
Edge computing refers to a variety of technologies that can lower the latency of cloud services. The geographical distance between the end user and the server is the most impactful factor on latency. All edge computing technologies address the issue by bringing computing resources closer to their users, with specific edge technologies varying in the measures they take to achieve this. Read on to learn about the differences between edge computing technologies, their benefits and applications, and their future potential.
The Goal of Edge Computing
The goal of edge computing is to deliver low-latency services. It takes a decentralized approach, placing computing nodes in locations near users, such as smaller data centers, cell towers, or embedded servers.
Edge computing is an addition to the centralized model of traditional cloud computing, where servers are located in large, central data centers. While cloud focuses on maximizing raw compute performance, edge is concerned with minimizing latency.

How Does Edge Computing Work?
Edge computing works by adding servers in strategic locations close to end users. The main controllable factor that impacts latency is the distance between the client and the server, so placing servers geographically closer to clients is the only way to lower latency meaningfully.
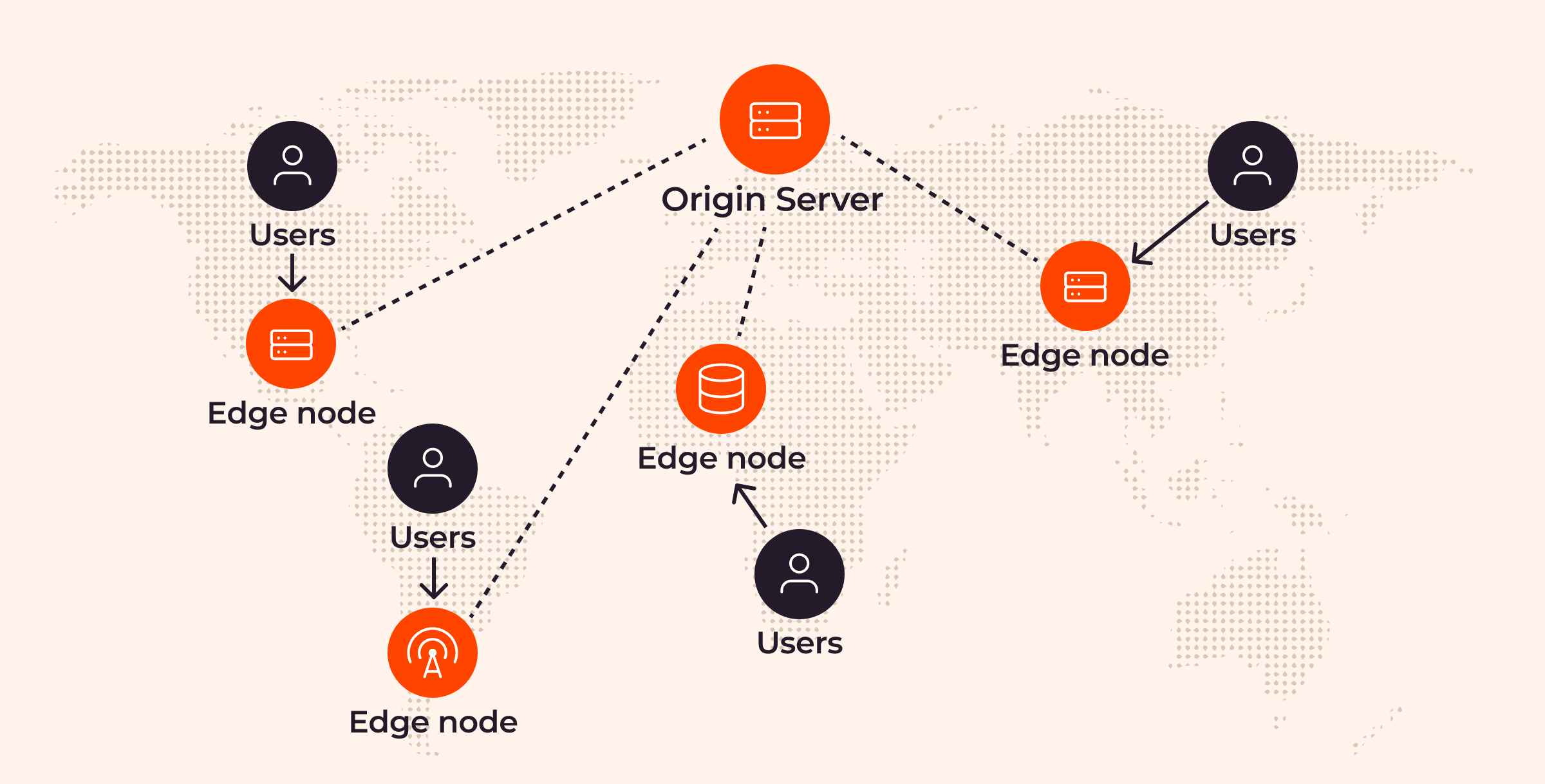
The specific method of implementing edge computing depends on the use case and level. Let’s look at those in more depth to understand more of the nuances of how edge computing works.
The Edge Computing Levels
Let’s explore the various levels of edge computing, their specific contexts, locations, and achievable latency ranges.

Traditional Cloud
First, we need to look at the traditional cloud model to establish a baseline. This level is suitable for data- and computation-intensive workloads, backups, and disaster recovery. The traditional cloud model allows the rental of substantial hardware resources, physical and virtual, by the minute, or even by the second, accommodating high-intensity workloads and providing redundant storage solutions that most organizations cannot independently manage.
Cloud providers house computing resources in large data centers. Latency can be as low as tens of milliseconds for users near the data center, but it may exceed a second for users located on the opposite side of the world.
Metro Edge
The metro edge level typically serves content delivery, regional compliance, and smart city applications. Here, computing resources are positioned within the same metropolitan area as the users, achieving latencies ranging from single-digit to lower double-digit milliseconds.
Metro edge often offers assurances about adherence to local data sovereignty laws as well as delivering lower latency. For example, a cloud service based in South America might not offer the GDPR protection that’s legally required in Europe; a metro edge provider based in Paris can deliver both GDPR compliance for local customers and lower their latency substantially.
Far Edge
The far edge is crucial for IoT, autonomous vehicles, and telecommunications, where even double-digit millisecond latencies are too high. At this level, computing resources are deployed at the edge of their network, such as cell towers, allowing latencies from sub-milliseconds to single-digit milliseconds.
On-Premises Edge
In sectors like manufacturing, healthcare, and retail, where microsecond-range latencies are necessary, the on-premises edge is ideal. For example, high-speed cameras that can inspect hundreds—or even thousands— of items per second allow for quality assurance in a manufacturing setting without slowing production.
As the name suggests, computing resources at this level are located on-premises, mere meters away from their users, allowing consistently microsecond-range latencies.
Edge Computing Industry Use Cases
To understand more about how edge computing works differently according to context, let’s look at some use cases. Many diverse industry sectors already leverage edge computing to improve their processes.
Retail
Smart shelves report which products they hold and how many items remain. This transforms the time-consuming task of manual stocktaking, which happens a few times yearly, into a continuous, automated process that offers real-time insights into a store’s inventory.
Edge computing facilitates this by enabling real-time data processing at the point of collection, such as the smart shelf, thus eliminating latency and allowing immediate updates on inventory levels. The benefit for the retailer is that they can optimize their inventory management, reduce out-of-stock scenarios, and improve customer satisfaction by ensuring products are always available when needed.
Generative AI
In the realm of generative AI, low-latency edge computing allows AI models to react faster and helps preserve input privacy. Edge-powered chatbots, for example, can recognize speech and generate responses rapidly, as they don’t have to send all inputs to remote data centers.
Smart Cities
Municipalities perform numerous distributed tasks. For example, traffic and waste management involve locations scattered throughout the city.
Edge computing allows devices like traffic lights to update their timing for optimized traffic flow by processing data on-site, which means the traffic light sensors can respond in real time to changes in traffic patterns without needing to send data back to a central server for processing, keeping traffic moving smoothly. Similarly, in waste management, edge computing can use waste bins equipped with sensors to communicate their current fill level. As a result, municipalities can adjust waste collection routes and schedules based on immediate needs, increasing efficiency and reducing unnecessary costs.
Automotive
While self-driving cars have garnered much attention, they are not the only IT-related application in modern cars. On-premises edge computing, where the vehicle itself is the “premise,” enables cars to anticipate maintenance and identify potential issues before they escalate, all without needing constant online connectivity.
Healthcare
Healthcare applications, such as image analysis for skin cancer detection and real-time patient monitoring in hospitals, benefit tremendously from the privacy that edge computing provides, enhancing patient data security. Edge computing provides privacy by processing data locally on the device itself. This significantly reduces the exposure of sensitive data to potential cyberthreats during transmission. Edge computing also helps to ensure compliance with local data privacy regulations, as the data can remain within the geographical boundaries where it was generated. This is particularly important in healthcare where patient data is highly sensitive and subject to strict privacy laws, like HIPAA in the US.
Finance
High-frequency trading is all about low latency. Placing an order just a few milliseconds earlier can be the difference between profit and loss. Edge computing reduces the distance between computing resources and financial exchanges, thus reducing latency.
Biometric authentication at ATMs is another interesting use case of edge in finance, where edge-powered face recognition can identify customers quickly, preventing fraudsters from using stolen credit cards.
The Benefits of Edge Computing
The benefits of edge computing are low latency, bandwidth savings, and improved privacy.
Low Latency
The primary benefit of edge computing is significantly reduced latency. Achieving latencies of single-digit milliseconds or even microseconds enables use cases that aren’t possible with traditional cloud deployments. For instance, a self-driving car can’t wait for seconds at each intersection, and high-frequency trading markets don’t wait for your next order. Either they’re performed fast or not at all!
Bandwidth Savings
Edge computing saves bandwidth by allowing the filtering of data before sending it to the main servers in a traditional cloud location, or the compression of media-on-demand before sending it to a client with low hardware specs or a slow internet connection. This early-stage processing reduces the data volume sent over the internet, thereby easing the load on downstream networks and potentially lowering associated costs.
Improved Privacy
It’s possible to leverage privacy-optimized edge computing on the on-premises edge level to reduce its exposure to public networks—as we explored in the healthcare example above. However, privacy is not a default property of edge computing installations. Protecting sensitive data to comply with regional data protection requires explicit precautions, especially when working with private data, like health records or financial information.
Why Is Edge Computing Important?
Edge computing answers a number of current needs related to the ever-increasing number of connected devices, the limitations of traditional central servers in a globally connected environment, and current latency and privacy requirements.
Increase in Number of Devices
The number of internet-connected devices is growing faster than the computing power of centralized servers. To manage this trend, cloud computing took scaling from a vertical approach (accelerating servers to process more data) to horizontal (distributing workloads to multiple servers) one. Edge computing continues this distribution of workload, delivering low-latency performance even as the number of devices increases exponentially.
Limitations of Traditional Central Servers
When it comes to data processing, the traditional use of high-performance central servers can pose significant challenges. These powerhouse servers are not only expensive to install and maintain but also logistically complex to deploy in all the required locations. Since edge computing decentralizes data handling, each server only needs to manage a localized set of data, reducing the overall load and allowing for the use of smaller, less demanding, cheaper servers. It’s therefore possible to position servers across a much wider geographical scope. This way, edge computing solves the big-ticket problem of server deployment and maintenance, making data processing more efficient and accessible.
Traditional cloud computing isn’t gone; high-performance servers are still crucial for many use cases, but edge computing eases the burden and opens up resources for other tasks.
Today’s Latency and Privacy Requirements
Last but not least, state-of-the-art technology has new requirements for latency and privacy that cannot be met by merely increasing computing power in larger data centers. Autonomous cars require reaction times faster than 20 milliseconds, and hospitals must ensure the privacy of patient data, which is at risk when transmitted over the internet. Edge computing is able to meet these needs, whereas traditional cloud models simply can’t do so consistently.
The Future of Edge Computing
Edge computing brings new possibilities to task automation in multiple industries. The edge computing market will grow to a value of over $157 billion in the next decade, with an anticipated growth of 80% in the large enterprise segment. We can expect to see many new edge computing applications and companies moving their workloads to the edge to reap its benefits.
Improvements in device size and efficiency will enable edge computing to handle new workloads that aren’t possible today, while simultaneously moving existing workloads between different edge computing levels, allowing even faster response times.
Conclusion
Edge computing is an extension of traditional cloud computing. It provides low latency by bringing computing resources closer to the users that require them. Many modern solutions, like self-driving cars, real-time traffic management, or high-frequency trading require edge computing and wouldn’t be possible with traditional cloud alone. However, edge computing isn’t the evolutionary successor of cloud computing. While it helps with latency and privacy, workloads that require raw computing performance are still served well in a traditional cloud. Edge computing is a strategic addition that can fill the latency gaps in cloud computing deployments and relieve central servers from loads better handled in a distributed manner.
Gcore’s Edge Network includes a powerful global CDN delivering an average global latency of just 30 ms. With 150+ points of presence strategically located in 75+ countries across six continents, your end users will enjoy the benefits of edge computing no matter where in the world they’re located. We’re also launching AI Inference as a Service, an AI service at the edge, in early 2024. Watch this space!
Related articles
Cloud networking is the use and management of network resources, including hardware and software, hosted on public or private cloud infrastructures rather than on-premises equipment. Over 90% of enterprises are expected to adopt cloud netwo
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.