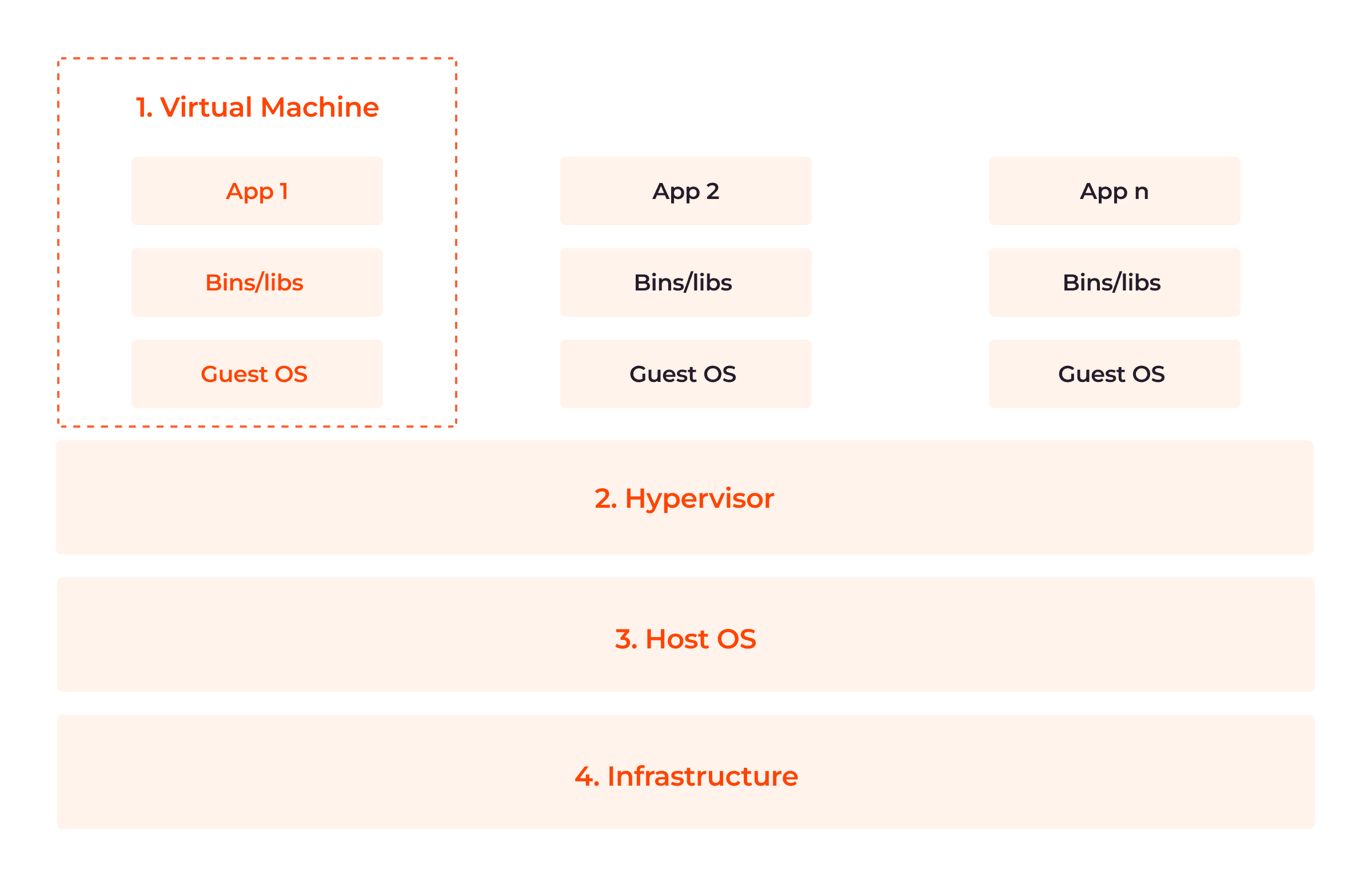
VMs are built on physical machines, with their primary component being a hypervisor, a host server that allows VMs to access the required computing resources. The image below illustrates the four parts of the VM architecture.
Now, let’s detail these four components.
1. Virtual Machine (App, Bins/Libs, Guest OS)
Virtual machine components include virtualized applications and libraries presented to a guest OS. Each virtual machine has its own guest operating system, which can differ from each other, so that multiple operating systems can coexist on the same infrastructure.
2. Hypervisor
A hypervisor, also known as a virtual machine monitor (VMM,) is a software layer that enables the creation and management of VMs on the physical host machine/infrastructure. There are two types of hypervisors:
- Type 1 (bare metal hypervisors) that run directly on the host machine’s hardware, without the need for an underlying OS. They have direct access to the hardware resources and manage the virtual machines at a low level.
- Type 2 hypervisors run as applications on top of the existing OS. They rely on the host operating system to manage the hardware resources and provide a layer of virtualization on top of it.
3. Host Operating System
The host OS exists between the hypervisor and the infrastructure. They provide isolation between the virtual machine and the components of the infrastructure by limiting the data that flows from one to the other. This enhances both host and guest security.
4. Infrastructure
The infrastructure is the underlying hardware on which virtual machines are created and executed. It provides the necessary computing resources, such as CPU, memory, storage, and network.
How Are Virtual Machines Used?
Virtual machines are used across various industries and use cases, including the following:
Legacy Application Support
Virtual machines are commonly used to support and maintain legacy applications that were originally designed for an older OS or for specific hardware configurations. By running legacy applications on virtual machines, organizations can preserve the functionality and dependencies of these applications while modernizing their underlying infrastructure.
Multitenancy and Cloud Computing
VMs are used extensively in cloud environments where multiple customers share the same physical infrastructure. This is because they ensure cost-effectiveness and provide isolation, security, and customization while maximizing resource utilization for the cloud provider.
Development Environments
VMs provide convenient and isolated environments for developers to work on different projects with varying software requirements. Multiple VMs can be set up, each running a different development or testing stack, allowing for easy setup, experimentation, and reproducibility.
Testing and Debugging
VMs provide a controlled and reproducible environment for software testing and debugging. Testers can create multiple VM snapshots to capture various points in the software testing process, facilitating easy rollbacks, bug reproduction and debugging. Rollbacks involve reducing VMs to previous states to erase (or reduce) errors in current states, and bug reproduction is the process of reproducing a bug in a software to visualize how it got there in the first place. Both procedures facilitate debugging, patching and data retrieval. VMs offer a convenient way to test software compatibility across different OSes, reducing the need for multiple physical systems.
Security Research and Disaster Recovery
VMs are used for security research as well as vulnerability and malware analysis. Researchers can isolate and analyze potentially harmful applications or websites within VMs to prevent damage to host systems or networks.
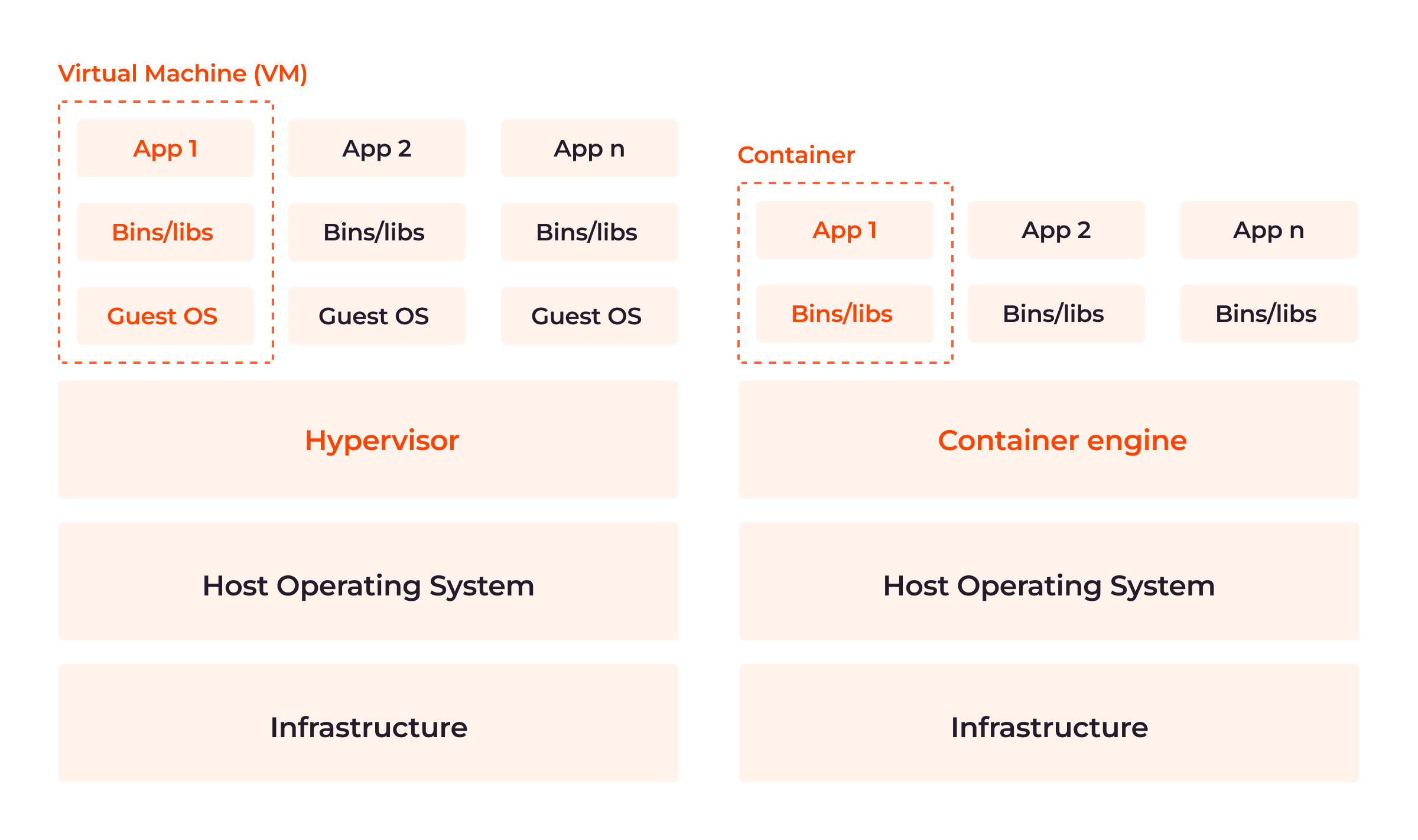
What Are the Differences Between Containers and Virtual Machines (VMs)?
Although both are powerful and efficient, one has an edge over the other. As shown in the image below, the major architectural difference between both containers and VMs is the presence or absence of a guest operating system in the virtualization layer.
Consider the table below for a close-range comparison:
| Features | Containers | Virtual Machines |
| Architecture | Application- or OS-level virtualization technology. Containers share the host OS kernel but have separate user spaces. | Infrastructure or hardware-level virtualization technology. Each VM has its own kernel, file system, and memory allocation. |
| Performance | Perform better than VMs because they share the host operating system kernel. Lower overhead and improved performance. | Reduced performance compared to containers, due to the overhead of running a full guest OS alongside the host OS. |
| Resource utilization | Efficient resource utilization due to leveraging their host’s resources directly. | May be less efficient. Require dedicated resources for each virtual instance, including a separate guest OS. |
| Latency | Lower latency as they directly access the host hardware, bypassing virtualization layers. | Introduce additional layers of virtualization, leading to increased latency compared to containers. |
| Startup Time | Offer near-instant startup times. | Longer startup times because they need to boot a complete guest OS for each instance. |
| Isolation | Use OS-level isolation which is not as strong as hardware-level virtualization. | Provide full isolation since each VM runs on a separate hypervisor. |
| Portability | Highly portable, allowing for consistent behavior across different systems. | Less portable as they may require configuration changes to work in different environments due to differences in hardware and OS versions. |
| Security | Potential for security vulnerabilities due to the shared host OS kernel. Runtimes provide features like namespaces and control groups help to mitigate security risks. | Higher level of security due to strong isolation between each VM. |
| Flexibility | Greater flexibility in terms of resource allocation and scaling. | Limited flexibility; they require a fixed allocation of resources. Changes to resource allocation require adjusting VM configuration. |
| Density | Due to their lightweight nature, containers can be packed more densely on a host machine. | Less dense due to resource overhead. |
| Efficiency | More efficient in terms of storage and memory utilization. | Require additional storage and memory, since each instance requires a full guest OS alongside the application. |
| Deployment complexity | Simplified deployment process using container images. | More complex deployment process, involving provisioning and configuring a guest OS on each virtual instance. |
| Use cases | Well-suited for microservices architecture, continuous integration/continuous deployment, scaling applications, and managing distributed systems. | Commonly used for running legacy applications, testing different operating systems, creating isolated OS environments, and development sandboxes. |
Choosing Between Containers and Virtual Machines
Although both containers and VMS have revolutionized application development and deployment, your choice will depend on your applications’ specific use case, performance requirements, and isolation needs. Containers and VMs can be combined with containers running inside VMs to leverage the benefits of both technologies. To do this, create a virtual machine with a distinct hardware configuration and install an OS within it. Then, install a container runtime on the OS.
However, it is critical to note that containers lend themselves better to modern practices and use cases and offer portability that is important for multi-cloud environments. For instance, containers are more lightweight and use far fewer resources than virtual machines. If a physical server can host only ten virtual machines, it could host twenty containers or more.
Conclusion
Virtualization is undergoing a staggering rise in both popularity and market size, with its value currently estimated at $40–62 billion and expected to reach over $120 billion in revenue by 2027 according to Statista. As competition stiffens, selecting the right virtualization technology can give decision makers a competitive advantage over their counterparts.
Gcore’s Managed Kubernetes minimizes the complexity of using containers and empowers organizations to effortlessly orchestrate containerized applications, ensuring scalability, high availability, and simplified management, all without compromising security or performance.
Related articles





Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial

Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.