
Have you ever wondered how a web application can scale to serve millions of users worldwide? To serve a vast number of user requests, web applications must build their services to multiple instances. You might then wonder: How can an application evenly distribute the user requests so that all the user requests can be handled with peak efficiency? The short answer to that question is load balancing. The complete answer is…well, please reserve a few minutes to go through the article! You will learn all about load balancing: what a load balancer is, how it works, its benefits, methods of load balancing, and how to implement a load balancer for your use cases.
What Is a Load Balancer?
A load balancer is a hardware device or software application responsible for evenly distributing the requests across multiple application instances. (An “instance” is a single deployment of an application or service running on a server.) As a result, the application can cope with a high volume of requests efficiently.
If an additional app instance is introduced, the load balancer will redistribute the requests to include the new instance, thus reducing the workload on the existing instances. If an app instance goes down, all the requests to the problematic instance will be redistributed to other operational instances. As a result, the app is highly available and fault tolerant, offering users an uninterrupted service.
Load balancers can be categorized into different types based on how they manage and redistribute incoming requests. The two primary types are network load balancers, and application load balancers. Another mode of categorization is by physicality type, in which case we divide them into hardware and software load balancers. Let’s take a look at each of these in depth.
Network Load Balancers
Network load balancers forward the requests at the transport layer, layer 4 of the Open System Interconnection (OSI) model. The forwarding mechanism is based solely on network attributes, such as the IP addresses of the clients and the corresponding application instances.
Network balancers do not consider the contents of the requests when forwarding them to the app instances, which allows them to offer low latencies when redistributing the requests. Network load balancers would be a great fit for applications with extreme performance requirements, such as streaming or game applications.
Application Load Balancers
Application load balancers forward the requests at the application layer, also known as layer 7 of the OSI model. They examine the content of the requests, such as HTTP Headers, request paths, or request methods. This way, the application load balancer can flexibly distribute the requests to different app instances to match the business requirements.
Application load balancers are appropriate for e-commerce or social network applications that need support for custom HTTP responses and health checks for the app instances but do not require extremely low latencies.
Hardware Load Balancers
Network and application are categories of load balancers based on how they manage and redistribute incoming requests.
Hardware load balancers are purpose-built devices designed to redistribute the requests among app instances. They are often used in on-premise infrastructure alongside the company’s network systems and application servers. Hardware load balancers are a good choice for applications that want to store all data in self-managed servers or require special hardware customization when forwarding the requests to the target instances. They also offer enhanced security options.
Benefits of a Load Balancer
A load balancer can help with application performance in a number of ways, including scalability, cost reduction, availability, and request processing speed. Let’s take a closer look at each of these in turn.
Scalability
When more user requests are sent to the application server instances, the CPU utilization of the server instances is high.
An e-commerce application would benefit from the scalability the load balancers offer. Typically, the volume of user requests for e-commerce applications escalates far above normal levels during Black Friday sales.
High Availability
If one application instance goes down, the load balancer will forward the requests to other instances so the end user does not encounter any error or stoppage in service. The load balancer helps to ensure an application’s high availability by circumventing problematic instances.
How Load Balancing Works
To create a load balancing system that effectively forwards requests to the application instances, it’s first essential to understand how a load balancer works. Let’s review the inner workings of load balancing and explore some popular load balancing methods.
How Does a Load Balancer Work?
Different algorithms and combinations thereof are used by load balancers. The algorithm(s) depend on the complexity and features of the load balancer in question. A basic load balancer usually uses an algorithm called Round Robin to assign requests to the app instances. The Round Robin algorithm distributes the requests to the app instances one-by-one, resulting in an equal load distribution. No single app is overly taxed.
Let’s say you have three application instances. The first user request will be sent to instance number one. The second request will be sent to instance number two. The third request will be sent to instance number three. The fourth request will be sent to instance number four. Here, we have four instances available, so request number five will be sent to app instance one, and so on.
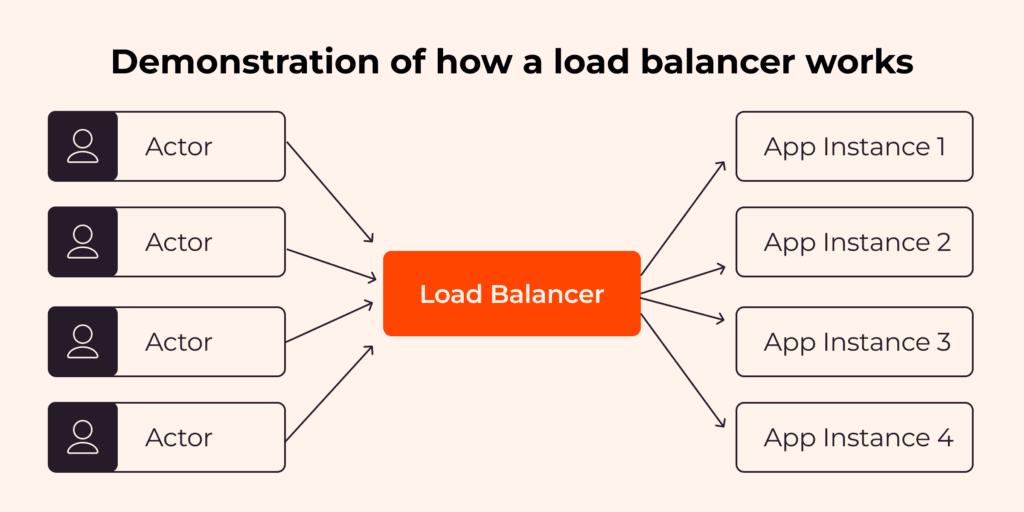
Instead of interacting directly with the application server, your application’s end users send requests to the load balancer.
What Are the Components of a Load Balancer?
A typical load balancer consists of four parts:
- Virtual IP: This is the unique digital address of the load balancer, allowing the client to send requests to the load balancer.
- Network protocols: Different types of load balancers support different network protocols. For example, a network load balancer supports TCP or UDP protocol, whereas an application load balancer supports HTTP and HTTPS protocols.
- Load balancing algorithms: Load balancers use different algorithms, such as Round Robin and IP Hash, to determine to which appropriate application instance they should forward the client’s request.
- Health monitoring: The load balancer routinely checks the health status of each app instance.
Load Balancing Methods
Besides the Round Robin algorithm already discussed, other load balancing methods and algorithms exist, including Weighted Round Robin and resourced-based methods. In general, the load-balancing methods can be divided into two categories: static load balancing and dynamic load balancing. Let’s take a closer look at each.
Static Load Balancing
With static load balancing, the load balancers forward the requests to the app instances without examining the current state of these app instances. This makes static load balancing easy to implement. The drawback of the static load balancing method is that it cannot adapt to the states of the app instances, which could be very different in runtime from what you anticipated, potentially affecting performance, and thus user experience. Some static load balancing methods are:
- Round Robin: The load balancer will forward the requests to the app instances cyclically, distributing requests evenly across the instances.
- Weighted Round Robin: Each app instance is assigned a weight, serving as an indicator of its processing capacity or priority. The load balancer forwards requests to the app instances according to the weighting. The higher the weighted number the app instance has, the more requests will be forwarded to that instance.
- IP hash: The load balancer generates a unique hash key based on both the client IP and the app instance IP. This method allows the client to interact with the same app instance repeatedly across multiple sessions. IP hash load balancing algorithm is suitable for applications that need persisted sessions between the client and the app instance because they ensure a continuous, seamless experience for the user.
Dynamic Load Balancing
With dynamic load balancing, load balancers forward requests to the app instances based on the current state of these instances. As a result, the dynamic load balancers can adapt to the ongoing changes of the app instances and tend to be more efficient than the static load balancers. However, dynamic load balancing is more complicated to implement. Some examples of dynamic load balancing methods are:
- Least connection: With the least connection load balancing method, the requests are forwarded to the app instance with the lowest number of active connections.
- Weighted least connection: The weighted least connection method will forward the requests to the app instance based on the number of active connections and the weighting of that instance. For example, if there are three app instances with the same number of active connections, the one with the highest weighting number will be chosen to forward the request.
Load Balancer in the Cloud
Setting up and maintaining a group of load balancers is a challenging task. To create and manage load balancers efficiently, you need to:
- Have a number of different load-balancing algorithms to support different internal business use cases
- Monitor your system health for the application instances
- Configure access controls and protection for your load balancers to prevent malicious access from the public internet
- Ensure scalability of your load balancer as your application needs grow
Gcore’s Load Balancer
At Gcore, we understand the difficulties and challenges of setting up a load balancer from scratch. There are a huge number of options available, and your choice directly affects performance and user experience—for better or for worse. Gcore’s Load Balancer solves these challenges and comes with built-in features support for:
- Different load balancing algorithms such as Round Robin, least connections, and source IP, so that you can choose the one that fits your need
- Setting up unhealthy and healthy thresholds
- Setting up the load balancers firewall, which allows you to set the rules for inbound and outbound traffic to enhance security
To learn more about how to get started, configure, and troubleshoot the Gcore load balancing solutions, please take a look at our knowledge page.
Conclusion
With a growing number of users coming to your app, having a load balancer to distribute user requests to your instances appropriately is essential for performance and user experience. However, setting up a load balancer that appropriately distributes user requests takes a lot of work. The Gcore load balancing solutions helps you to distribute your user workload in the most elegant and efficient way possible.
Related articles





Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial

Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.