
When we talk about “LibreOffice on Ubuntu,” we refer to the installation and usage of this office suite on the Ubuntu operating system. Ubuntu, being one of the most popular Linux distributions, often includes LibreOffice as part of its default software set. However, users can also download and install newer or specific versions if they wish. This guide showcases the process of installing LibreOffice on Ubuntu, empowering you with a top-tier office solution without the hefty price tag.
What is LibreOffice?
LibreOffice is a free and open-source office suite, widely recognized as a powerful alternative to proprietary office suites like Microsoft Office. The suite includes applications making it the most powerful free and open-source office suite on the market:
- Writer. A word processing tool comparable to Microsoft Word.
- Calc. A spreadsheet application similar to Microsoft Excel.
- Impress. A presentation software analogous to Microsoft PowerPoint.
- Draw. A vector graphics editor and diagramming tool.
- Base. A database management program, akin to Microsoft Access.
- Math. An application to create and edit mathematical formulas.
LibreOffice’s open-source nature, combined with its robust feature set, makes it an excellent choice for Ubuntu users looking for a comprehensive office solution without the licensing costs associated with commercial products. Let’s take a look at the next section on how to install it.
Installing LibreOffice on Ubuntu
Here’s a step-by-step guide on how to install LibreOffice on Ubuntu:
1. Update the Package Index. Always start by ensuring your system’s package list and software are up to date.
sudo apt update && sudo apt upgrade -y2. Install LibreOffice. Now, you can install LibreOffice using the apt package manager.
sudo apt install libreofficeIf it doesn’t work, you can also try these following commands:
sudo snap install libreofficesudo apt install libreoffice-commonExample:
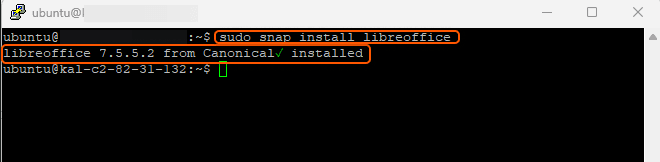
3. Verify Installation. To confirm that LibreOffice was installed correctly, you can check its version.
libreoffice --versionExample:
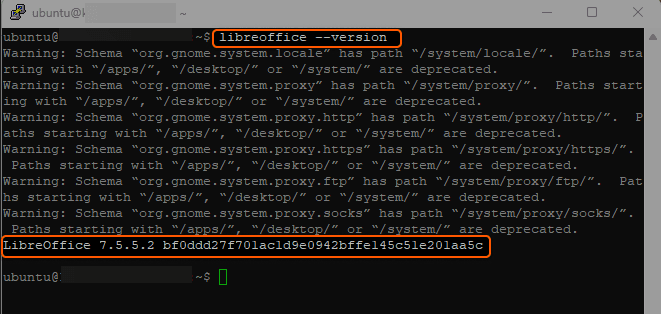
4. Launch LibreOffice. You can start LibreOffice either from the terminal or through the Ubuntu application menu.
libreofficeExpected Output: The LibreOffice start center will open, presenting various options like Writer, Calc, and Impress.
And that’s it! You have successfully installed LibreOffice on Ubuntu. This powerful office suite is now at your disposal, ready to cater to all your document editing, spreadsheet calculations, and presentation needs.
Conclusion
Want to run Ubuntu in a virtual environment? With Gcore Cloud, you can choose from Basic VM, Virtual Instances, or VPS/VDS suitable for Ubuntu:
- Gcore Basic VM offers shared virtual machines from €3.2 per month
- Virtual Instances are virtual machines with a variety of configurations and an application marketplace
- Virtual Dedicated Servers provide outstanding speed of 200+ Mbps in 20+ global locations
Related articles


Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.