
Businesses are moving to clouds.
According to Gartner, the global cloud services market reached $257.5 billion in 2020 and continues to grow.
Cloud providers typically offer three service models: IaaS, PaaS, and SaaS. Let’s figure out what these abbreviations mean and how to choose the right solution.

IaaS
IaaS stands for Infrastructure as a Service.
Almost every company now needs its own IT infrastructure (computers and servers where data is stored and processed) and the tools necessary for connecting that infrastructure to a single network. You can purchase equipment and service it yourself. Or you can rent computing power through a cloud.
The second option is called IaaS. Instead of setting up your infrastructure, monitoring its state, and constantly updating it, you take resources on lease and use them for your own purposes virtually.
IaaS can be compared to virtual “computers”. You get computing power and can use it however you want. In this case, you pay only for the resources consumed, and the provider monitors the state of the equipment.

IaaS features
- You rent a virtual or physical dedicated server and can install any programs on it or perform any operations.
- The provider provides special settings for managing your resources in the cloud. For example, you can divide resources into projects within an account and define access rules for different users.
- The load between servers can be evenly distributed using balancers.
- Files and backups can be placed in the cloud storage. You will have instant access to your data. You can also store an almost unlimited amount of information.
- Disaster recovery is available. Providers provide services that create backups of your infrastructure and automatically transfer the load there in case of failure. Thus, even in the case of a major disaster, your data won’t be lost, and access will be restored in a few minutes.
IaaS pros

1. Significant savings. If you’re setting up your own infrastructure, you will need to upgrade the equipment, hire employees to maintain it, and pay for rented premises and licensed software. This can all get quite expensive. But at the same time, for some tasks you don’t need the entire infrastructure, and some of the equipment will be idle from time to time.
If you choose IaaS, the provider takes care of the equipment maintenance and upgrades. You pay only for the resources consumed.
2. Easy scalability. With IaaS, you can increase your computing power in just a few clicks. This is especially useful when there is a surge in traffic, for example, during sales, promotions, or explosive business growth.
3. Flexibility. You can use the processing power however you want with almost no limits. Deploy and test any application, store data, and manage resources as you see fit. How exactly the infrastructure will function is up to you.
IaaS cons
IaaS doesn’t have many disadvantages:
- It’s a rather complex model. To use it, you need special knowledge and skills.
- The quality of your infrastructure depends on the reliability and conscientiousness of the provider: how they maintain the equipment and how often they update it. Choose a cloud provider very carefully.
What tasks is IaaS suitable for?
IaaS is an alternative to buying your own hardware. Therefore, this model is suitable for any type of business.
When is IaaS the perfect solution?
- Big surges in demand at certain times. The cloud saves you the trouble of buying additional hardware that will be idle most of the time. You’ll be able to increase the consumption of virtual resources during peak loads and use less power the rest of the time, allowing you to save on costs.
- The development and testing of applications. In a cloud infrastructure, you can instantly deploy separate environments to test software performance. This way, testing won’t affect the functioning of your main resources in any way. And after the tests are complete, you can minimize unnecessary environments.
IaaS with Gcore Cloud
Our cloud offers a variety of IaaS solutions to help you grow your business faster and cheaper:
- Rent virtual machines and bare metal servers.
- Distribute the load among resources using a user-friendly load balancer.
- Take snapshots for disaster recovery.
- Set up private clusters in cloud networks for secure computing or isolating applications.
- Store any data on our servers in Europe, Asia, and the USA.
- Accelerate the loading of web applications, online services, and media with the integrated CDN.

Learn more about cloud services
PaaS
PaaS stands for Platform as a Service.
It’s a pre-configured tool set that a provider provides to customers to build their applications.
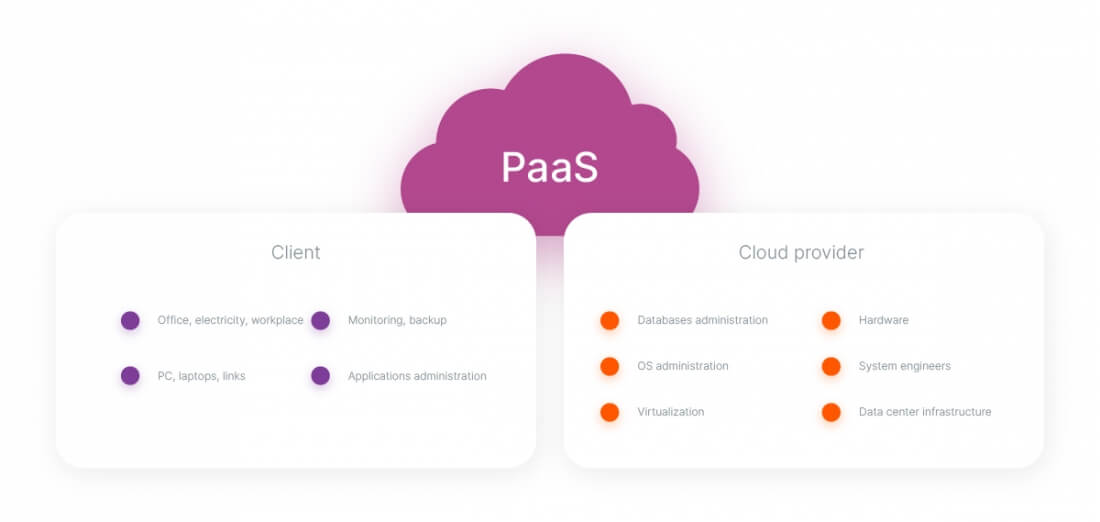
You also rent computing power. But if, in the case of IaaS, you only have virtual machines or bare-metal servers, and you install and configure the working tools yourself, then PaaS already offers everything you need for development.
Unlike IaaS, you don’t have access to the operating system of the servers, so you can’t set their configuration and balance the load. The provider takes care of all that. And you, in turn, can use the platform tools, upload your data, and install application software.
Examples of PaaS include database processing systems, AI platforms, and Kubernetes containers. Basically, PaaS refers to any platform that can be used as a basis for developing applications.
What tasks is PaaS suitable for?
PaaS provides developers with a framework for building and testing software. How exactly the platform works depends on the purpose for which it’s intended and on what tools it contains.
For example, if it’s an AI platform, you can leverage the power of artificial intelligence in your applications.
Let’s say you want to create a model that can diagnose patients based on their CT scans. The platform already has ready-made tools for the loading and processing data, and support for full-cycle machine learning. You don’t need to teach the model to analyze snapshots from scratch. Instead, you use ready-made platform tools. The development process in this case is several times faster.
In addition, PaaS can be used for various other tasks depending on what features the platform offers. For example, you can manage and analyze databases.

PaaS pros
- The simplification, acceleration, and consequently, cost reduction of developing programs and applications.
- It’s easier to use than IaaS. The provider takes over the management of services, configuration, and load balancing.
- Development tools are ready to use, there’s no need to install or configure anything.
- You can share the project with multiple users, for example, your team members or contractors. Everyone will have their own access level and privileges.
PaaS cons
- Like IaaS, PaaS requires specialized knowledge to use.
- Less control over the computing infrastructure compared to IaaS.
- Development capabilities are limited by the features offered by the provider.
- As with IaaS, you need to be very careful when choosing your provider. Contact companies with reliable data centers. Be sure to find out if the provider can guarantee the security of your data.
PaaS with Gcore Cloud
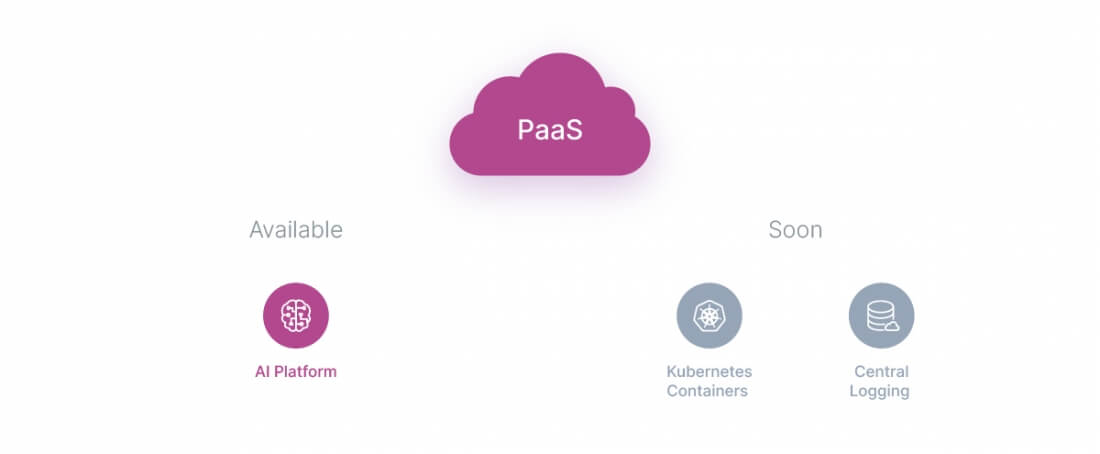
We offer a user-friendly AI Platform to help accelerate the machine learning process of your software.
A catalog of ready-made templates and models is built into the platform, and tools for development and working with data are integrated.
We also plan to launch support for Kubernetes containers and database management in the near future.
SaaS
SaaS stands for Software as a Service.
These are completely ready-to-use applications configured to solve your problems.
Any application that you access over the internet is SaaS: email services, website builders, CRM systems, video call services, and so on.
You also don’t need to develop anything yourself. You take a ready-made solution and start using it.

What tasks is SaaS suitable for?
The company’s own applications are usually developed for end users. To solve internal problems, the development of new software is sometimes also required. But in most cases, there’s no need to reinvent the wheel.
For example, you need an email service. Why develop your own email client when you can use a ready-made solution? Or maybe you need a CRM system. There’s e a huge number of offers on the market. Surely at least one of them will fully suit your tasks.
SaaS is also used for short-term projects when you need the fastest and simplest solution and there’s no time to develop something on your own.

SaaS pros
- It’s a ready-made solution without the need to waste time on development or hire staff.
- You can focus more on reaching your business goals.
- To access a SaaS, you usually only need a browser and an internet connection.
SaaS cons
- Your capabilities are limited by the software features.
- The SaaS is controlled by the provider.
- Limited opportunities for integration with other applications and services.
SaaS with Gcore Cloud
Choose a ready-made SaaS solution from our Marketplace.
Applications we already have:
- A video call service for browsers
- Repository management systems
- Popular game servers
- An alert management system
The list is constantly growing.
Gcore Cloud is powerful and reliable. It will help your projects grow faster at a lower cost around the world.
We guarantee:
- Tier IV data centers
- 99.95% SLA with financial guarantees
- Protection against DDoS attacks
- Compliance with security standards (GDPR, PCI DSS)
Move to our cloud quickly and safely.
Or request a free consultation to get started. We’ll help you find the best solution for your project!
Related articles





Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial

Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.