Maximizing AI and HPC Workloads with NVIDIA H200 Tensor Core GPU
- January 9, 2024
- 6 min read

In the past decade, the fields of artificial intelligence (AI) in software and high-performance computing (HPC) in hardware have undergone a significant transformation. This revolution has led to breakthrough applications across diverse sectors, improving human life through advancements in fields such as genomic sequencing, fuel conservation, and earthquake prediction. Developing such applications requires researchers and developers to work with a gigantic volume of data using complex algorithms. Such demanding computing tasks require a new generation of data processors capable of tackling parallel and sophisticated workloads. In this article, we’ll explain how the upcoming NVIDIA H200 Tensor Core GPU, slated for release in Q2 of 2024, will help to optimize your AI and HPC workloads. We will also explore how this technology enables the efficient creation of data-driven applications and discuss the current alternatives available.
Why Use GPU for AI and HPC Workloads?
Let’s start by exploring why GPUs are the hardware of choice for running AI and HPC workloads, and what kinds of workloads we’re talking about.
Benefits of GPUs Compared to CPUs
To understand why the new NVIDIA H200 GPU (graphics processing unit) is so innovative compared to its previous GPU, it’s important to understand how GPUs differ from CPUs (central processing units) in application development. GPUs offer distinct advantages in processing speed and efficiency, particularly for tasks involving parallel calculations on a massive amount of data. For an in-depth look at the differences between GPUs and CPUs, particularly in the context of deep learning, see our detailed article on deep learning GPUs.
What Are AI Workloads and Where Do GPUs Fit In?
The development of AI applications encompasses a series of critical processes, each contributing to what we term “AI workloads.” These processes include:
- Data collection
- Data preprocessing
- Model selection
- Model training
- Model testing
- Model optimization
- Deployment
- Continuous learning
GPUs play a major role in accelerating these workloads, especially in tasks like deep learning, due to their ability to process thousands of threads simultaneously, making them excellent at handling the complex mathematical computations required in AI development. The H200 stands out as an apt choice for such tasks due to its impressive computational power and high memory bandwidth, which significantly reduce the time taken to train and run AI models, thereby boosting efficiency and productivity.
Industry Use Cases for NVIDIA H200
Recent significant advances in high-performance computing and breakthroughs in large language models have expanded research and application development into previously challenging fields like climate science and genome sequencing. The NVIDIA H200, anticipated to be the highest-performance GPU on the market, will play a crucial role in this progress when it’s released in Q2 2024. To explore the advancements of the NVIDIA H200 over its predecessors like the A100 and H100, check out our comparative analysis.
Scientific Simulations
NVIDIA has a history of facilitating rapid scientific simulations in areas such as 3D workflows, and catalyst modeling, particularly through products like the NVIDIA Omniverse. This facilitates the development of 3D workflows and applications based on Universal Scene Description (USD) across various industries, including robotics, gaming, chemicals, and automotive. A notable example is the BMW Group, which used NVIDIA Omniverse to create its first entirely virtual factory.
The introduction of the H200 chip is expected to further accelerate and enhance these scientific simulations within the NVIDIA product range.
Genomic Software
In biomedical engineering, a field poised for rapid growth, NVIDIA Clara is a key player. This genomic software suite accelerates various genome sequencing analyses, supporting the development of a wide range of healthcare applications, including drug discovery, precision medicine, and clinical diagnostics.
With the introduction of the H200 chip, genomic software could yield faster, more affordable results. This could positively affect patient outcomes in areas like cancer treatment.
Financial Analysis
In the past, financial analysis used CPUs as the main calculation engine. With the evolution of AI and use of GPUs, faster and more precise financial analysis calculations are possible. Many cloud providers now offer AI GPU infrastructure, enabling financial firms to adopt a cost-effective, pay-as-you-go approach to their research and application development.
The new H200 chip further accelerates research outcomes and the development of new features, providing a competitive edge in the fast-paced and risk-oriented financial market.
Image and Video Processing
Industries like gaming and streaming require enormous computing power and memory for image and video processing. With this in mind, NVIDIA created the NVIDIA RTX technology which has revolutionized computer graphics with the latest enhancements in AI and simulations.
Wylie Co., a digital imagery studio known for its Oscar-winning work on Dune, is one of the most successful studios to have heavily applied AI successfully in its rendering process, wire removal, and visual effects. After switching from CPUs to GPUs, Wylie achieved a 24-fold performance improvement and reduced energy consumption to one-fifth of its previous level.
With the introduction of the new H200 chip, companies working with image and video processing can raise their performance while simultaneously reducing energy consumption—a win for business revenue and for the environment.
How NVIDIA H200 Drives AI and HPC Workloads
The NVIDIA H200 boasts innovative HBM3e memory technology, delivering 141 GB of memory at a remarkable speed of 4.8 TB per second. This doubles the capacity and delivers a 2.4-fold increase in bandwidth compared to the NVIDIA A100 chip. The H200 GPU chip also offers 1.4 times more bandwidth than the H100 GPU, marking a significant leap in performance and energy efficiency. Detailed specifications can be found on the NVIDIA H200 data sheet.
High-Performance AI Inference
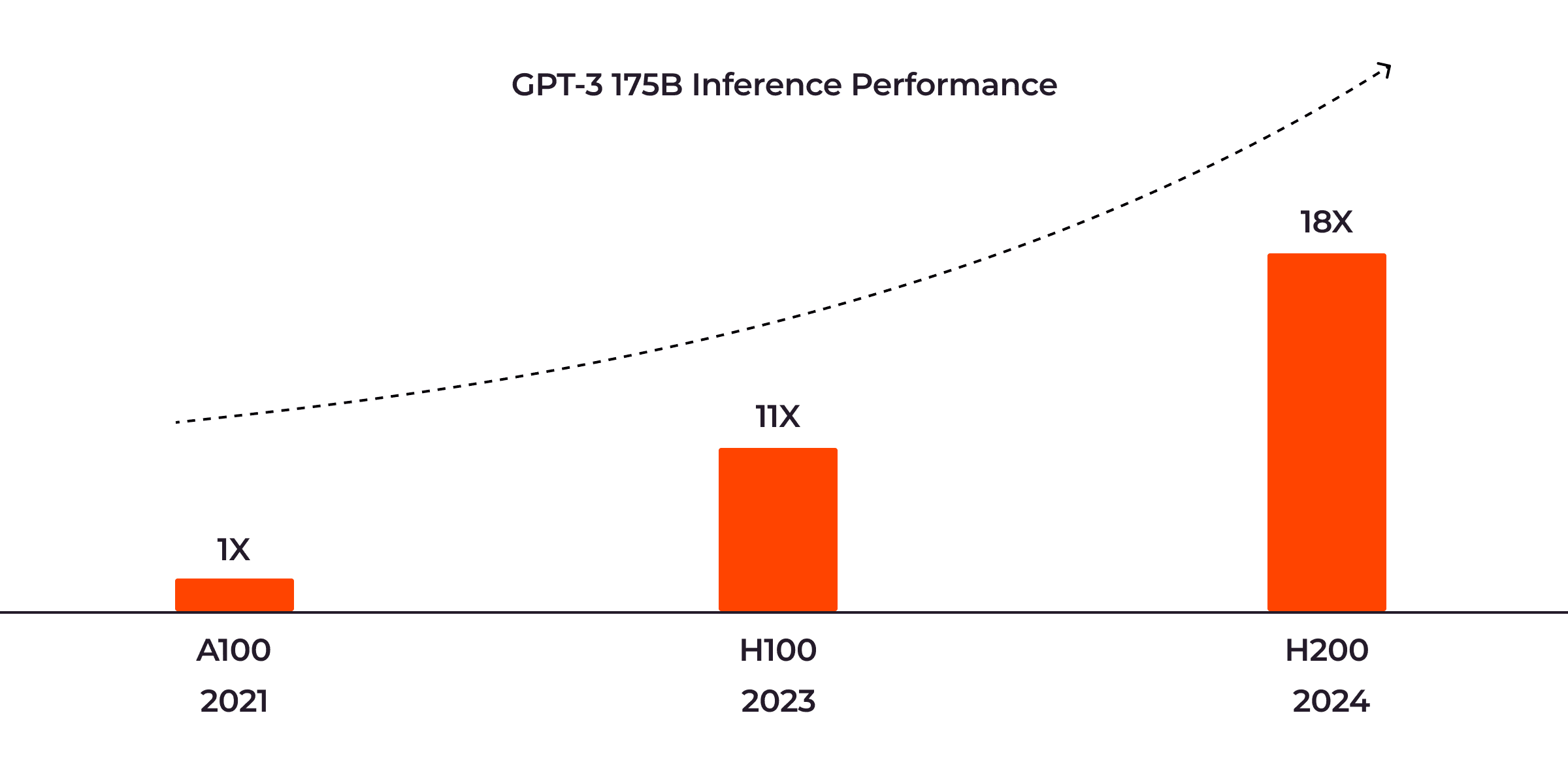
The NVIDIA H200 will drive a new era in high-performance AI inference. For those new to the concept, AI inference is the process where a trained machine learning model applies its knowledge to previously unseen data, generating relevant outputs for specific inputs in a given context. For a comprehensive understanding of how it works, take a look at our detailed AI inference article. This process is integral to the functionality of large language models (LLMs) like OpenAI’s Chat-GPT or Google’s Bard, which have seen dramatic growth over the last few years. Notable large language models include GPT-3 175B, Llama2 70B, and Llama2 13B.
As LLMs advance, the demand for more powerful hardware—such as the H200—to support their inference processes increases. The NVIDIA H200 GPU has demonstrated exceptional performance, offering 18 times the efficiency of the A100 GPU in a recent benchmark for the GPT-3 175B model. The NVIDIA H100 GPU, by comparison, proved to be 11 times more efficient than the A100 GPU.
The NVIDIA GPU chip comes with the latest version of its own built-in LLM, TensorRT-LLM, a toolkit that provides optimized solutions for inferencing large language models like GPT-3 and Llama 2. When running on the Llama-70B model, the new NVIDIA H200 chip achieves a 1.9-fold improvement in throughput optimization over the NVIDIA H100, which uses the previous version of TensorRT-LLM.

In the case of the Llama 2 13B model, the NVIDIA H200 GPU chip achieves up to 1.4 times the throughput optimization compared to its predecessor, the NVIDIA H100 GPU.

Stability AI, one of the world’s leading open-source generative AI companies, significantly enhanced the speed of its text-to-image AI product by integrating NVIDIA TensorRT. This integration, along with the use of the converted ONNX (Open Neural Network Exchange) model on NVIDIA H100 chips led to a notable performance gain. This product can now generate high-definition images in just 1.47 seconds, effectively doubling its previous performance.
Below is a summary of the enhanced image throughput performance achieved by Stable Diffusion XL 1.0. This model, designed to generate and modify images based on text prompts, was created by Stability AI in collaboration with NVIDIA.

By applying the NVIDIA TensorRT library to their chips, Stability AI has significantly enhanced the image throughput of Stable Diffusion XL 1.0, particularly on the NVIDIA H100 chips, achieving up to a 70% improvement.
With the introduction of the more optimized latest TensorRT version on the NVIDIA H200 chip, companies like Stability AI, utilizing open-source, generative libraries such as Stable Diffusion XL 1.0, are poised to experience even greater performance gains.
High-Performance Computing
In AI, handling complex calculations on large datasets requires robust high-performance computing (HPC) capabilities. The NVIDIA H200 chip significantly improves performance, showing a 110-fold improvement over the Dual x86 CPU in the MILC project, a collaborative project studying the theory of strong interactions of subatomic physics.

On average, the NVIDIA H200 chip doubles the performance of the NVIDIA A100 chip for HPC applications, compared to the 1.7-fold improvement shown by the NVIDIA H100.

Energy Efficiency
In recent years, software companies have grown aware of the environmental impact of software development. NVIDIA employs sustainable computing best practices when creating its products.
With the H200 GPU chip, energy efficiency and TCO (total cost of ownership)—an estimation of the expenses associated with purchasing, deploying, using, and retiring a piece of equipment—reach new levels. While the H200 GPU chip offers enormous performance improvements, it only consumes as much power as its predecessor, the H100. Moreover, the H200 GPU is 50% more efficient than the H100 for both energy usage and total cost of ownership.

This significant improvement in energy efficiency for the H200 GPU chip is achieved by optimizing the NVIDIA Hopper architecture, enabling better performance from its GPUs.
Conclusion
The new NVIDIA H200 Tensor Core GPU helps to maximize the AI and HPC workloads so that you can create data-intensive applications more easily and effectively. However, NVIDIA H200 GPU chips are expected to be costly to run, especially for projects that are in MVP phases or applications that only occasionally need to work with large volumes of data and workloads. In such scenarios, it’s prudent to consider a cloud platform that offers a pay-per-use plan, rather than investing in high-performance GPU infrastructure yourself.
With Gcore AI GPU infrastructure, you can choose the NVIDIA GPU solution that best fits your workload. You’re only charged for actual use, optimizing the cost of your AI infrastructure. We offer the latest and most efficient options, including A100s and H100s, with L40S coming soon. Explore the differences in our dedicated article.

Related articles

For many startups, infrastructure decisions are mostly about performance, pricing, and developer experience. For Melious AI, they are also about trust.Melious AI is a German startup building a European AI platform around privacy, transparen

As enterprises move AI from experimentation into production, they face a new infrastructure challenge. AI applications, models, and data are no longer confined to a single cloud or data center. Instead, they are distributed across multiple


2025 quietly became the year DDoS stopped being a "big company" problem. The bandwidth record was broken several times in a single year, each new peak holding for weeks rather than years. In one quarter alone, providers blocked roughly 20 m

Panels about AI sovereignty tend to follow a predictable arc. Someone invokes GDPR. Someone else mentions hyperscalers. A politician says something optimistic. Everyone applauds and goes home.Last week's Gcore AI panel in Luxembourg didn't
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.