
In this guide, we will use Ansible as a Deployment tool in a Continuous Integration/Continuous Deployment process using Jenkins Job.
In the world of CI/CD process, Jenkins is a popular tool for provisioning development/production environments as well as application deployment through pipeline flow. Still, sometimes, it gets overwhelming to maintain the application’s status, and script reusability becomes harder as the project grows.
To overcome this limitation, Ansible plays an integral part as a shell script executor, which enables Jenkins to execute the workflow of a process.
Let us begin the guide by installing Ansible on our Control node.
Install and Configure Ansible
Installing Ansible:
Here we are using CentOS 8 as our Ansible Control Node. To install Ansible, we are going to use python2-pip, and to do so, first, we have to install python2. Use the below-mentioned command to do so:
# sudo yum update# sudo yum install python2After Python is installed on the system, use pip2 command to install Ansible on the Control Node:
# sudo pip2 install ansible# sudo pip2 install dockerIt might take a minute or two to complete the installation, so sit tight. Once the installation is complete, verify:
# ansible --version ansible 2.9.4 config file = None configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules'] ansible python module location = /usr/lib/python2.7/site-packages/ansible executable location = /usr/bin/ansible python version = 2.7.16 (default, Nov 17 2019, 00:07:27) [GCC 8.3.1 20190507 (Red Hat 8.3.1-4)]Through the above command, we notice that the config file path is missing, which we will create and configure later. For now, let’s move to the next section.
Configuring Ansible Control Node User:
The first thing we are going to do is create a user named ansadmin, as it is considered the best practice. So let’s create a user, by using the command adduser, which will create a new user to our system:
# useradd ansadminNow, use the passwd command to update the ansadmin user’s password. Make sure that you use a strong password.
# passwd ansadminChanging password for user ansadmin.New password: Retype new password: passwd: all authentication tokens updated successfully.Copy the password for user ansadmin and save it somewhere safe.
Once we have created the user, it’s time to grant sudo access to it, so it doesn’t ask for a password when we log in as root. To do so, follow the below-mentioned steps:
# nano /etc/sudoersGo to the end of the file and paste the below-mentioned line as it is:
...ansadmin ALL=(ALL) NOPASSWD: ALL...Before moving forward, we have one last thing to do. By default, SSH password authentication is disabled in our instance. To enable it, follow the below-mentioned steps:
# nano /etc/ssh/sshd_configFind PasswordAuthentication, uncomment it and replace no with yes, as shown below:
...PasswordAuthentication yes...You will see why we are doing this in the next few steps. To reflect changes, reload the ssh service:
# service sshd reloadNow, log in as an ansadmin user on your Control Node and generate ssh key, which we will use to connect with our remote or managed host. To generate the private and public key, follow the below-mentioned commands:
# su - ansadminUse ssh-keygen command to generate key:
# ssh-keygenEnter file in which to save the key (/home/ansadmin/.ssh/id_rsa): ansible-CN Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in ansible-CN.Your public key has been saved in ansible-CN.pub.The key fingerprint is:SHA256:6G0xzIrIsmsBwCakACI8CVr8AOuRR8v5F1p2+CsB6EY ansadmin@ansible-hostThe key's randomart image is:+---[RSA 3072]----+|&+o. ||OO* + . ||Bo.E . = . ||o = o =++ ||.. o o.oS. || o.. o.o.o. ||. + . o.o. || + .. ||+. |+----[SHA256]-----+Usually, keys are generated in the .ssh/ directory. In our case, you can find keys at /home/ansadmin/.ssh/. Now let us configure our Managed Host for Ansible.
Configuring Ansible Managed Host User:
First, we will create a user on our managed host, so log in to your host and create a user with the same name and password.
As our managed host is an Ubuntu machine, therefore here we have to use the adduser command. Please make sure that the password for the username ansadmin is the same for Control and Managed Host.
# adduser ansadmin# su - ansadminOther than this, it is also an excellent thing to cross-check if password authentication is enabled on the Managed Host as we need to copy the ssh public key from the control node to the Managed Host.
Switch to Control Node machine; to copy the public key to our Managed Host machine, we will use the command ssh-copy-id:
$ su - ansadmin$ ssh-copy-id -i .ssh/ansible-CN.pub ansadmin@managed-host-ip-hereFor the first time, it will ask for the password. Enter the password for ansadmin, and you are done. Now, if you wish, you can disable Password Authentication on both machines.
Setting Ansible Inventory:
Ansible allows us to manage multiple nodes or hosts at the same time. The default location for the inventory resides in /etc/ansible/hosts. In this file, we can define groups and sub-groups.
If you remember, earlier, the hosts’ file was not created automatically for our Ansible. So let’s create one:
# cd /etc/ansible# touch hosts && nano hostsAdd the following lines in your hosts’ file and save it:
[docker_group]docker_host ansible_host=your-managed-host-ip ansible_user=ansadmin ansible_ssh_private_key_file=/home/ansadmin/.ssh/ansible-CN ansible_python_interpreter=/usr/bin/python3ansible_CN ansible_connection=localMake sure that you replace your-managed-host-ip with your host IP address.
Let’s break down the basic INI format:
docker_group– Heading in brackets is your designated group name.docker_host&ansible_CN– The first hostname isdocker_host, which points to our Managed Host. While the second hostname isansible_CN, which is pointing towards our localhost, to be used in Ad-Hoc commands and Playbooks.ansible_host– Here, you need to specify the IP address of our Managed Host.ansible_user– We mentioned our Ansible user here.ansible_ssh_private_key_file– Add the location of your private key.ansible_python_interpreter– You can specify which Python version you want to use; by default, it will be Python2.ansible_connection– This variable helps Ansible to understand that we are connecting the local machine. It also helps to avoid the SSH error.
It is time to test our Ansible Inventory, which can be done through the following command. Here we are going to use a simple Ansible module PING:
# ansible all -m pingansible_CN | SUCCESS => { "ansible_facts": { "discovered_interpreter_python": "/usr/libexec/platform-python" }, "changed": false, "ping": "pong"}docker_host | SUCCESS => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python3" }, "changed": false, "ping": "pong"}It looks like the Ansible system can now communicate with our Managed Host as well as with the localhost.
Install Docker:
We need a Docker ready system to manage our process; for this, we have to install Docker on both systems. So follow the below-mentioned steps:
For CentOS (Control Node):
Run the following command on your Control Node:
# sudo yum install -y yum-utils device-mapper-persistent-data lvm2 # sudo yum-config-manager --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo # sudo yum install docker-ce docker-ce-cli containerd.ioIn case you encounter the below-mentioned error during installation:
Error: Problem: package docker-ce-3:19.03.5-3.el7.x86_64 requires containerd.io >= 1.2.2-3, but none of the providers can be installedNext, run the following command:
# sudo yum install docker-ce docker-ce-cli containerd.io --nobestFor Ubuntu OS (Managed Host):
Run the following command on your Managed Host, which is a Ubuntu-based machine:
$ sudo apt-get remove docker docker-engine docker.io containerd runc $ sudo apt-get update && sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -$ sudo apt-get update && sudo apt-get install docker-ce docker-ce-cli containerd.ioThat’s it for this section. Next, we are going to cover how to integrate Ansible with Jenkins.
Integrating Ansible with Jenkins:
In this section, we will integrate Ansible with Jenkins. Fire up your Jenkins, go to Dashboard > Manage Jenkins > Manage Plugins > Available and then search for Publish Over SSH as shown in the image below:

Now, go to Configure System and find Publish over SSH; under this section, go to SSH Servers and click on the Add button. Here we are going to add our Docker Server as well as Ansible Server, as shown in the image:
SSH server setting for Docker:

SSH server setting for Ansible:
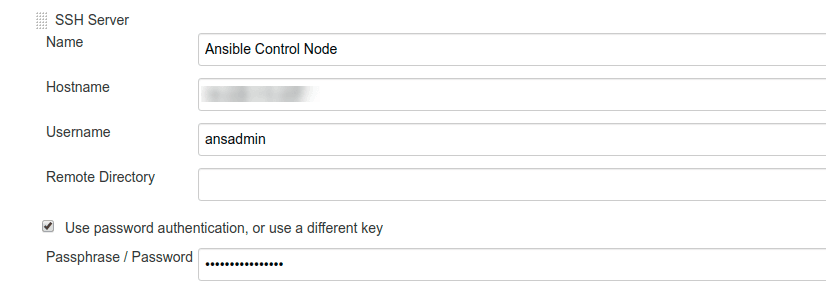
In the Hostname field, add your IP address or domain name of Docker and Ansible server. Before saving the setting, make sure that you test the connection before saving the configuration, by clicking on the Test Configuration button as shown in the image below:

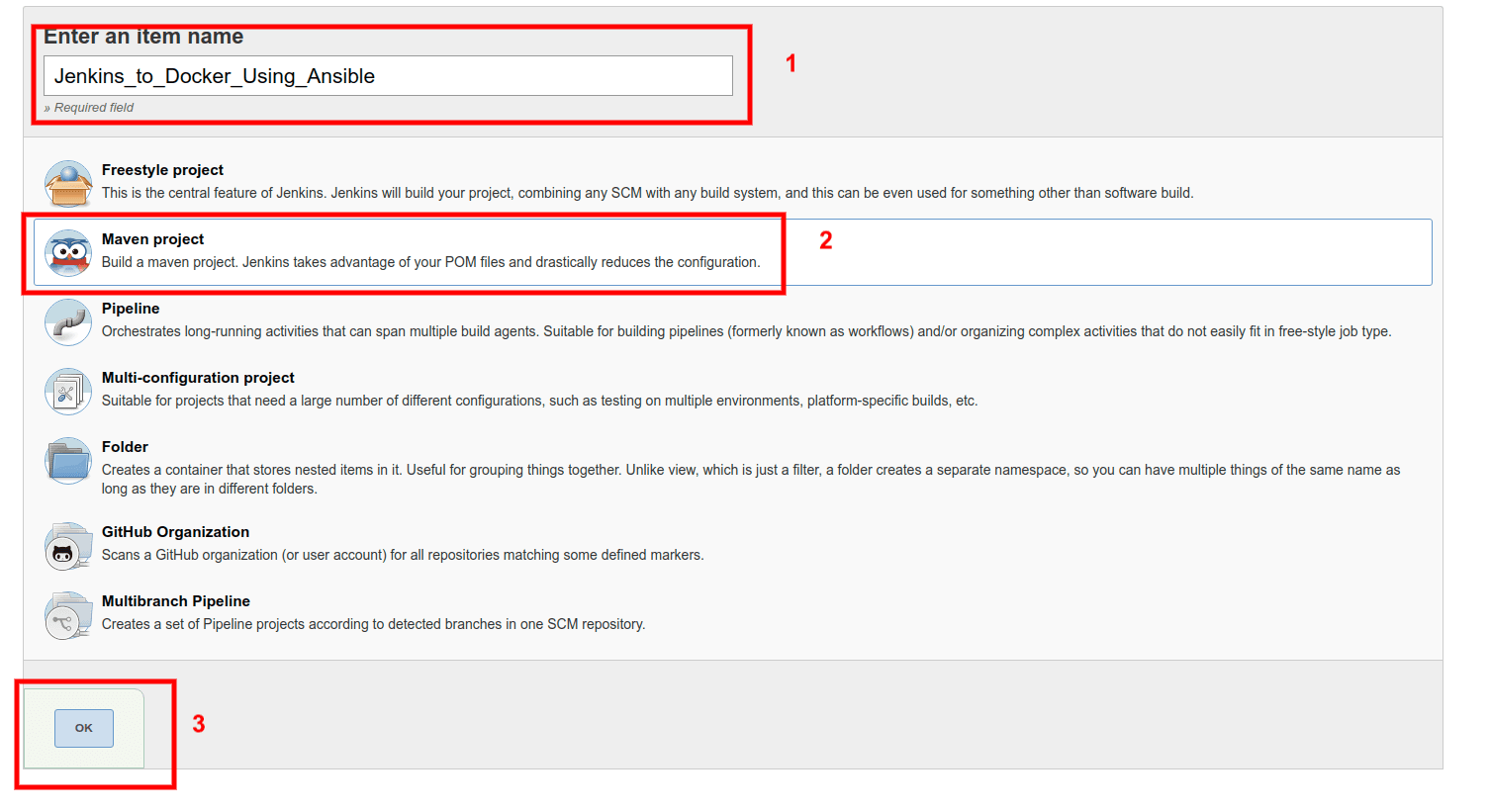
Create Jenkins Job
The next step is to create Jenkins jobs. The sole propose of this Job is to build, test, and upload the artifact to our Ansible Server. Here we are going to create Job as a Maven Project, as shown in the image below:
Next in Job setting page, go to the Source Code Management section and add your Maven project repo URL, as shown in the image below:

Find the Build section, and in Root POM field enter your pom.xml file name. Additionally in the Goals and options field enter clean install package:
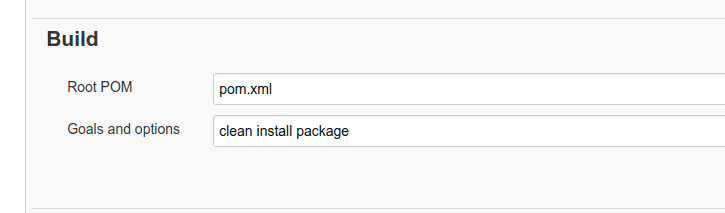
After successful build completion, your goal is to send the war file to the specified directory to your Ansible server with the right permissions so that it doesn’t give us the writing permission by assigning ansadmin to the directory.
Right now, we don’t have such a directory, so let us create one. Follow the below-mentioned steps:
# sudo su# mkdir /opt/docker# chown ansadmin:ansadmin /opt/docker -R# ls -al /opt/docker/total 0drwxr-xr-x. 2 ansadmin ansadmin 6 Jan 31 16:57 .drwxr-xr-x. 4 root root 38 Jan 31 17:10 ..Directory /opt/docker will be used as our workspace, where Jenkins will upload the artifacts to Ansible Server.
Now, go to the Post-build Actions section and from the drop-down menu, select Send build artifacts over SSH, as shown in the image below:
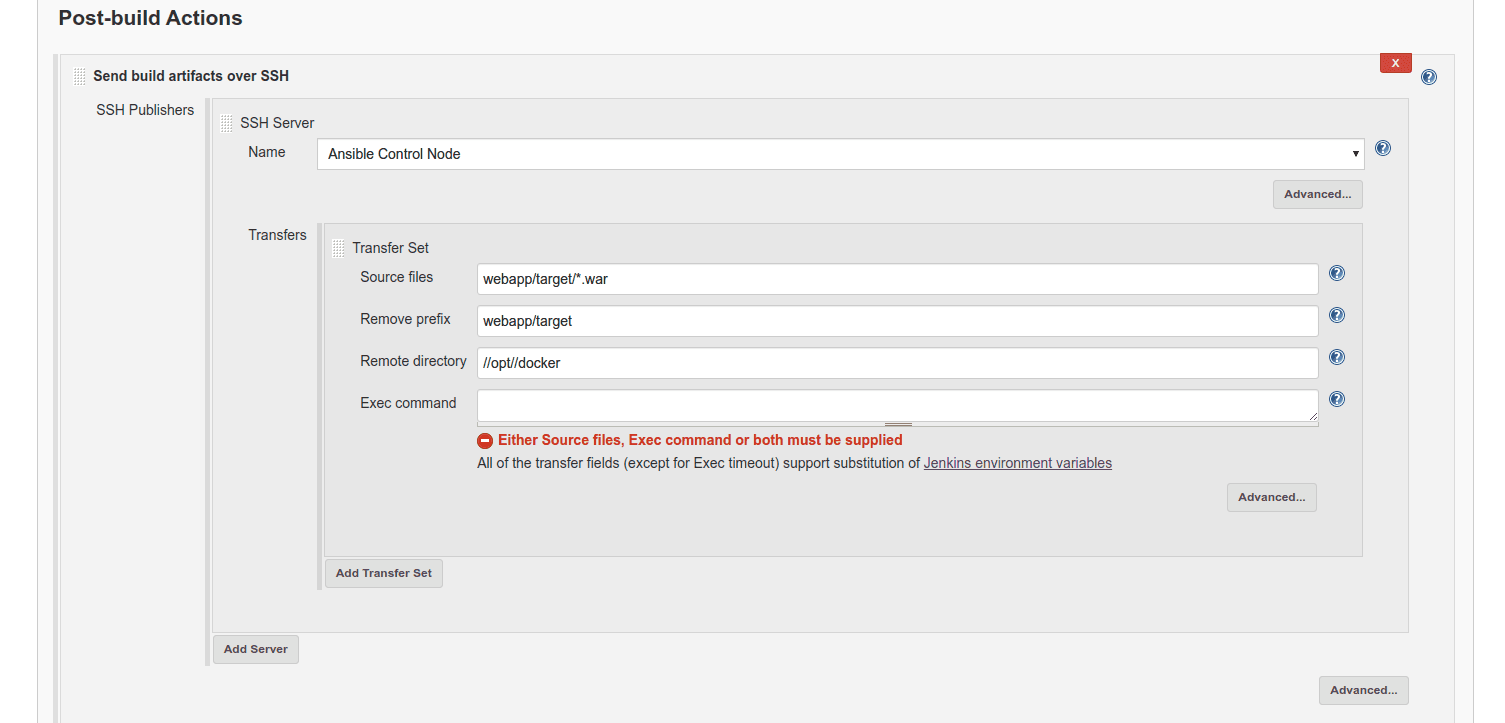
Make sure that in the Remote Directory field, you enter the pattern //opt//docker as it doesn’t support special characters. Apart from this, for now, we are going to leave the Exec Command field empty so that we can test whether our existing configuration works or not.
Now Build the project, and you will see the following output in your Jenkins’s console output:

Go to your Ansible Server terminal and see if the artifact was sent with right user privileges:
# ls -al /opt/docker/total 4drwxr-xr-x. 2 ansadmin ansadmin 24 Feb 3 10:54 .drwxr-xr-x. 4 root root 38 Jan 31 17:10 ..-rw-rw-r--. 1 ansadmin ansadmin 2531 Feb 3 10:54 webapp.warIt looks like our webapp.war file was transferred successfully. In the following step, we will create an Ansible Playbook and Dockerfile.
Creating Dockerfile and Ansible Playbook:
To create a Docker Image with the webapp.war file, first, we will create a DockerFile. Follow the below-mentioned steps:
First, log in to your Ansible Server and go to directory /opt/docker and create a file named as Dockerfile:
# cd /opt/docker/# touch DockerfileNow open the Dockerfile in your preferred editor, and copy the below-mentioned lines and save it:
FROM tomcat:8.5.50-jdk8-openjdkMAINTAINER Your-Name-HereCOPY ./webapp.war /usr/local/tomcat/webappsHere instructions are to pull a Tomcat image with tag 8.5.50-jdk8-openjdk and copying the webapp.war file to Tomcat default webapp directory., which is /usr/local/tomcat/webapps
With the help of this Dockerfile, we will create a Docker container. So let us create the Ansible Playbook, which will enable us to automate the Docker image build process and later run the Docker container out of it.
We are creating a Ansible Playbook, which does two tasks for us:
- Pull Tomcat’s latest version and build an image using
webapp.warfile. - Run the built image on the desired host.
For this, we are going to create a new YAML format file for your Ansible Playbook:
# nano simple-ansible.yamlNow copy the below-mentioned line into your simple-ansible.yaml file:
---#Simple Ansible Playbook to build and run a Docker containers - name: Playbook to build and run Docker hosts: all become: true gather_facts: false tasks: - name: Build a Docker image using webapp.war file docker_image: name: simple-docker-image build: path: /opt/docker pull: false source: build - name: Run Docker container using simple-docker-image docker_container: name: simple-docker-container image: simple-docker-image:latest state: started recreate: yes detach: true ports: - "8888:8080"You can get more help here: docker_image and docker_container. Now, as our Playbook is created, we can run a test to see if it works as planned:
# cd /opt/docker# ansible-playbook simple-ansible-playbook.yaml --limit ansible_CNHere we have used the --limit flag, which means it will only run on our Ansible Server (Control Node). You might see the following output, in your terminal window:
PLAY [Playbook to build and run Docker] *************************************************************************** TASK [Build Docker image using webapp.war file] ***************************************************************************changed: [ansible_CN] TASK [Run Docker image using simple-docker-image]***************************************************************************changed: [ansible_CN] PLAY RECAP ***************************************************************************ansible_CN : ok=2 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0Look’s like Playbook ran sccessfully and no error was detected during the Ansible Playbook check, so now we can move to Jenkins to complete our CI/CD process using Ansible.
Run Ansible Playbook using Jenkins
In this step, we would execute our Ansible Playbook (i.e., simple-ansible-playbook.yaml) file, and to do so let us go back to the Project Configuration page in Jenkins and find Post-build Actions there.
In this section, copy the below-mentioned command in the Exec command field:
sudo ansible-playbook --limit ansible_CN /opt/docker/simple-ansible-playbook.yaml;
Now, let us try to build the project and see the Jenkins Job’s console output:
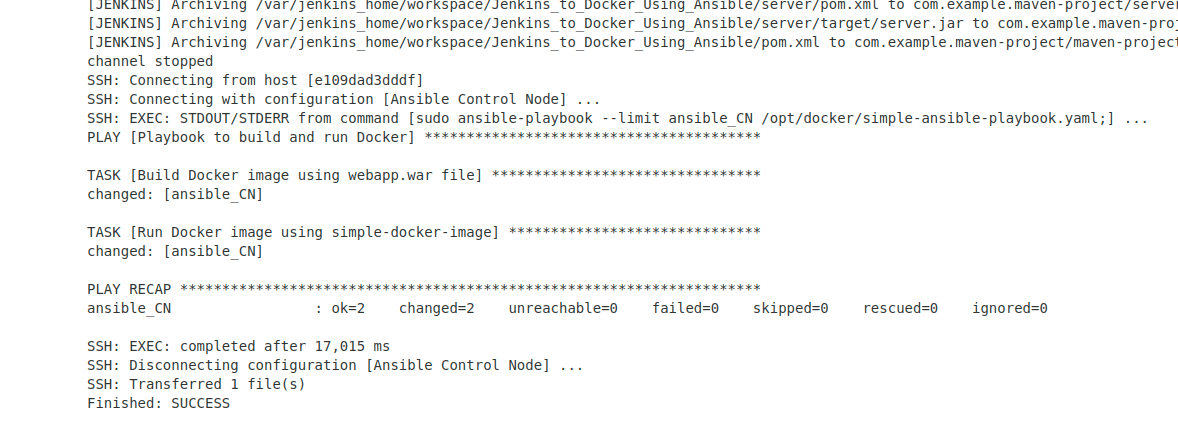
In the output, you can see that our Ansible playbook ran successfully. Let us verify if at Ansible Server the image is created and the container is running:
For Docker Image list:
# docker images REPOSITORY TAG IMAGE ID CREATED SIZEsimple-docker-image latest d47875d99095 32 seconds ago 507MBtomcat latest 5692d26ea179 15 hours ago 507MBFor Docker Container list:
# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES5a824d0a43d5 simple-docker-image:latest "catalina.sh run" 15 seconds ago Up 14 seconds 0.0.0.0:8888->8080/tcp simple-docker-containerIt looks like Jenkins was able to run the Ansible Playbook successfully. Next, we are going to push Docker Image to Docker Hub.
Pushing Docker Image to Docker Hub Using Ansible
We are going to use Docker Hub public repository for this guide; in case you want to work on a live project, then you should consider using the Docker Hub private registry.
For this step, you have to create a Docker Hub account if you haven’t had one yet.
Our end goal for this step is to publish the Docker Image to Docker Hub using Ansible Playbook. So go to your Ansible Control Node and follow the below-mentioned steps:
# docker login Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.Username: your-docker-hub-userPassword: WARNING! Your password will be stored unencrypted in /root/.docker/config.json.Configure a credential helper to remove this warning. Seehttps://docs.docker.com/engine/reference/commandline/login/#credentials-store Login SucceededMake sure that you enter the right username and password.
Now it’s time to create a new Ansible Playbook which will build and push the Docker image to your Docker Hub account. Note that this image will be publicly available, so be cautious.
# nano build-push.yamlCreate a new Ansible Playbook, which will build a Docker image and push it to our Docker Hub account:
---#Simple Ansible Playbook to build and push Docker image to Registry - name: Playbook to build and run Docker hosts: ansible_CN become: true gather_facts: false tasks: - name: Delete existing Docker images from the Control Node shell: docker rmi $(docker images -q) -f ignore_errors: yes - name: Push Docker image to Registry docker_image: name: simple-docker-image build: path: /opt/docker pull: true state: present tag: "latest" force_tag: yes repository: gauravsadawarte/simple-docker-image:latest push: yes source: buildLet us run the playbook now and see what we get:
# ansible-playbook --limit ansible_CN build-push.yaml PLAY [Playbook to build and run Docker] ***************************************************************************************** TASK [Push Docker image to Registry] *****************************************************************************************changed: [ansible_CN] PLAY RECAP *****************************************************************************************ansible_CN : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0Go to your Docker Hub account and see if the image was pushed successfully, as shown in the image below:
Next, let us modify our simple-ansible-playbook.yaml playbook, which we created earlier, as from here on, we are going to pull the Docker image from Docker Hub Account and create a container out of it.
---#Simple Ansible Playbook to pull Docker Image from the registry and run a Docker containers - import_playbook: build-push.yaml - name: Playbook to build and run Docker hosts: docker_host gather_facts: false tasks: - name: Run Docker container using simple-docker-image docker_container: name: simple-docker-container image: gauravsadawarte/simple-docker-image:latest state: started recreate: yes detach: true pull: yes ports: - "8888:8080"Note that we have used the import_playbook statement at the top of the existing playbook, which means that we want to run the build-push.yaml playbook first along with our main playbook, and this way, we don’t have to run multiple playbooks manually.
Let us break the whole process into steps:
- With the help of
build-push.yamlplaybook, we are asking Ansible to build an image with the artifacts sent by Jenkins to our Control Node, and later push the built image (i.e.,simple-docker-image) to our Docker Hub’s account or any other private registry like AWS ECR or Google’s Container Registry. - In the
simple-ansible-playbook.yamlfile, we have imported thebuild-push.yamlfile, which is going to run prior to any statement present within thesimple-ansible-playbook.yamlfile. - Once
build-push.yamlplaybook is executed, Ansible will launch a container into our Managed Docker Host by pulling our image from our defined registry.
Now, it’s time to build our job. So in the next step, we will deploy the artifact to our Control Node, where Ansible Playbook will build an image, push to Docker Hub and run the container in Managed Host. Let us get started!
Jenkins Jobs to Deploy Docker Container Using Ansible
To begin, go to JenkinstoDockerUsingAnsible configure page and change the Exec command in the Post-build Actions section.
Copy the below-mentioned command and add it as shown in the image below:
sudo ansible-playbook /opt/docker/simple-ansible-playbook.yaml;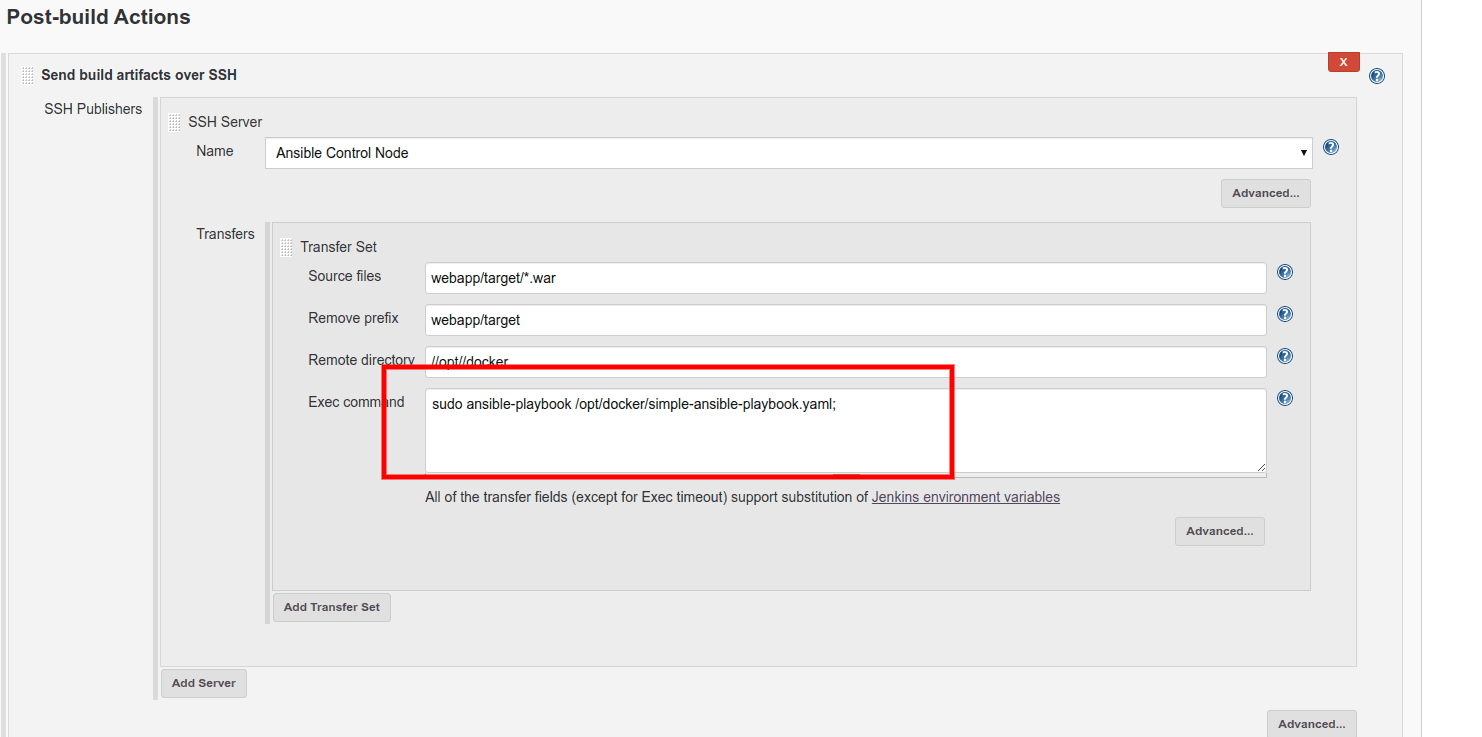
Save the configuration and start the build; you will see the following output:

Now go to your Control Node and verify if our images were built:
# docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEgauravsadawarte/simple-docker-image latest 9ccd91b55796 2 minutes ago 529MBsimple-docker-image latest 9ccd91b55796 2 minutes ago 529MBtomcat 8.5.50-jdk8-openjdk b56d8850aed5 5 days ago 529MBIt looks like Ansible Playbook was successfully executed on our Control Node. It’s time to verify if Ansible was able to launch containers on our Managed Host or not.
Go to your Managed Host and enter the following command:
# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES6f5e18c20a68 gauravsadawarte/simple-docker-image:latest "catalina.sh run" 4 minutes ago Up 4 minutes 0.0.0.0:8888->8080/tcp simple-docker-containerNow visit the following URL http://your-ip-addr:8888/webapp/ in your browser. Note that, Tomcat Server may take some time before you can see the output showing your project is successfully setup.
And you are done!
You successfully managed to deploy your application using Jenkins, Ansible, and Docker. Now, whenever someone from your team pushes code to the repository, Jenkins will build the artifact and send it to Ansible, from there Ansible will be responsible for publishing the application to the desired machine.
Related articles

Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial
Multi-cloud and hybrid cloud represent two distinct approaches to distributed computing architecture that build upon the foundation of cloud computing to help organizations improve their IT infrastructure.Multi-cloud environments involve us
Multi-cloud is a cloud usage model where an organization utilizes public cloud services from two or more cloud service providers, often combining public, private, and hybrid clouds, as well as different service models, such as Infrastructur
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.