
Managing compressed files in Linux can be a manageable task. With tools like 7-zip, users can seamlessly handle and extract various archive formats. The 7z format has gained immense popularity due to its high compression ratios and robust encryption features. However, many Linux distributions do not come with a pre-installed archiver for 7z, primarily due to its proprietary nature and the open-source ethos of the Linux community. Whether you’ve just completed a 7-zip download or are searching for efficient ways to unzip content, our guide offers comprehensive insights to navigate this gap and simplify the extraction process.
What is 7-Zip?
7-Zip is a free and open-source file archiver that allows users to compress files into archives. It uses its 7z format and supports other standard formats, such as ZIP, RAR, and TAR, to name a few. The software is known for its high compression ratio. It can be used for personal and commercial purposes without licensing costs. Unlike many other software solutions, users don’t need to purchase a license to use 7-Zip, making it cost-effective. When pitted against other archivers, 7-Zip is an excellent choice due to its performance, reliability, and freedom from licensing restrictions.
7-Zip Unpacking Process
Here’s a basic overview of the unpacking process:
#1 Installing p7zip
Before you can extract 7z files, you need to have the p7zip package installed. This package provides tools to work with 7z files in Linux.
On Debian/Ubuntu and derivatives:
sudo apt updatesudo apt install p7zip-fullOn Fedora:
sudo dnf install p7zipOn CentOS/RHEL:
sudo yum install p7zipOn Arch Linux and derivatives:
sudo pacman -S p7zip#2 Navigate to the Directory
Using the terminal, navigate to the directory where your 7z file is located. For example:
cd /path/to/directory/#3 Extract the 7z File
To extract a 7z file, use the following command:
7za x yourfile.7zFor this command:
- ‘x’ stands for extract.
- ‘yourfile.7z’ should be replaced with the name of your 7z file.
#4 Verify the Contents
After extraction, you can list the contents of the directory to ensure the files were extracted correctly:
Please note:
- If you encounter any password-protected 7z files, you’ll be prompted to enter the password during the extraction process.
- p7zip also provides a 7z command, but the 7za variant is a standalone executable that supports fewer archive formats but is compatible with the 7z format.
#5 Common 7-Zip Commands
The 7z command in Linux, part of the p7zip package, comes with a variety of arguments (or commands) that dictate how it should operate. Here are some of the most common arguments and their basic descriptions:
| Commands | Descriptions |
| a | Add files to archive.. |
| d | Delete files from archive. |
| e | Extract files from archive (without using directory names) |
| l | List contents of archive |
| t | Test integrity of archive |
| u | Update files to archive.. |
| x | Extract files with full paths |
For example, if you have a file named “sample.7z” and you want to extract it, the command would be:
7z x sample.7zThe sample output should be:
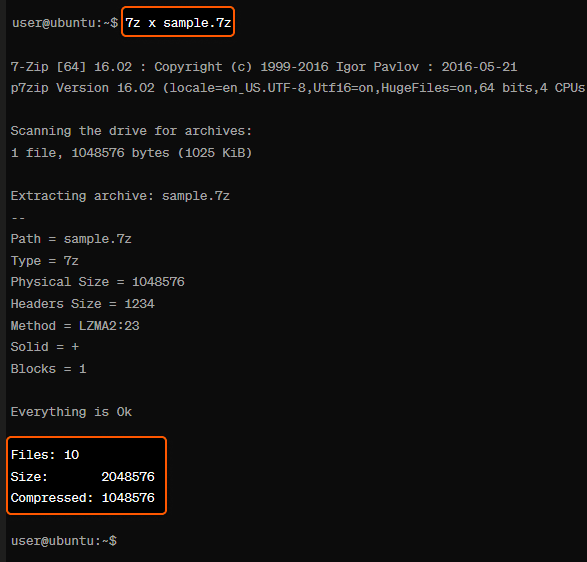
In terms of the 7z commands, the one that we mentioned here are just some basic commands and options. The 7z tool has a comprehensive set of features and capabilities, so it’s always a good idea to refer to the manual page (man 7z) or the help command (7z –help) for a full list and detailed explanations.
Conclusion
Looking to deploy Linux in the cloud? With Gcore Cloud, you can choose from Basic VM, Virtual Instances, or VPS/VDS suitable for Linux:
- Gcore Basic VM offers shared virtual machines from €3.2 per month
- Virtual Instances are virtual machines with a variety of configurations and an application marketplace
- Virtual Dedicated Servers provide outstanding speed of 200+ Mbps in 20+ global locations
Related articles





Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial

Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.