
OpenFaaS is a serverless functions framework that runs on top of Docker and Kubernetes. In this tutorial, you’ll learn how to:
- Deploy OpenFaaS to a Kubernetes cluster
- Set up the OpenFaaS CLI
- Create, build, and deploy serverless functions using the CLI
- Invoke serverless functions using the CLI
- Update an existing serverless function
- Deploy serverless functions using the web interface
- Monitor your serverless functions with Prometheus and Grafana
Prerequisites
- A Kubernetes cluster. If you don’t have a running Kubernetes cluster, follow the instructions from the Set Up a Kubernetes Cluster with Kind section below.
- A Docker Hub Account. See the Docker Hub page for details about creating a new account.
- kubectl. Refer the Install and Set Up kubectl page for details about installing
kubectl. - Node.js 10 or higher. To check if Node.js is installed on your computer, type the following command:
node --versionThe following example output shows that Node.js is installed on your computer:
v10.16.3If Node.js is not installed or you’re running an older version, you can download the installer from the Downloads page.
- This tutorial assumes basic familiarity with Docker and Kubernetes.
Set Up a Kubernetes Cluster with Kind (Optional)
With Kind, you can run a local Kubernetes cluster using Docker containers as nodes. The steps in this section are optional. Follow them only if you don’t have a running Kubernetes cluster.
- Create a file named
openfaas-cluster.yaml, and copy in the following spec:
# three node (two workers) cluster configkind: ClusterapiVersion: kind.x-k8s.io/v1alpha4nodes:- role: control-plane- role: worker- role: worker- Use the
kind create clustercommand to create a Kubernetes cluster with one control plane and two worker nodes:
kind create cluster --config kind-specs/kind-cluster.yamlCreating cluster "kind" ... ✓ Ensuring node image (kindest/node:v1.17.0) 🖼 ✓ Preparing nodes 📦 📦 📦 ✓ Writing configuration 📜 ✓ Starting control-plane 🕹️ ✓ Installing CNI 🔌 ✓ Installing StorageClass 💾 ✓ Joining worker nodes 🚜Set kubectl context to "kind-kind"You can now use your cluster with:kubectl cluster-info --context kind-kindThanks for using kind! 😊Deploy OpenFaaS to a Kubernetes Cluster
You can install OpenFaaS using Helm, plain YAML files, or its own installer named arkade which provides a quick and easy way to get OpenFaaS running. In this section, you’ll deploy OpenFaaS with arkade.
- Enter the following command to install
arkade:
curl -sLS https://dl.get-arkade.dev | sudo shDownloading package https://github.com/alexellis/arkade/releases/download/0.1.10/arkade-darwin as /Users/andrei/Desktop/openFaaS/faas-hello-world/arkade-darwinDownload complete.Running with sufficient permissions to attempt to move arkade to /usr/local/binNew version of arkade installed to /usr/local/binCreating alias 'ark' for 'arkade'. _ _ __ _ _ __| | ____ _ __| | ___ / _` | '__| |/ / _` |/ _` |/ _ \| (_| | | | < (_| | (_| | __/ \__,_|_| |_|\_\__,_|\__,_|\___|Get Kubernetes apps the easy wayVersion: 0.1.10Git Commit: cf96105d37ed97ed644ab56c0660f0d8f4635996- Now, install
openfaaswith:
arkade install openfaasUsing kubeconfig: /Users/andrei/.kube/configUsing helm3Node architecture: "amd64"Client: "x86_64", "Darwin"2020/03/10 16:20:40 User dir established as: /Users/andrei/.arkade/https://get.helm.sh/helm-v3.1.1-darwin-amd64.tar.gz/Users/andrei/.arkade/bin/helm3/darwin-amd64 darwin-amd64//Users/andrei/.arkade/bin/helm3/README.md darwin-amd64/README.md/Users/andrei/.arkade/bin/helm3/LICENSE darwin-amd64/LICENSE/Users/andrei/.arkade/bin/helm3/helm darwin-amd64/helm2020/03/10 16:20:43 extracted tarball into /Users/andrei/.arkade/bin/helm3: 3 files, 0 dirs (1.633976582s)"openfaas" has been added to your repositoriesHang tight while we grab the latest from your chart repositories......Successfully got an update from the "ibm-charts" chart repository...Successfully got an update from the "openfaas" chart repository...Successfully got an update from the "stable" chart repository...Successfully got an update from the "bitnami" chart repositoryUpdate Complete. ⎈ Happy Helming!⎈VALUES values.yamlCommand: /Users/andrei/.arkade/bin/helm3/helm [upgrade --install openfaas openfaas/openfaas --namespace openfaas --values /var/folders/nz/2gtkncgx56sgrpqvr40qhhrw0000gn/T/charts/openfaas/values.yaml --set gateway.directFunctions=true --set faasnetes.imagePullPolicy=Always --set gateway.replicas=1 --set queueWorker.replicas=1 --set clusterRole=false --set operator.create=false --set openfaasImagePullPolicy=IfNotPresent --set basicAuthPlugin.replicas=1 --set basic_auth=true --set serviceType=NodePort]Release "openfaas" does not exist. Installing it now.NAME: openfaasLAST DEPLOYED: Tue Mar 10 16:21:03 2020NAMESPACE: openfaasSTATUS: deployedREVISION: 1TEST SUITE: NoneNOTES:To verify that openfaas has started, run: kubectl -n openfaas get deployments -l "release=openfaas, app=openfaas"======================================================================== OpenFaaS has been installed. ========================================================================# Get the faas-clicurl -SLsf https://cli.openfaas.com | sudo sh# Forward the gateway to your machinekubectl rollout status -n openfaas deploy/gatewaykubectl port-forward -n openfaas svc/gateway 8080:8080 &# If basic auth is enabled, you can now log into your gateway:PASSWORD=$(kubectl get secret -n openfaas basic-auth -o jsonpath="{.data.basic-auth-password}" | base64 --decode; echo)echo -n $PASSWORD | faas-cli login --username admin --password-stdinfaas-cli store deploy figletfaas-cli list# For Raspberry Pifaas-cli store list \ --platform armhffaas-cli store deploy figlet \ --platform armhf# Find out more at:# https://github.com/openfaas/faasThanks for using arkade!- To verify that the deployments were created, run the
kubectl get deploymentscommand. Specify the namespace and the selector using the-nand-lparameters as follows:
kubectl get deployments -n openfaas -l "release=openfaas, app=openfaas"If the deployments are not yet ready, you should see something similar to the following example output:
NAME READY UP-TO-DATE AVAILABLE AGEalertmanager 0/1 1 0 45sbasic-auth-plugin 1/1 1 1 45sfaas-idler 0/1 1 0 45sgateway 0/1 1 0 45snats 1/1 1 1 45sprometheus 1/1 1 1 45squeue-worker 1/1 1 1 45sOnce the installation is finished, the output should look like this:
NAME READY UP-TO-DATE AVAILABLE AGEalertmanager 1/1 1 1 75sbasic-auth-plugin 1/1 1 1 75sfaas-idler 1/1 1 1 75sgateway 1/1 1 1 75snats 1/1 1 1 75sprometheus 1/1 1 1 75squeue-worker 1/1 1 1 75s- Check the rollout status of the
gatewaydeployment:
kubectl rollout status -n openfaas deploy/gatewayThe following example output shows that the gateway deployment has been successfully rolled out:
deployment "gateway" successfully rolled out- Use the
kubectl port-forwardcommand to forward all requests made tohttp://localhost:8080
to the pod running thegateway
service:
kubectl port-forward -n openfaas svc/gateway 8080:8080 &[1] 78674Forwarding from 127.0.0.1:8080 -> 8080Forwarding from [::1]:8080 -> 8080Note that the ampersand sign (&) runs the process in the background. You can use the jobs command to show the status of your background processes:
jobs[1] + running kubectl port-forward -n openfaas svc/gateway 8080:8080- Issue the following command to retrieve your password and save it into an environment variable named
PASSWORD:
PASSWORD=$(kubectl get secret -n openfaas basic-auth -o jsonpath="{.data.basic-auth-password}" | base64 --decode; echo)Set Up the OpenFaaS CLI
OpenFaaS provides a command-line utility you can use to build and deploy your serverless functions. You can install it by following the steps from the Installation page.
Create a Serverless Function Using the CLI
Now that OpenFaaS and the faas-cli command-line utility are installed, you can create and deploy serverless functions using the built-in template engine. OpenFaaS provides two types of templates:
- The Classic templates are based on the Classic Watchdog and use
stdioto communicate with your serverless function. Refer to the Watchdog page for more details about how OpenFaaS Watchdog works. - The of-watchdog templates use HTTP to communicate with your serverless function. These templates are available through the OpenFaaS Incubator GitHub repository.
In this tutorial, you’ll use a classic template.
- Run the following command to see the templates available in the official store:
faas-cli template store listNAME SOURCE DESCRIPTIONcsharp openfaas Classic C# templatedockerfile openfaas Classic Dockerfile templatego openfaas Classic Golang templatejava8 openfaas Classic Java 8 templatenode openfaas Classic NodeJS 8 templatephp7 openfaas Classic PHP 7 templatepython openfaas Classic Python 2.7 templatepython3 openfaas Classic Python 3.6 templatepython3-dlrs intel Deep Learning Reference Stack v0.4 for ML workloadsruby openfaas Classic Ruby 2.5 templatenode10-express openfaas-incubator Node.js 10 powered by express templateruby-http openfaas-incubator Ruby 2.4 HTTP templatepython27-flask openfaas-incubator Python 2.7 Flask templatepython3-flask openfaas-incubator Python 3.6 Flask templatepython3-http openfaas-incubator Python 3.6 with Flask and HTTPnode8-express openfaas-incubator Node.js 8 powered by express templategolang-http openfaas-incubator Golang HTTP templategolang-middleware openfaas-incubator Golang Middleware templatepython3-debian openfaas Python 3 Debian templatepowershell-template openfaas-incubator Powershell Core Ubuntu:16.04 templatepowershell-http-template openfaas-incubator Powershell Core HTTP Ubuntu:16.04 templaterust booyaa Rust templatecrystal tpei Crystal templatecsharp-httprequest distantcam C# HTTP templatecsharp-kestrel burtonr C# Kestrel HTTP templatevertx-native pmlopes Eclipse Vert.x native image templateswift affix Swift 4.2 Templatelua53 affix Lua 5.3 Templatevala affix Vala Templatevala-http affix Non-Forking Vala Templatequarkus-native pmlopes Quarkus.io native image templateperl-alpine tmiklas Perl language template based on Alpine imagenode10-express-service openfaas-incubator Node.js 10 express.js microservice templatecrystal-http koffeinfrei Crystal HTTP templaterust-http openfaas-incubator Rust HTTP templatebash-streaming openfaas-incubator Bash Streaming template☞ Note that you can specify an alternative store for templates. The following example command lists the templates from a repository named andreipope:
faas-cli template store list -u https://raw.githubusercontent.com/andreipope/my-custom-store/master/templates.json- Download the official templates locally:
faas-cli template pullFetch templates from repository: https://github.com/openfaas/templates.git at master2020/03/11 20:51:22 Attempting to expand templates from https://github.com/openfaas/templates.git2020/03/11 20:51:25 Fetched 19 template(s) : [csharp csharp-armhf dockerfile go go-armhf java11 java11-vert-x java8 node node-arm64 node-armhf node12 php7 python python-armhf python3 python3-armhf python3-debian ruby] from https://github.com/openfaas/templates.git☞ By default, the above command downloads the templates from the OpenFaaS official GitHub repository. If you want to use a custom repository, then you should specify the URL of your repository. The following example command pulls the templates from a repository named andreipope:
faas-cli template pull https://github.com/andreipope/my-custom-store/- To create a new serverless function, run the
faas-cli newcommand specifying:
- The name of your new function (
appfleet-hello-world) - The
langparameter followed by the programming language template (node).
faas-cli new appfleet-hello-world --lang nodeFolder: appfleet-hello-world created. ___ _____ ____ / _ \ _ __ ___ _ __ | ___|_ _ __ _/ ___|| | | | '_ \ / _ \ '_ \| |_ / _` |/ _` \___ \| |_| | |_) | __/ | | | _| (_| | (_| |___) | \___/| .__/ \___|_| |_|_| \__,_|\__,_|____/ |_|Function created in folder: appfleet-hello-worldStack file written: appfleet-hello-world.ymlNotes:You have created a new function which uses Node.js 12.13.0 and the OpenFaaSClassic Watchdog.npm i --save can be used to add third-party packages like request or cheerionpm documentation: https://docs.npmjs.com/For high-throughput services, we recommend you use the node12 template whichuses a different version of the OpenFaaS watchdog.At this point, your directory structure should look like the following:
tree . -L 2.├── appfleet-hello-world│ ├── handler.js│ └── package.json├── appfleet-hello-world.yml└── template ├── csharp ├── csharp-armhf ├── dockerfile ├── go ├── go-armhf ├── java11 ├── java11-vert-x ├── java8 ├── node ├── node-arm64 ├── node-armhf ├── node12 ├── php7 ├── python ├── python-armhf ├── python3 ├── python3-armhf ├── python3-debian └── ruby21 directories, 3 filesThings to note:
- The
appfleet-hello-world/handler.jsfile contains the code of your serverless function. You can use theechocommand to list the contents of this file:
cat appfleet-hello-world/handler.js"use strict"module.exports = async (context, callback) => { return {status: "done"}}- You can specify the dependencies required by your serverless function in the
package.jsonfile. The automatically generated file is just an empty shell:
cat appfleet-hello-world/package.json{ "name": "function", "version": "1.0.0", "description": "", "main": "handler.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [], "author": "", "license": "ISC"}- The spec of the
appfleet-hello-worldfunction is stored in theappfleet-hello-world.ymlfile:
cat appfleet-hello-world.ymlversion: 1.0provider: name: openfaas gateway: http://127.0.0.1:8080functions: appfleet-hello-world: lang: node handler: ./appfleet-hello-world image: appfleet-hello-world:latestBuild Your Serverless Function
- Open the
appfleet-hello-world.ymlfile in a plain-text editor, and update theimagefield by prepending your Docker Hub user name to it. The following example prepends my username (andrepopescu12) to the image field:
image: andrepopescu12/appfleet-hello-world:latestOnce you’ve made this change, the appfleet-hello-world.yml file should look similar to the following:
version: 1.0provider: name: openfaas gateway: http://127.0.0.1:8080functions: appfleet-hello-world: lang: node handler: ./appfleet-hello-world image: <YOUR-DOCKER-HUB-ACCOUNT>/appfleet-hello-world:latest- Build the function. Enter the
faas-cli buildcommand specifying the-fargument with the name of the YAML file you edited in the previous step (appfleet-hello-world.yml):
faas-cli build -f appfleet-hello-world.yml[0] > Building appfleet-hello-world.Clearing temporary build folder: ./build/appfleet-hello-world/Preparing: ./appfleet-hello-world/ build/appfleet-hello-world/functionBuilding: andreipopescu12/appfleet-hello-world:latest with node template. Please wait..Sending build context to Docker daemon 10.24kBStep 1/24 : FROM openfaas/classic-watchdog:0.18.1 as watchdog ---> 94b5e0bef891Step 2/24 : FROM node:12.13.0-alpine as ship ---> 69c8cc9212ecStep 3/24 : COPY --from=watchdog /fwatchdog /usr/bin/fwatchdog ---> Using cache ---> ebab4b723c16Step 4/24 : RUN chmod +x /usr/bin/fwatchdog ---> Using cache ---> 7952724b5872Step 5/24 : RUN addgroup -S app && adduser app -S -G app ---> Using cache ---> 33c7f04595d2Step 6/24 : WORKDIR /root/ ---> Using cache ---> 77b9dee16c79Step 7/24 : ENV NPM_CONFIG_LOGLEVEL warn ---> Using cache ---> a3d3c0bb4480Step 8/24 : RUN mkdir -p /home/app ---> Using cache ---> 65457e03fcb1Step 9/24 : WORKDIR /home/app ---> Using cache ---> 50ab672e5660Step 10/24 : COPY package.json ./ ---> Using cache ---> 6143e79de873Step 11/24 : RUN npm i --production ---> Using cache ---> a41566487c6eStep 12/24 : COPY index.js ./ ---> Using cache ---> 566633e78d2cStep 13/24 : WORKDIR /home/app/function ---> Using cache ---> 04c9de75f170Step 14/24 : COPY function/*.json ./ ---> Using cache ---> 85cf909b646aStep 15/24 : RUN npm i --production || : ---> Using cache ---> c088cbcad583Step 16/24 : COPY --chown=app:app function/ . ---> Using cache ---> 192db89e5941Step 17/24 : WORKDIR /home/app/ ---> Using cache ---> ee2b7d7e8bd4Step 18/24 : RUN chmod +rx -R ./function && chown app:app -R /home/app && chmod 777 /tmp ---> Using cache ---> 81831389293eStep 19/24 : USER app ---> Using cache ---> ca0cade453f5Step 20/24 : ENV cgi_headers="true" ---> Using cache ---> afe8d7413349Step 21/24 : ENV fprocess="node index.js" ---> Using cache ---> 5471cfe85461Step 22/24 : EXPOSE 8080 ---> Using cache ---> caaa8ae11dc7Step 23/24 : HEALTHCHECK --interval=3s CMD [ -e /tmp/.lock ] || exit 1 ---> Using cache ---> 881b4d2adb92Step 24/24 : CMD ["fwatchdog"] ---> Using cache ---> 82b586f039dfSuccessfully built 82b586f039dfSuccessfully tagged andreipopescu12/appfleet-hello-world:latestImage: andreipopescu12/appfleet-hello-world:latest built.[0] < Building appfleet-hello-world done in 2.25s.[0] Worker done.Total build time: 2.25s- You can list your Docker images with:
docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEandreipopescu12/appfleet-hello-world latest 82b586f039df 25 minutes ago 96MBPush Your Image to Docker Hub
- Log in to Docker Hub. Run the
docker logincommand with the--usernameflag followed by your Docker Hub user name. The following example command logs you in asandreipopescu12:
docker login --username andreipopescu12Next, you will be prompted to enter your Docker Hub password:
Password:Login Succeeded- Use the
faas-cli pushcommand to push your serverless function to Docker Hub:
faas-cli push -f appfleet-hello-world.ymlThe push refers to repository [docker.io/andreipopescu12/appfleet-hello-world]073c41b18852: Pusheda5c05e98c215: Pushedf749ad113dce: Pushede4f29400b370: Pushedb7d0eb42e645: Pushed84fba0eb2756: Pushedcf2a3f2bc398: Pushed942d3272b7d4: Pushed037b653b7d4e: Pushed966655dc62be: Pushed08d8e0925a73: Pushed6ce16b164ed0: Pushedd76ecd300100: Pushed77cae8ab23bf: Pushedlatest: digest: sha256:4150d4cf32e7e5ffc8fd15efeed16179bbf166536f1cc7a8c4105d01a4042928 size: 3447[0] < Pushing appfleet-hello-world [andreipopescu12/appfleet-hello-world:latest] done.[0] Worker done.Deploy Your Function Using the CLI
- With your serverless function pushed to Docker Hub, log in to your local instance of the OpenFaaS gateway by entering the following command:
echo -n $PASSWORD | faas-cli login --username admin --password-stdin- Run the
faas-cli deploycommand to deploy your serverless function:
faas-cli deploy -f appfleet-hello-world.ymlDeploying: appfleet-hello-world.WARNING! Communication is not secure, please consider using HTTPS. Letsencrypt.org offers free SSL/TLS certificates.Handling connection for 8080Handling connection for 8080Deployed. 202 Accepted.URL: http://127.0.0.1:8080/function/appfleet-hello-world☞ OpenFaaS provides an auto-scaling mechanism based on the number of requests per second, which is read from Prometheus. For the sake of simplicity, we won’t cover auto-scaling in this tutorial. To further your knowledge, you can refer the Auto-scaling page.
- Use the
faas-cli listcommand to list the functions deployed to your local OpenFaaS gateway:
faas-cli listFunction Invocations Replicasappfleet-hello-world 0 1☞ Note that you can also list the functions deployed to a different gateway by providing the URL of the gateway as follows:
faas-cli list --gateway https://<YOUR-GATEWAT-URL>:<YOUR-GATEWAY-PORT>- You can use the
faas-cli describemethod to retrieve more details about theappfleet-hello-worldfunction:
faas-cli describe appfleet-hello-worldName: appfleet-hello-worldStatus: ReadyReplicas: 1Available replicas: 1Invocations: 1Image: andreipopescu12/appfleet-hello-world:latestFunction process: node index.jsURL: http://127.0.0.1:8080/function/appfleet-hello-worldAsync URL: http://127.0.0.1:8080/async-function/appfleet-hello-worldLabels: faas_function : appfleet-hello-worldAnnotations: prometheus.io.scrape : falseInvoke Your Serverless Function Using the CLI
- To see your serverless function in action, issue the
faas-cli invokecommand, specifying:
- The
-fflag with the name of the YAML file that describes your function (appfleet-hello-world.yml) - The name of your function (
appfleet-hello-world)
faas-cli invoke -f appfleet-hello-world.yml appfleet-hello-worldReading from STDIN - hit (Control + D) to stop.- Type
CTRL+D. The following example output shows that your serverless function works as expected:
appfleetHandling connection for 8080{"status":"done"}Update Your Function
The function you created, deployed, and then invoked in the previous sections is just an empty shell. In this section, we’ll update it to:
- Read the name of a city from
stdin - Fetch the weather forecast from the openweathermap.org
- Print to the console the weather forecast
- Create an OpenWeatherMap account by following the instructions from the Sign Up page.
- Log in to OpenWeatherMap and then select API KEYS:
- From here, you can either copy the value of the default key or create a new API key, and then copy its value:
- Now that you have an OpenWeatherMap API key, you must use
npmto install a few dependencies. The following command moves into theappfleet-hello-worlddirectory and then installs theget-stdinandrequestpackages:
cd appfleet-hello-world && npm i --save get-stdin request- Replace the content of the
handler.jsfile with:
"use strict"const getStdin = require('get-stdin')const request = require('request');let handler = (req) => { request(`http://api.openweathermap.org/data/2.5/weather?q=${req}&?units=metric&APPID=<YOUR-OPENWEATHERMAP-APP-KEY>`, function (error, response, body) { console.error('error:', error) console.log('statusCode:', response && response.statusCode) console.log('body:', JSON.stringify(body)) })};getStdin().then(val => { handler(val);}).catch(e => { console.error(e.stack);});module.exports = handler☞ To try this function, replace <YOUR-OPENWEATHERMAP-API-KEY> with your OpenWeatherMap API KEY.
- You can use the
faas-cli removecommand to remove the function you’ve deployed earlier in this tutorial:
faas-cli remove appfleet-hello-worldDeleting: appfleet-hello-world.Handling connection for 8080Removing old function.- Now that the old function has been removed, you must rebuild, push, and deploy your modified function. Instead of issuing three separate commands, you can use the
openfaas-cli upcommand as in the following example:
faas-cli up -f appfleet-hello-world.yml[0] > Building appfleet-hello-world.Clearing temporary build folder: ./build/appfleet-hello-world/Preparing: ./appfleet-hello-world/ build/appfleet-hello-world/functionBuilding: andreipopescu12/appfleet-hello-world:latest with node template. Please wait..Sending build context to Docker daemon 43.01kBStep 1/24 : FROM openfaas/classic-watchdog:0.18.1 as watchdog ---> 94b5e0bef891Step 2/24 : FROM node:12.13.0-alpine as ship ---> 69c8cc9212ecStep 3/24 : COPY --from=watchdog /fwatchdog /usr/bin/fwatchdog ---> Using cache ---> ebab4b723c16Step 4/24 : RUN chmod +x /usr/bin/fwatchdog ---> Using cache ---> 7952724b5872Step 5/24 : RUN addgroup -S app && adduser app -S -G app ---> Using cache ---> 33c7f04595d2Step 6/24 : WORKDIR /root/ ---> Using cache ---> 77b9dee16c79Step 7/24 : ENV NPM_CONFIG_LOGLEVEL warn ---> Using cache ---> a3d3c0bb4480Step 8/24 : RUN mkdir -p /home/app ---> Using cache ---> 65457e03fcb1Step 9/24 : WORKDIR /home/app ---> Using cache ---> 50ab672e5660Step 10/24 : COPY package.json ./ ---> Using cache ---> 6143e79de873Step 11/24 : RUN npm i --production ---> Using cache ---> a41566487c6eStep 12/24 : COPY index.js ./ ---> Using cache ---> 566633e78d2cStep 13/24 : WORKDIR /home/app/function ---> Using cache ---> 04c9de75f170Step 14/24 : COPY function/*.json ./ ---> Using cache ---> f5765914bd05Step 15/24 : RUN npm i --production || : ---> Using cache ---> a300be28c096Step 16/24 : COPY --chown=app:app function/ . ---> 91cd72d8ad7aStep 17/24 : WORKDIR /home/app/ ---> Running in fce50a76475aRemoving intermediate container fce50a76475a ---> 0ff17b0a9fafStep 18/24 : RUN chmod +rx -R ./function && chown app:app -R /home/app && chmod 777 /tmp ---> Running in 6d0c4c92fac1Removing intermediate container 6d0c4c92fac1 ---> 1e543bfbf6b0Step 19/24 : USER app ---> Running in 6d33f5ec237dRemoving intermediate container 6d33f5ec237d ---> cb7cf5dfab12Step 20/24 : ENV cgi_headers="true" ---> Running in 972c23374934Removing intermediate container 972c23374934 ---> 21c6e8198b21Step 21/24 : ENV fprocess="node index.js" ---> Running in 3be91f9d5228Removing intermediate container 3be91f9d5228 ---> aafb7a756d38Step 22/24 : EXPOSE 8080 ---> Running in da3183bd88c5Removing intermediate container da3183bd88c5 ---> 5f6fd7e66a95Step 23/24 : HEALTHCHECK --interval=3s CMD [ -e /tmp/.lock ] || exit 1 ---> Running in a590c91037aeRemoving intermediate container a590c91037ae ---> fbe20c32941fStep 24/24 : CMD ["fwatchdog"] ---> Running in 59cd231f0576Removing intermediate container 59cd231f0576 ---> 88cd8ac65adeSuccessfully built 88cd8ac65adeSuccessfully tagged andreipopescu12/appfleet-hello-world:latestImage: andreipopescu12/appfleet-hello-world:latest built.[0] < Building appfleet-hello-world done in 13.95s.[0] Worker done.Total build time: 13.95s[0] > Pushing appfleet-hello-world [andreipopescu12/appfleet-hello-world:latest].The push refers to repository [docker.io/andreipopescu12/appfleet-hello-world]04643e0c999f: Pusheddb3ccc4403b8: Pushed24d1d5a62262: Layer already existsadfa28db7666: Layer already existsb7d0eb42e645: Layer already exists84fba0eb2756: Layer already existscf2a3f2bc398: Layer already exists942d3272b7d4: Layer already exists037b653b7d4e: Layer already exists966655dc62be: Layer already exists08d8e0925a73: Layer already exists6ce16b164ed0: Layer already existsd76ecd300100: Layer already exists77cae8ab23bf: Layer already existslatest: digest: sha256:818d92b10d276d32bcc459e2918cb537051a14025e694eb59a9b3caa0bb4e41c size: 3456[0] < Pushing appfleet-hello-world [andreipopescu12/appfleet-hello-world:latest] done.[0] Worker done.Deploying: appfleet-hello-world.WARNING! Communication is not secure, please consider using HTTPS. Letsencrypt.org offers free SSL/TLS certificates.Handling connection for 8080Handling connection for 8080Deployed. 202 Accepted.URL: http://127.0.0.1:8080/function/appfleet-hello-world☞ Note that you can skip the push or the deploy steps:
- The following example command skips the push step:
faas-cli up -f appfleet-hello-world.yml --skip-push- The following example command skips the deploy step:
faas-cli up -f appfleet-hello-world.yml --skip-deploy- To verify that the updated serverless function works as expected, invoke it as follows:
faas-cli invoke -f appfleet-hello-world.yml appfleet-hello-worldReading from STDIN - hit (Control + D) to stop.BerlinHandling connection for 8080Hello, you are currently in BerlinstatusCode: 200body: "{\"coord\":{\"lon\":13.41,\"lat\":52.52},\"weather\":[{\"id\":802,\"main\":\"Clouds\",\"description\":\"scattered clouds\",\"icon\":\"03d\"}],\"base\":\"stations\",\"main\":{\"temp\":282.25,\"feels_like\":270.84,\"temp_min\":280.93,\"temp_max\":283.15,\"pressure\":1008,\"humidity\":61},\"visibility\":10000,\"wind\":{\"speed\":13.9,\"deg\":260,\"gust\":19},\"clouds\":{\"all\":40},\"dt\":1584107132,\"sys\":{\"type\":1,\"id\":1275,\"country\":\"DE\",\"sunrise\":1584077086,\"sunset\":1584119213},\"timezone\":3600,\"id\":2950159,\"name\":\"Berlin\",\"cod\":200}"- To clean-up, run the
faas-cli removecommand with the name of your serverless function (appfleet-hello-worldas an argument):
faas-cli remove appfleet-hello-worldDeleting: appfleet-hello-world.Handling connection for 8080Removing old function.Deploy Serverless Functions Using the Web Interface
OpenFaaS provides a web-based user interface. In this section, you’ll learn how you can use it to deploy a serverless function.
- First, you must use the
echocommand to retrieve your password:
echo $PASSWORD49IoP28G8247MZcj6a1FWUYUx- Open a browser and visit
http://localhost:8080
. To log in, use theadminusername and the password you retrieved in the previous step. You will be redirected to the OpenFaaS home page. Select the DEPLOY NEW FUNCTION button:

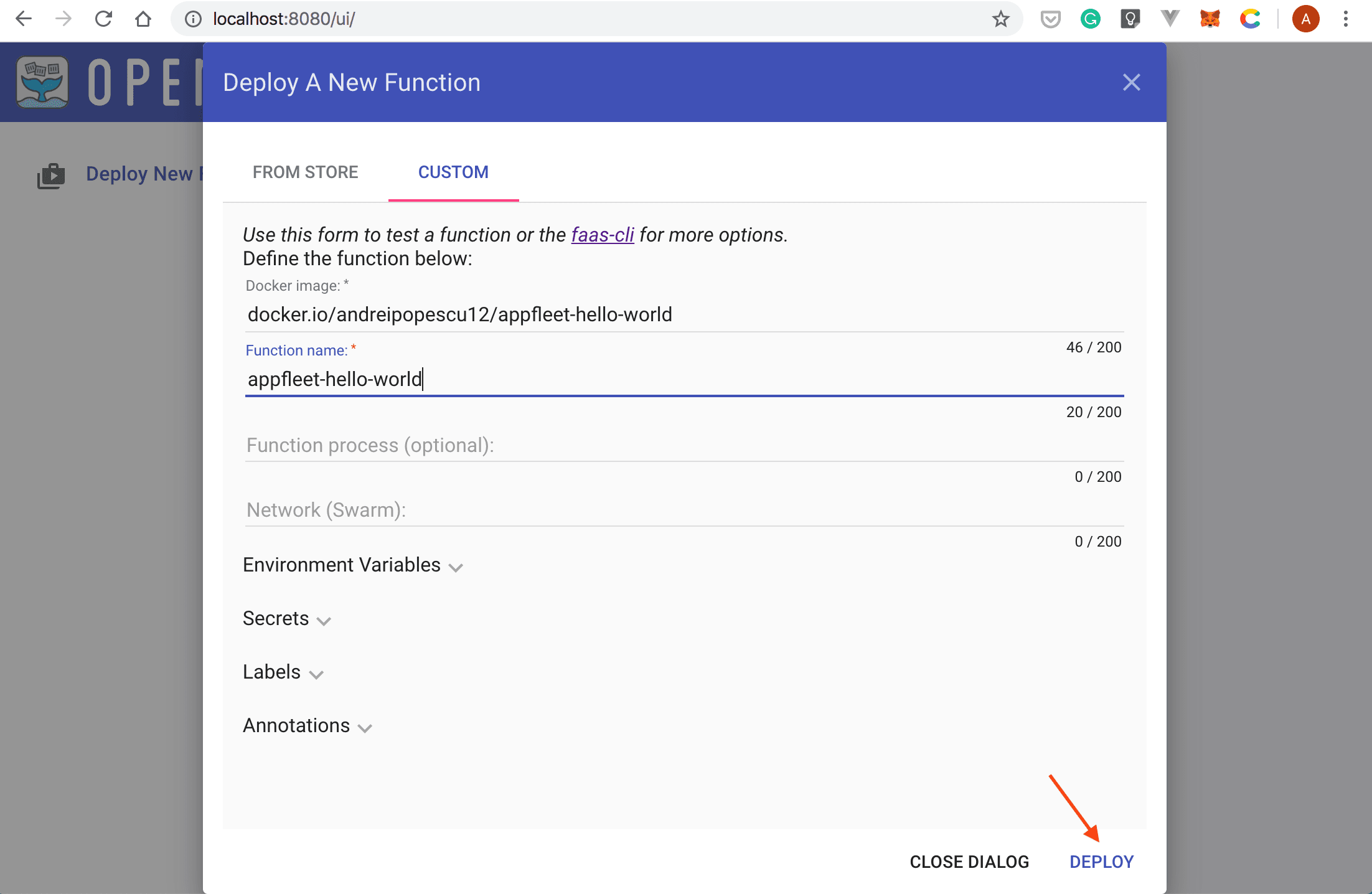
- A new window will be displayed. Select the Custom tab, and then type:
docker.io/andreipopescu12/appfleet-hello-worldin the Docker Image input boxappfleet-hello-worldin the Function name input box

- Once you’ve filled in the Docker image and Function name input boxes, select the DEPLOY button:
- Your new function will be visible in the left navigation bar. Click on it:

You’ll be redirected to the invoke function page:
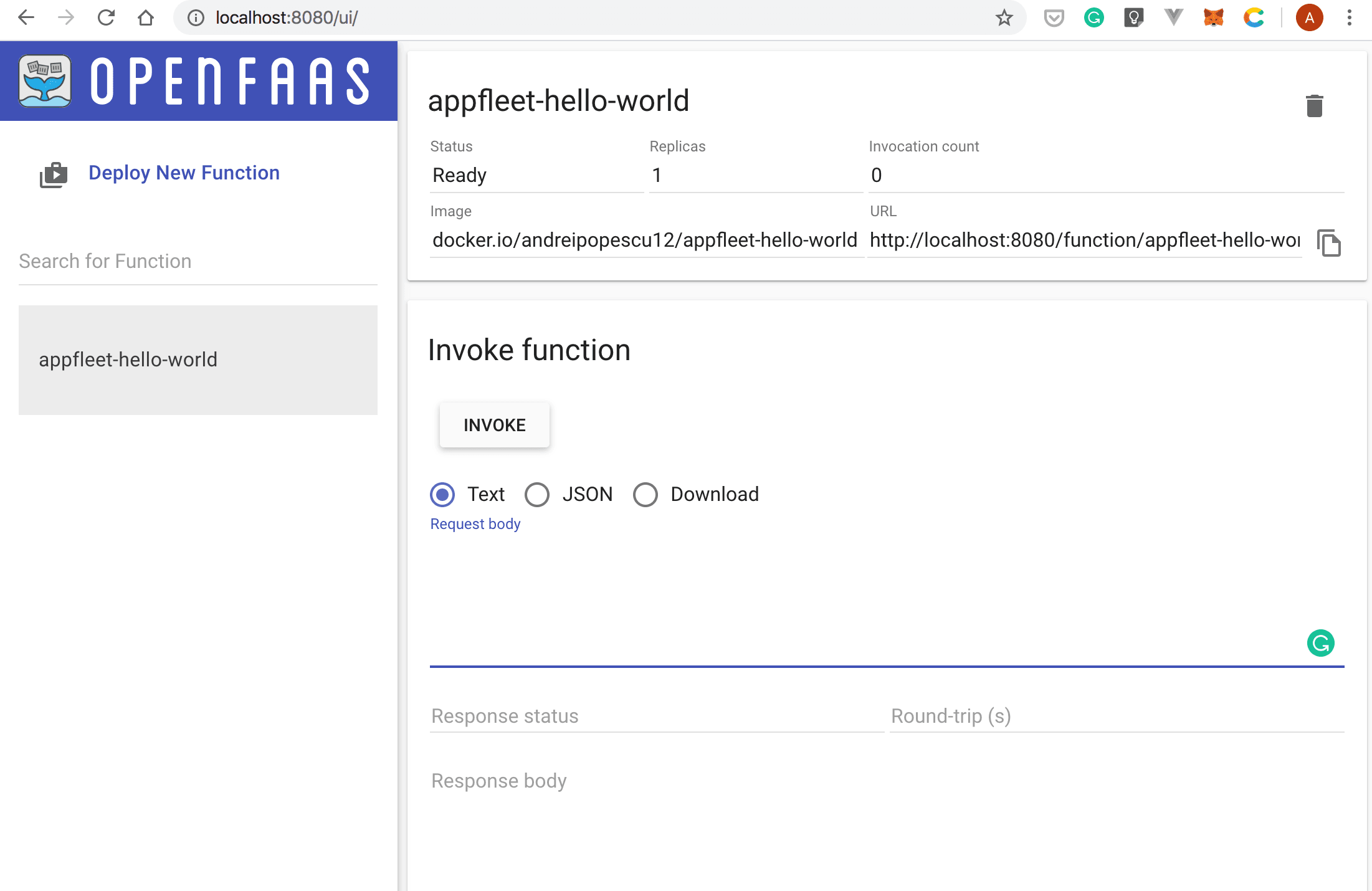
- In the Request body input box, type in the name of the city you want to retrieve the weather forecast for, and then select the INVOKE button:

If everything works well, the weather forecast will be displayed in the Response Body field:

Monitor Your Serverless Functions with Prometheus and Grafana
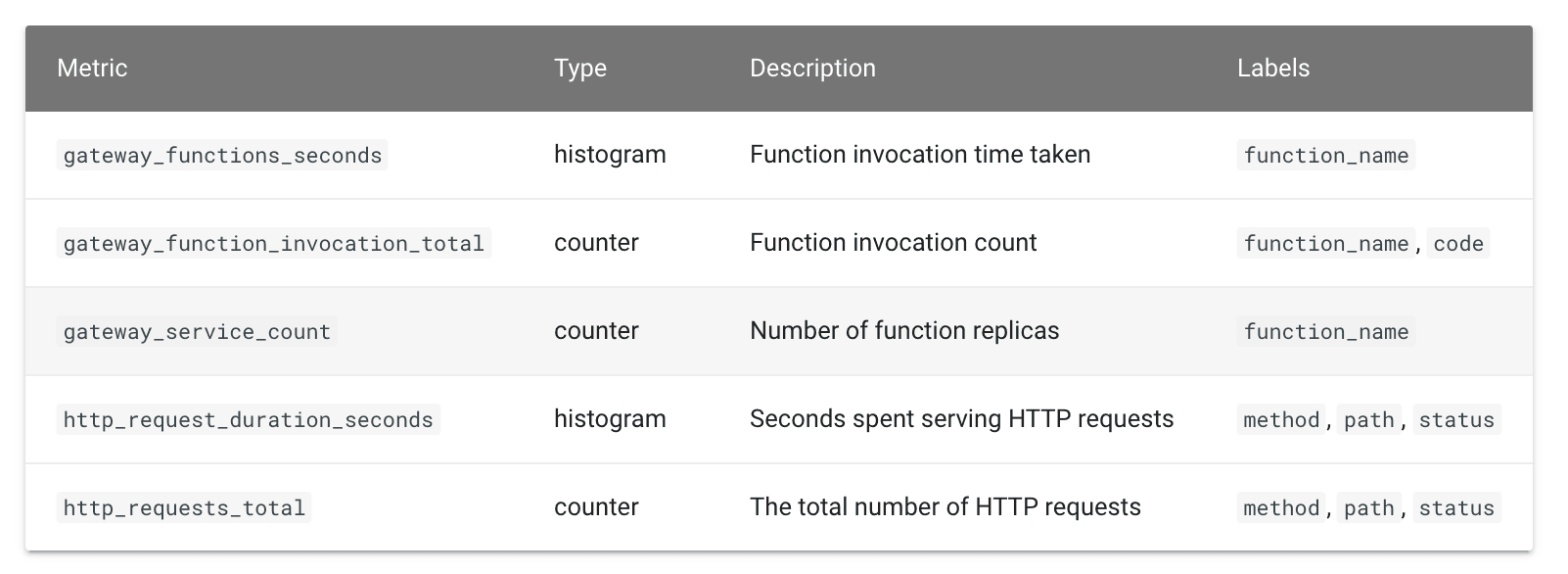
The OpenFaaS gateway exposes the following metrics:
In this section, you will learn how to set up Prometheus and Grafana to track the health of your serverless functions.
- Use the following command to list your deployments:
kubectl get deployments -n openfaas -l "release=openfaas, app=openfaas"NAME READY UP-TO-DATE AVAILABLE AGEalertmanager 1/1 1 1 15mbasic-auth-plugin 1/1 1 1 15mfaas-idler 1/1 1 1 15mgateway 1/1 1 1 15mnats 1/1 1 1 15mprometheus 1/1 1 1 15mqueue-worker 1/1 1 1 15m- To expose the
prometheusdeployment, create a service object namedprometheus-ui:
kubectl expose deployment prometheus -n openfaas --type=NodePort --name=prometheus-uiservice/prometheus-ui exposed☞ The --type=NodePort flag exposes the prometheus-ui service on each of the node’s IP addresses. Also, a ClusterIP service is created. You’ll use this to connect to the prometheus-ui service from outside of the cluster.
- To inspect the
prometheus-uiservice, enter the following command:
kubectl get svc prometheus-ui -n openfaasNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEprometheus-ui NodePort 10.96.129.204 <none> 9090:31369/TCP 8m1s- Forward all requests made to
http://localhost:9090
to the pod running theprometheus-uiservice:
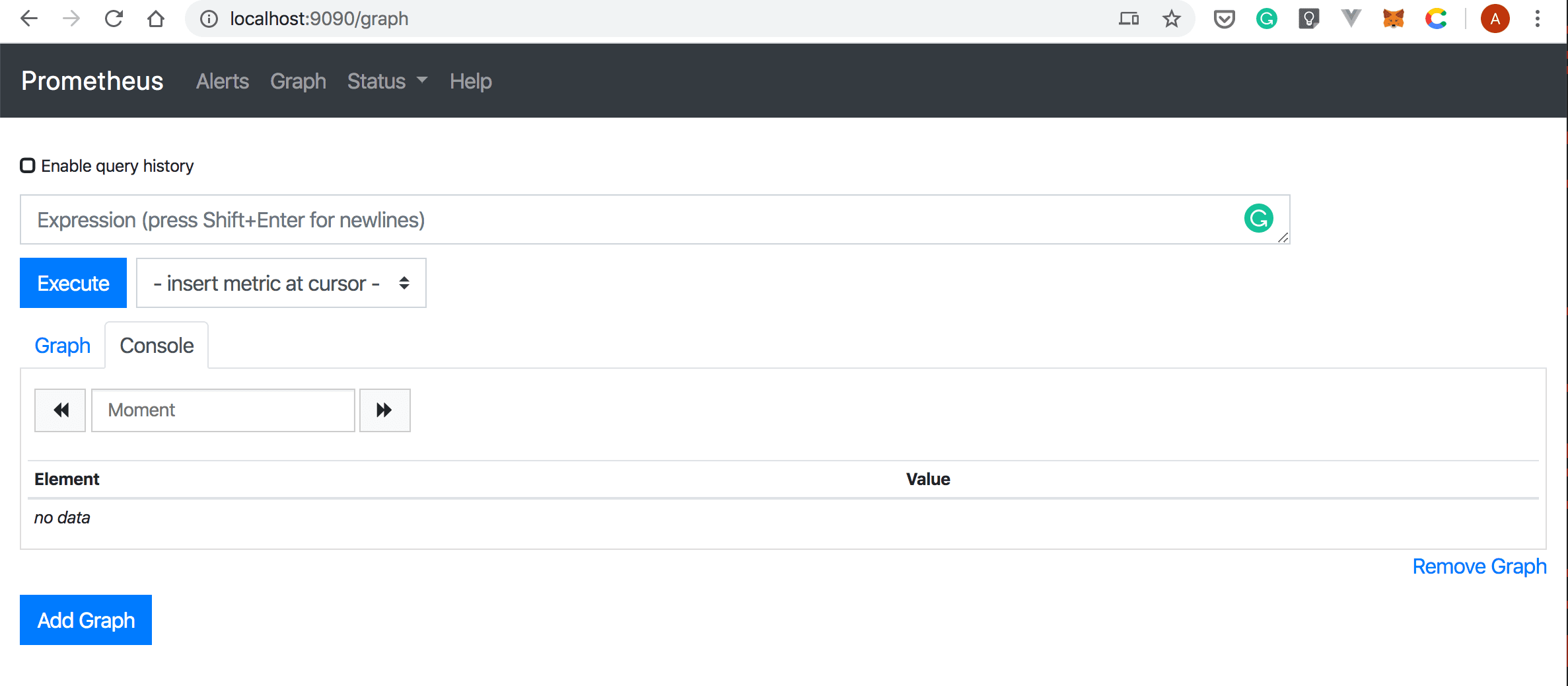
kubectl port-forward -n openfaas svc/prometheus-ui 9090:9090 &- Now, you can point your browser to
http://localhost:9090
, and you should see a page similar to the following screenshot:
- To deploy Grafana, you’ll the
stefanprodan/faas-grafana:4.6.3image. Run the following command:
kubectl run grafana -n openfaas --image=stefanprodan/faas-grafana:4.6.3 --port=3000kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.deployment.apps/grafana created- Now, you can list your deployments with:
kubectl get deployments -n openfaasNAME READY UP-TO-DATE AVAILABLE AGEalertmanager 1/1 1 1 46mbasic-auth-plugin 1/1 1 1 46mfaas-idler 1/1 1 1 46mgateway 1/1 1 1 46mgrafana 1/1 1 1 107snats 1/1 1 1 46mprometheus 1/1 1 1 46mqueue-worker 1/1 1 1 46m- Use the following
kubectl expose deploymentcommand to create a service object that exposes thegrafanadeployment:
kubectl expose deployment grafana -n openfaas --type=NodePort --name=grafanaservice/grafana exposed- Retrieve details about your new service with:
kubectl get service grafana -n openfaasNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEgrafana NodePort 10.96.194.59 <none> 3000:32464/TCP 60s- Forward all requests made to
http://localhost:3030
to the pod running thegrafanaservice:
kubectl port-forward -n openfaas svc/grafana 3000:3000 &[3] 3973Forwarding from 127.0.0.1:3000 -> 3000Forwarding from [::1]:3000 -> 3000- Now that you set up the port forwarding, you can access Grafana by pointing your browser to
http://localhost:3000
:

- Log into Grafana using the username
adminand passwordadmin. The Home Dashboard page will be displayed:

- From the left menu, select Dashboards –> Import:

- Type
https://grafana.com/grafana/dashboards/3434in the Grafana.com Dashboard input box. Then, select the Load button:

- In the Import Dashboard dialog box, set the Prometheus data source to
faas, and then select Import:

An empty dashboard will be displayed:
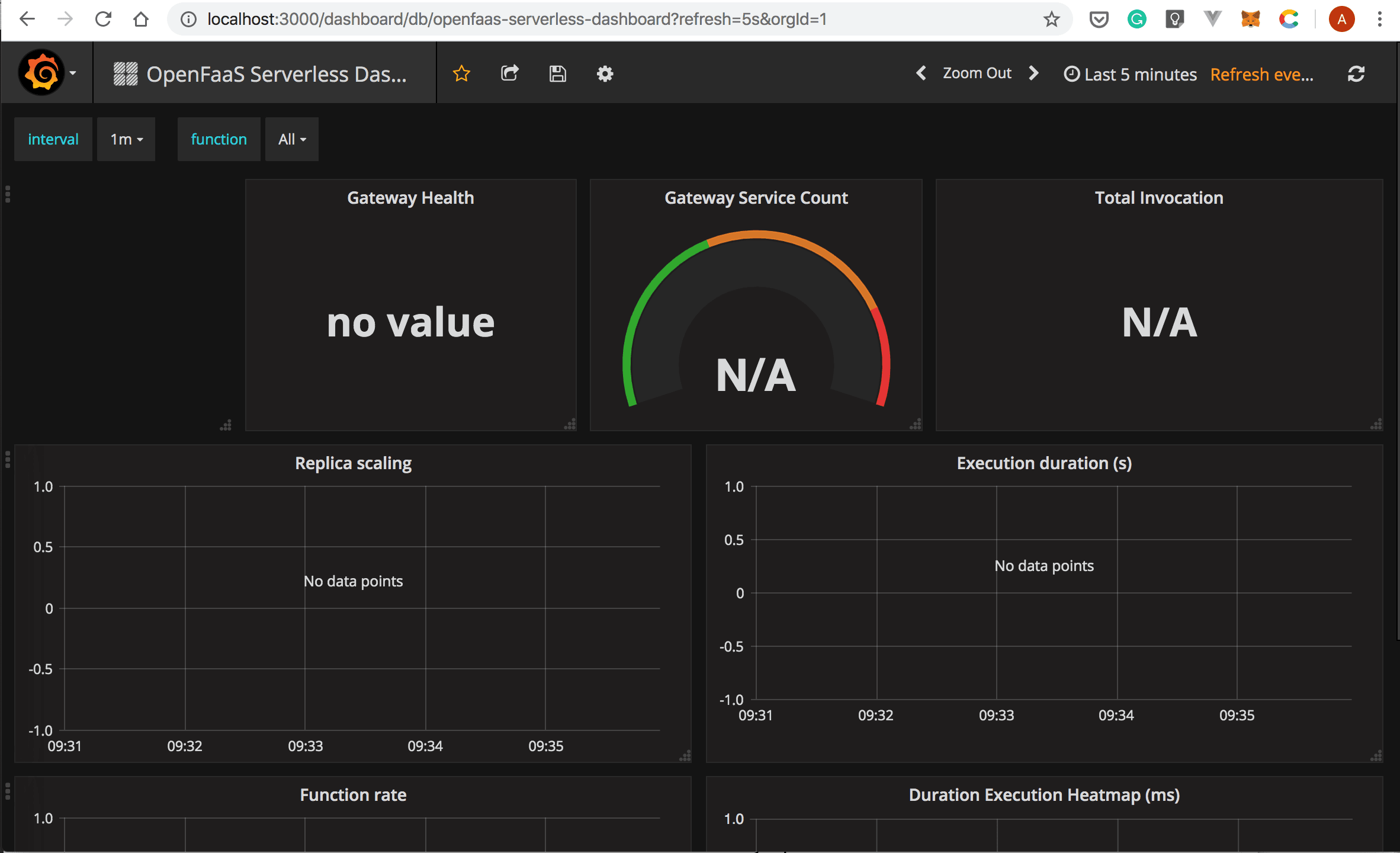
- Now, you can invoke your function a couple of times using the
faas-cli invokecommand as follows:
faas-cli invoke -f appfleet-hello-world.yml appfleet-hello-world- Switch back to the browser window that opened Grafana. Your dashboard should be automatically updated and look similar to the following screenshot:

We hope this tutorial was useful for learning the basics of deploying serverless functions with OpenFaaS.
Thanks for reading!
Related articles

Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial
Multi-cloud and hybrid cloud represent two distinct approaches to distributed computing architecture that build upon the foundation of cloud computing to help organizations improve their IT infrastructure.Multi-cloud environments involve us
Multi-cloud is a cloud usage model where an organization utilizes public cloud services from two or more cloud service providers, often combining public, private, and hybrid clouds, as well as different service models, such as Infrastructur
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.