Gcore Thwarts 500 Million PPS DDoS Attack on Gaming Company
- July 6, 2023
- 2 min read

At the beginning of May 2023, Gcore thwarted a 500 Million PPS DDoS attack with a total capacity of more than 800 Gbps. It was the largest DDoS attack company’s customers suffered since the beginning of 2023.
The attackers used multiple approaches, as Andrey Slastenov, Head of Web Security at Gcore, explains:
“Firstly, attackers targeted the game app at the L7 level with a large amount of traffic, which suggests that they were trying to overload the application layer of the gaming company’s infrastructure. They probably used botnets or amplification techniques. After this initial attack, the attackers switched tactics and continued the DDoS assault using a huge volume of small packets.”

Most attacks have relatively low speeds—one million PPS or less—but for web resources without protection that might be enough to be put out of action. An hour of downtime due to DDoS attacks in the gaming industry often costs upwards of $25,000.
How Gcore Stopped the Attack
Gcore used a distributed infrastructure and peering partners to spread traffic across multiple locations, reducing the impact of the attempted DDoS attack. Gcore’s protection team detected and mitigated the attack quickly, preventing disruption to the client’s web application. This highlights the importance of having a robust DDoS protection strategy and working with trusted security partners to ensure the availability and resilience of online services.
Why Are Cybercriminals Attacking Gaming Companies?
DDoS attacks are unfortunately common in the gaming industry, where attackers may target game servers, gaming websites, or even individual players. There are several reasons why DDoS attacks may target gaming companies:
- Desire for financial gain; attempting to extort money from the gaming company to stop the attack
- Attempt to disrupt gaming operations, gain a competitive advantage, or damage a company’s reputation, either by cybercriminals or competitors
- Retaliation by a player who feels unfairly treated by a gaming company
Regardless of the motivation behind the attack, DDoS attacks can cause severe damage to the gaming industry, leading to significant disruptions in online gaming services, and resulting in frustrated players, lost revenue, and reputational harm. The impact of such attacks can be devastating, as they can paralyze game servers, overwhelm website traffic, and compromise the integrity of player data.
How to Protect Against Powerful DDoS Attacks
To ensure the continuity of gaming operations, it is crucial for companies to prioritize DDoS protection and work closely with trusted security partners to identify and mitigate potential threats.
To mitigate DDoS attacks, companies must use DDoS protection services, deploy firewalls and intrusion prevention systems, and regularly test their security measures. Additionally, a gaming company can work with its internet service provider (ISP) and web protection provider to identify and block malicious traffic and improve DDoS resilience.
Protect yourself with Gcore—we provide protection at L3, L4, and L7 levels. Our solution has over 1 Tbps total filtering capacity and blocks DDoS attack from the first request by sessions, not IPs. Keeps your gaming services safe with us.

Related articles

Some AI jobs require the full power and predictability of dedicated bare metal clusters. Others need something more agile: compute that can be sized up or down quickly, used for a burst of experimentation, powered down when idle, and spun b
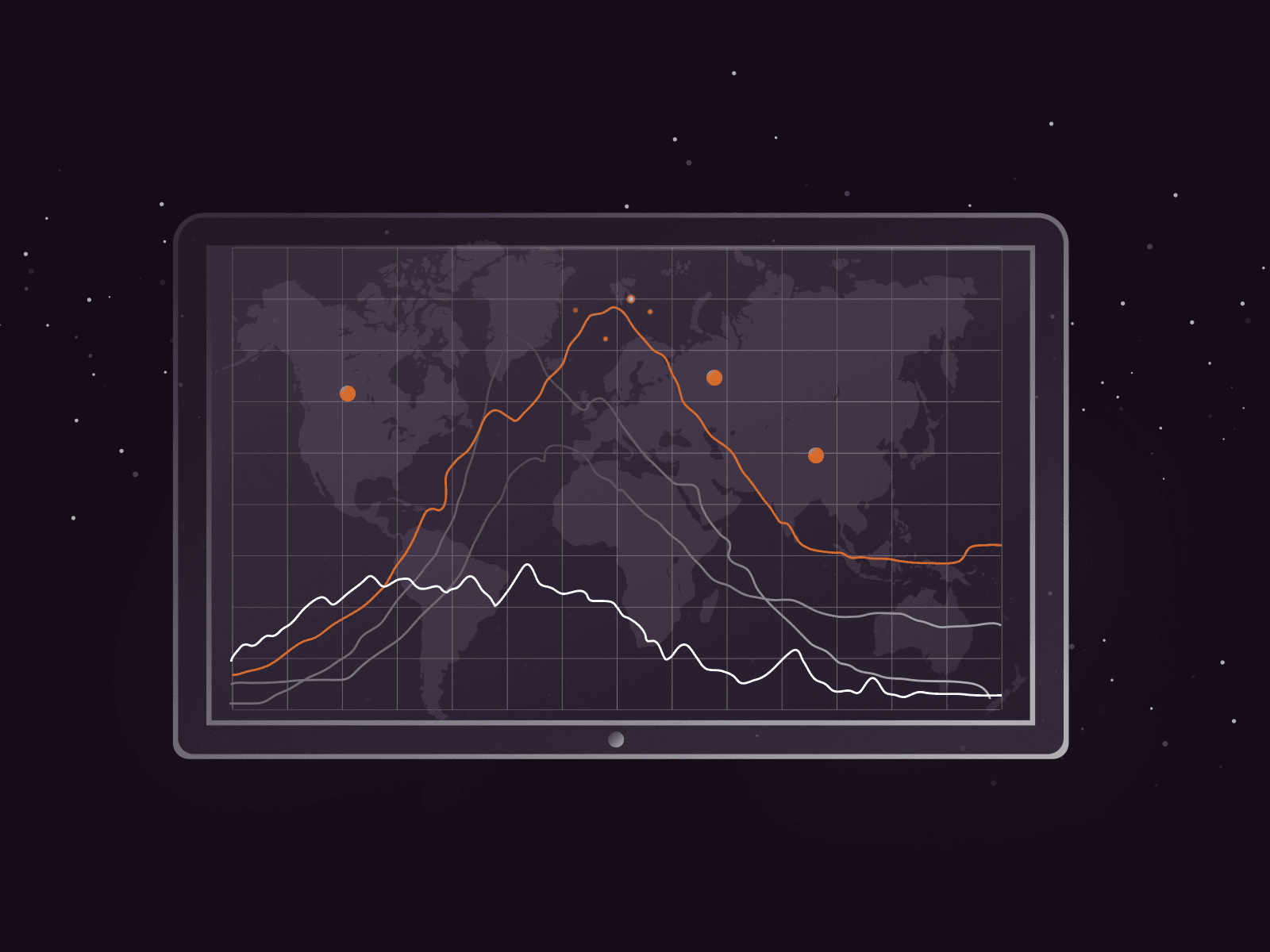
Cyberattacks are not just growing—they're accelerating at an alarming pace. The second half of 2025 marked a dramatic escalation in both the frequency and scale of DDoS attacks, with record-breaking volumes and increasingly sophisticated ta
AI adoption has a fragmentation problem. Organizations routinely stitch together separate tools for development, training, and serving, each with its own infrastructure, access controls, and operational overhead. The result is a patchwork t


Imagine if you could click a button and suddenly your GPUs increase their throughput by 6x. Or reduce latency by 2x. Or route inference requests seamlessly across different GPU types.That's the experience we're bringing to our inference cus
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.