
HTTP (HyperText Transfer Protocol) is an application-level network protocol that determines how content is transferred over the network. HTTP/2 is its latest version as of the moment of this publication.
How HTTP/2 was created
The specification of the first protocol version, HTTP/0.9, was published back in 1991. In 1996, HTTP/1.0 appeared, and HTTP/2’s predecessor, HTTP/1.1, was released in 1999. Then followed a long period without any updates.
An alternative to HTTP/1.1, the SPDY protocol, was developed in 2009. At that time, the developers already realized that the existing version was not providing for enough data transfer speed. The engineers strived to modify how the queries were sent and received, thus speeding up the work of the Internet. It was this protocol that HTTP/2 was based on.
SPDY really did speed up web apps. It was gaining popularity and provided serious competition to HTTP. Eventually the developers decided that there should not be two competitive protocols and ended up unifying the two standards. The HyperText Transfer Protocol work group from the Internet Engineering Task Force took up the new protocol creation, and in 2015, HTTP/2 was revealed.
The main goal of the new version was speeding up data transfer. At the same time, the developers wanted to eliminate the “bottlenecks” of HTTP/1.1, making it safer and more efficient.
HTTP/1.1 problems and limitations
As we already said, this protocol version was released in 1999, and HTTP/2 wasn’t created until 16 years later. A lot has changed on the Internet since. Many new website elements appeared: jаvascript, animations, CSS styles, and so on.
To make sure web resources loaded fast enough, queries for different elements had to be processed simultaneously. The protocol had to establish several TCP connections at once to transfer different kinds of data.

TCP connection for data transfer over HTTP/1.1
That created a colossal load on the network.
At the same time, the number of established connections was limited—and often not high enough. To bypass the limitations, web developers had to use a multitude of tricks, such as domain sharding (using subdomains to load resources), combining the pictures into a single file, and so on, which created further issues.
Besides, as HTTP/1.1 had existed for many years, at some point is stopped being safe. Intruders found loopholes in it, which allowed them to steal users’ data.
HTTP/2 solved all these problems and helped significantly speed up data transfer on the web.
HTTP/2 capabilities. How it speeds up websites and improves data transfer
To eliminate all the problems of HTTP/1.1, the developers introduced a number of important changes to the new version. We won’t examine each difference: let’s only talk about those that have a direct effect on the speed.
Binary protocol
The previous versions of HTTP transferred data as text. It was convenient for the users, but from the technical point of view, text messages take longer to process than binary ones.

HTTP/1.1 and HTTP/2 data transfer comparison
In HTTP/2, messages consist of frames, or binary data parts. Their sum total is called a stream. Every frame contains a unique stream ID: the information about what stream it is a part of.

Frames and streams in HTTP/2
There are several kinds of frames. For example, for the transfer of metadata (message size, data type, sender/receiver address, etc.), the HEADERS frame is used, while for the main message, it is the DATA frame.
Then there’s the RST_STREAM frame, which is used to terminate a stream: the client sends it to the server to announce that the stream is not needed anymore. It stops data transfer while keeping the connection open. To put that into context, in HTTP/1.1, the only way to stop data transfer was to terminate the connection, which then had to be reestablished.
These principles of binary protocol operation improve the connection quality:
- The likelihood of errors goes down.
- Overhead costs of data parsing go down.
- The network load goes down, resources are used more efficiently.
- Binary commands are more compact than text commands, which lowers the time it takes to process and execute them.
- Therefore, there’s also less data transfer delays.
- Simpler processing of messages means higher fault tolerance.
- The risk of hacker attacks goes down, especially of ones like HTTP Response Splitting. In the previous versions, text data in the headers provided an opening for these attacks.
Besides, the binary nature of HTTP/2 opened a whole range of possibilities to speed up data transfer, which we’ll discuss below.
Multiplexing
This is one of the main differentiators of HTTP/2 from the previous versions, and the main feature that allowed the developers to speed up data transfer.
In HTTP/1.1, several parallel TCP connections were created for a quick transfer of different types of data. In the new version, all data can be transferred with a single connection.

TCP connection for data transfer over HTTP/2
The binary nature of the protocol makes it possible to load different kinds of information in parallel, without delays and without blocking any of the replies or queries.
Connection only has to be established once, and that really reduces the content delivery time. The reason is, a “three-way handshake” is required to establish each TCP connection:
- The sender sends a request to establish the connection: a SYN message with the index number of the byte sent.
- In response, the sender sends a SYN message, acknowledges the acceptance of the data with an ACK message, and sends the number of the byte which is to be received next.
- The sender also confirms the data acquisition and sends the number of the next expected byte.
Only after these three steps have been carried out, the connection is considered to have been established.

TCP connection establishment
All of these steps take time. When the connection only needs to be established once, the computers do not waste time on extra “handshakes,” which increases the speed accordingly.
Besides, in HTTP/2, there is no need for domain sharding.
To avoid the limitation on the number of TCP connections in HTTP/1.1, developers posted some of the content onto the subdomains. The data from the subdomains was loaded in parallel, which helped increase the speed.
There’s no need to do that anymore: different data can be transmitted within a single connection, and there is no limitation.
Header compression
To make sure the server completes the request as precisely as possible, its header should contain a lot of specifying metadata—and HTTP is a stateless protocol. That means the server cannot store the information from the previous requests, and the client ends up having to send a lot of identical data in headers.
These headers contain about 500 to 800 bytes of ancillary data—and if cookie files are used, it can be 1 KB+.
That makes the messages larger in general. And the larger the size of a message, the longer it is transferred, and the higher the delay will be.
In HTTP/2, the issue was fixed by header compression under the HPACK format. It encodes and compresses the headers using the Huffman algorithm. At the same time, the client and the server keep up a shared and constantly updated table of headers, which makes it possible to restore repeated headers from the table instead of sending them over and over.

HPACK header compression
Less data is being transferred, which means queries and replies are sent faster.
Server Push feature
This feature allows the server to transfer data even before the client’s request. For example, the browser downloads a page and sends an HTML request. But to render the page, CSS data will be needed besides the HTML data. So, the server doesn’t wait for a second request for CSS and sends the CSS data immediately along with the requested data.
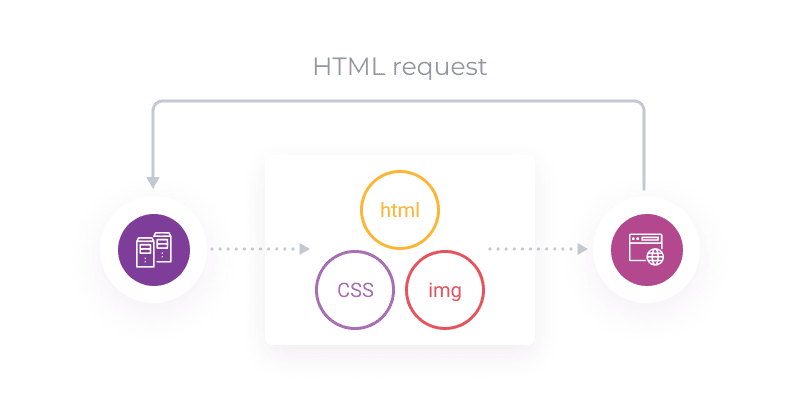
How the Server Push works
The data that the server “guessed” is sent within the PUSH_PROMISE frame: it allows the client to understand they didn’t request this information, and to determine whether they need it. If the information proves unnecessary (for example, because it is already cached), the browser can send as a response the RST_STREAM frame (we discussed it above) and stop the redundant data transfer.
This helps avoid data duplication.
Therefore, the feature lowers the number of requests to the server, lowers the load on it, and speeds up the operation of web apps.
Prioritizing content delivery
By default, HTTP/2 data are sent asynchronously and in an arbitrary sequence. However, the sequence can be tuned. You can define what data the server should return first and what can be sent later.
The protocol makes it possible to determine the weight of each stream: its importance in the transfer priority plan. HTTP/2 also allows one to set up the interdependence of streams on one another.
The weight is determined as an integer from 1 to 256: the larger the number, the higher the priority of the stream.
The dependence of one stream on another is specified with a dedicated identifier, referring to another, “parent” stream.
For example, if stream X depends on stream Y, it means stream Y is the parent stream, and it must be fully processed first, before the processing of stream X begins.
If streams do not depend on one another but have different weights, different numbers of resources are allocated for each stream, proportional to their weight.
Suppose streams X and Y do not depend on one another, but the weight of X is 10, while the weight of Y is 15. Let’s calculate the share of resources to be allocated to each of them:
- X + Y = 10 + 15 = 25
- Resources allocated to X = 10 / 25 = 40%
- Resources allocated to Y = 15 / 25 = 60%
So, 40% of resources will be allocated for the processing of stream X, and 60%, for the processing of stream Y.
Let’s look at a more detailed example of how this works.

Content prioritization scheme in HTTP/2
What this flow chart means is:
- Stream D is to be priority-processed.
- Streams E and C are to be processed after D, 50% resources to be allocated for each of them.
- Streams A and B are to be processed after C, with A getting 75% of the resources, and B, 25%.
What opportunities prioritization provides:
- You’ll be able to define what content to load first.
- You can prioritize the website elements that are most important to the users.
- The users will get all the elements needed to interact with the website even before it loads completely.
- This will create the impression of a quicker load and improve the customer experience.
How HTTP/2 speeds websites up in practice
A lot of time has passed since the release of HTTP/2, and it has been tested and compared to HTTP/1 many times. Different tests provide different results, but most of them do confirm that the new version is more productive than the predecessor.
For example, the CSS-Tricks test showed that a website with HTTP/2 loaded almost twice as fast as a HTTP/1.1 resource.
To perform this test, the company modeled a real single-page website on WordPress. To measure the load speed, they used the GTMetrix instrument.
As a result, with use of HTTP/1.1, the website page loaded in 1.9 seconds.

While with HTTP/2, under the same conditions, the load time was 1 second.

At the same time, we can see the number of queries under HTTP/2 was lower.
The results of a test performed by SolarWinds were not as impressive. It showed that HTTP/2 was only 13% more efficient than the predecessor.
Like in the previous test, the company measured the speed of a WordPress website with Pingdom. The speed was tested 4 times with 30-minute intervals. After averaging the results, here’s what they ended up with:
The HTTP/1.1 website loaded in 534 ms.
While with HTTP/2, the same website loaded in 464 ms.

In any case, HTTP/2 is currently the fastest and most optimized version of the Internet’s main data transfer protocol.
Let’s sum it up
- HTTP/2 is the second large build of HTTP, the application-level network protocol that determines how content is transferred over the internet.
- HTTP/2 was launched in 2015, as a substitute for HTTP/1.1. The main goal of the new version was speeding up content delivery.
- The main feature of HTTP/2 that helped it speed up the delivery was stream multiplexing: creating a single connection for all data types and transferring the data in parallel.
- Besides, HTTP/2 can transfer content even faster by compressing the headers, prioritizing the streams, and utilizing the Server Push feature. And unlike HTTP/1.1, it is a binary protocol, which also makes it more productive.
- The tests undertaken show that the use of HTTP/2 provides a significant benefit in website loading speed as compared to HTTP/1.1.
Gcore CDN supports the HTTP/2 protocol. And our network can transfer content over HTTP/2 even if your servers do not support it.
Gcore CDN specifics:
- Fast. Average global response time under 30 ms.
- Powerful. Overall network capacity over 75 Tbps.
- Global. 90+ points of presence across 5 continents.
- Competitive. Convenient plans and flat pricing worldwide, with a free plan for smaller projects.
Related articles


Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.