How to launch real-time communications for iOS/Android
- March 13, 2023
- 9 min read

The phrase real-time communications (RTC) refers to any live telecommunications method in which all users can interact in a live capacity, with negligible latency. In other words, a phone or video call. And it can be a valuable feature for an application to provide its users with, even if it’s not the app’s core purpose.
For example, Instagram has interactive broadcasts with guests in Live Rooms, and direct video calling features, despite being a platform for mostly sharing pre-recorded images and video. This way, Instagram keeps users in its app. If interlocutors want to call, they don’t need to navigate to another RTC app—they just need to click a ring button in the Instagram interface.
If you’re considering adding an RTC feature to your application, stick around. We’ll show you step by step how to launch a real-time communication SDK in 15 minutes, for both iOS and Android.
The real-time communication SDK would look like this:
A brief comparison of RTC platforms
Before we begin, let’s do a brief RTC platform comparison. You may already be aware of some of the biggest providers, like Agora, Twilio, and Gcore, but let’s take a closer look at what each of them offer to help narrow which is the best option for RTC.
| Gcore | Agora | Twilio | Zoom | Jitsi | |
| Ease of integration | Prebuilt SDK with low coding effort | Custom SDK requires high coding effort | SDK requires manual integration and configuration with high coding effort | SDK has two predefined roles; customization is not possible | Devs must manually configure permissions for peers in a call |
| Scalability | Max of 100 speakers and 2,000 attendees | Max of 128 hosts and 1,000,000 participants, including hosts | Max of 50 hosts and 50 participants, including hosts | Max of 1,000 participants including the hosts | Max of 100 hosts and 100 participants, including hosts. |
| Pricing | Free up to 50K minutes | Base price $3.99; complicated pricing plans and policies | Has a free tier and paid tier charged per participant minute starting at $0.0015 | Free up to 10,000 minutes | Free, open-source |
Our platform works well for the purposes of this tutorial as we’re focusing on video calls with a simple implementation. Let’s launch the Gcore’s real-time communication SDK in 15 minutes.
Implementing Real-time Video Call for iOS
This article covers implementation for GCoreVideoCallsSDK version 2.5.1.
Before we begin with the iOS part of this tutorial, there are a few requirements you’ll need to make sure you’re up to date on:
- iOS 12.1 and above on your target device
- The latest Xcode version
- CocoaPods
You can check out the final iOS demo project on GitHub to further your understanding of this tutorial.
The demo features a production-ready GCore videocall SDK implementation, written in a way that’s easy to read and understand. This demo project should help you gain a deeper understanding of all features of the SDK.
Installing the Gcore SDK
First, you need to install dependencies. Create a podfile and add the following:
pod "mediasoup_ios_client", '1.5.3'This allows you to use mediasoup which is a framework that will allow you to make video calls on iOS.
Next, launch your terminal and change the directory to your project folder. Enter:
pod installThis installs the library media_ios_client into your project.
Open Xcode and drag the GCoreVideoCallsSDK.xcframework to the root of the project folder.
Make sure Copy items if needed is checked, and then click Finish.
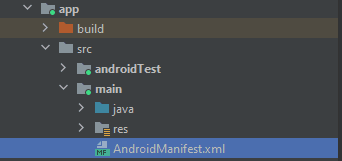
Now, in the project target, navigate to General > Framework, Libraries, and Embedded Content. There, set the Embed value to Embed & Sign for GCoreVideoCallsSDK.xcframework.

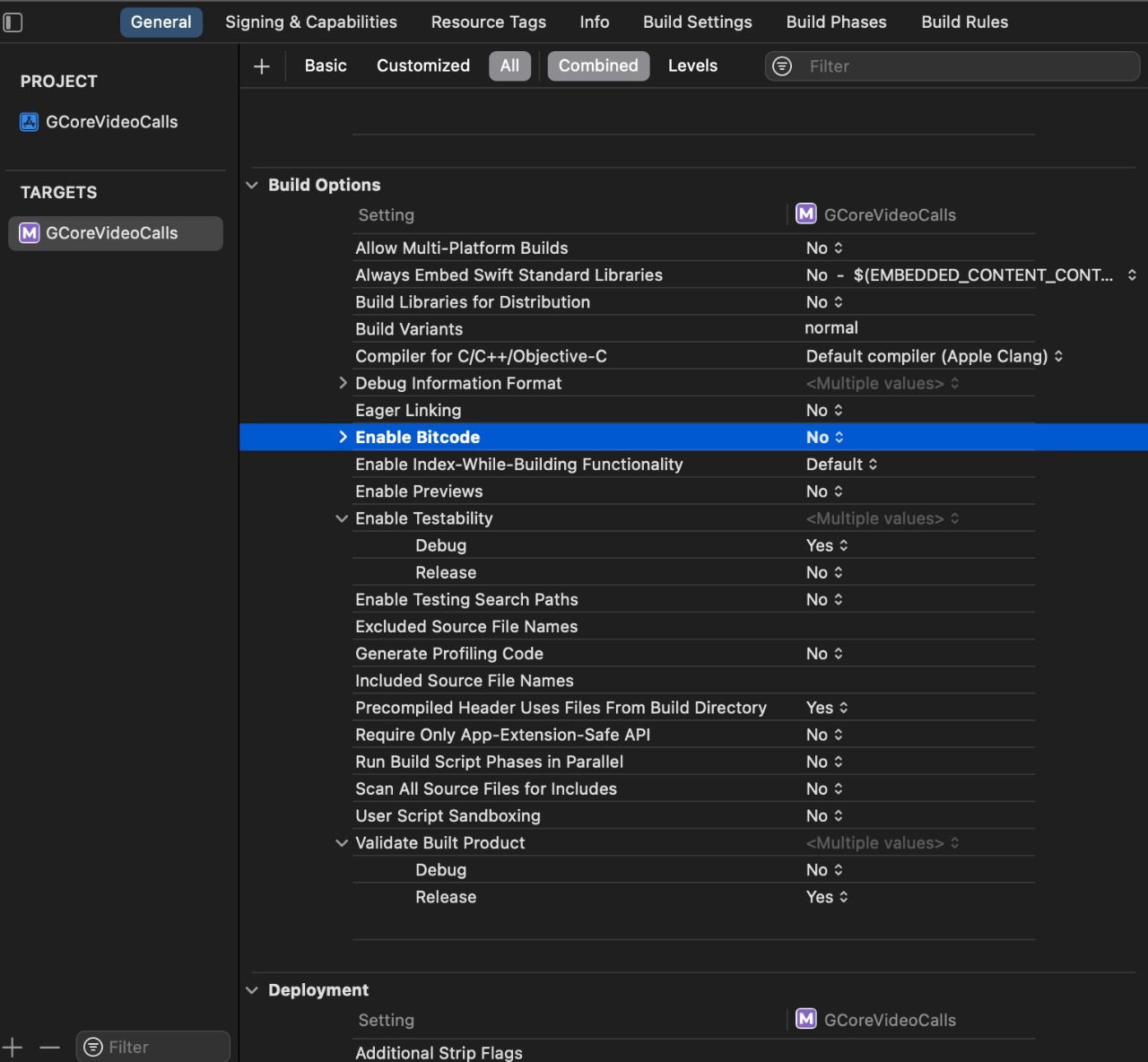
In the Build Settings of the target, set ENABLE_BIT CODE = No and Validate Workspace = Yes.
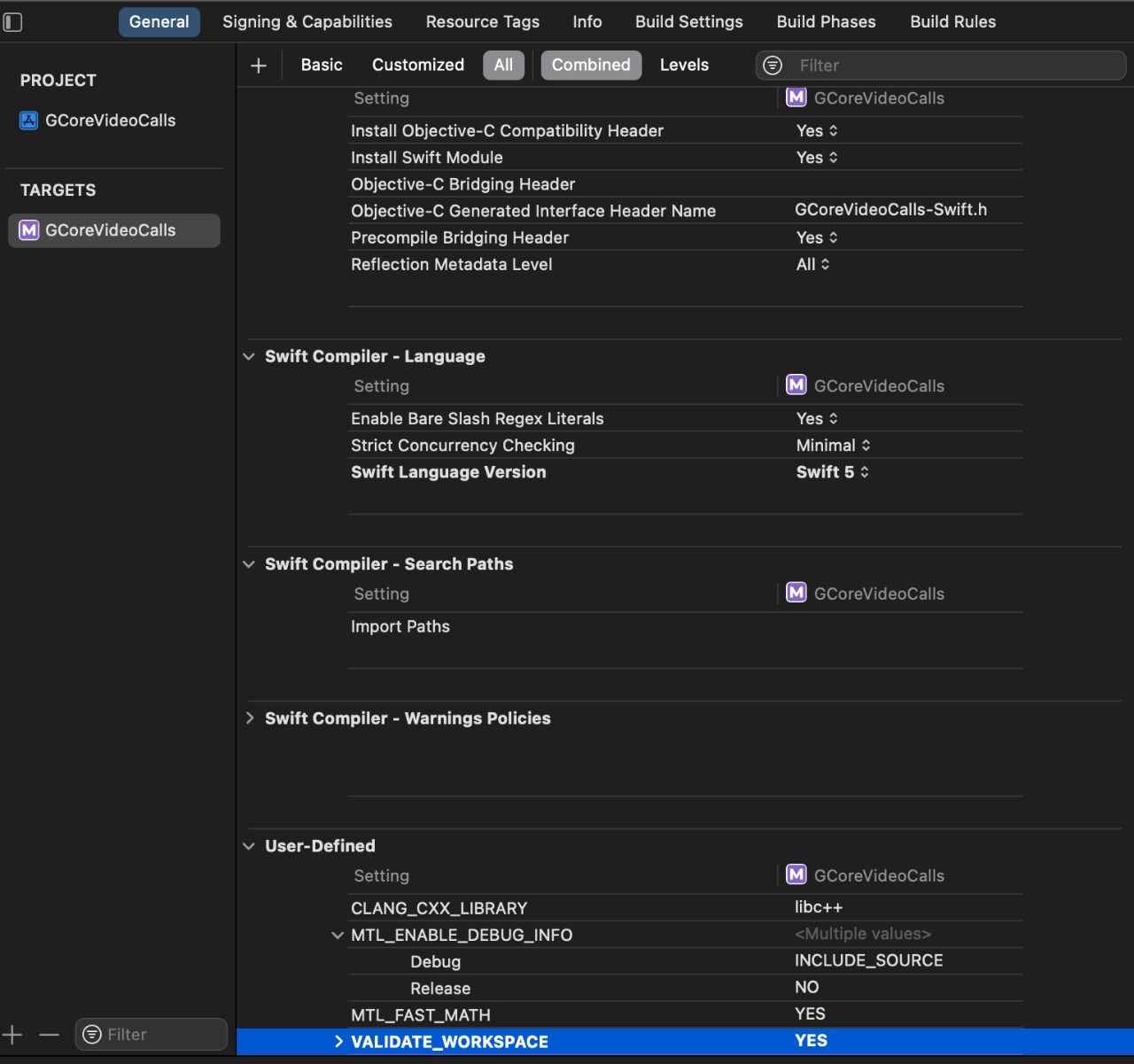
In Info.plist, add a description for the parameters NSCameraUsageDescription and NSMicrophoneUsageDescription.
Create and join a room
Before you can create or join a room, there are a few steps you have to complete.
First, import dependencies:
import GCoreVideoCallsSDK import WebRTCActivate logger; this code block facilitates communication between the client and the server:
GCoreRoomLogger.activateLogger()Set the parameters for connecting to the server. The first code block here sets the front camera as the default camera to be used in the video call:
let options = RoomOptions(cameraPosition: .front)let parameters = MeetRoomParametrs ( roomId: "SampleVideoCall0123", displayName: "John Smith", peerId: "", clientHostName: "meet.gcore.com" )| Parameter | Type | Description |
| roomId | String | Room ID to connect to; clients with matching IDs are grouped together. Example: roomId: "SampleVideoCall0123". |
| displayName | String | Sets the display name of the participant. Example: displayName: "Jane Doe". |
| peerId | String (optional) | ID of a participant from your internal system; please specify userID if you have your own. Can be left blank as value will auto-generate. Example: peerId: "user0000000001". |
| clientHostName | String (optional) | Client passes the domain name that it uses to operate the web version of meet. Value: domain only without specifying the protocol. Example: clientHostName: "meet.gcore.com". |
Create an instance of the client and connect:
var client: GCoreRoomClient? client = GCoreRoomClient(roomOptions: options, requestParameters: parameters, roomListener: self) try? client?.open()This creates a room, using the front camera and setting the roomId as SampleVideoCall0123 and the displayName as John Smith, as defined before. John’s device is set as the listener to events happening in the room.
I’ll talk more about events later on.
Now, activate the audio session, which allows the client to listen and speak:
client?.audioSessionActivate()Listen to room events
Any real-time communication SDK needs to be able to listen to room events to simulate interaction on a live capacity, such as when someone joins a group discussion, raises their hand to ask a question to introduce themselves and more.
Examples of room events:
- A peer joining or leaving
- The moderator admitting or expelling peers
- The moderator muting everyone
- Peers interacting with their microphones and cameras
- Changes in user information, like a new moderator has been assigned
Fortunately, the Gcore SDK comes with a RoomListener delegate class, which you’ll use to listen in on events.
For error events:
func roomClientHandle(error: RoomError) ///handles errors in the roomFor connection events:
func roomClientStartToConnectWithServices()///Initiates connecting the SDKfunc roomClientSuccessfullyConnectWithServices()///Notify that a successful connection has occurredfunc roomClientDidConnected()///Notify client successfully connects to server/roomfunc roomClientReconnecting()///Notify client is connecting to the room, eg, after network failurefunc roomClientReconnectingFailed()///Notify of a reconnection failurefunc roomClientSocketDidDisconnected(roomClient: GCoreRoomClient)///Notify that connection to the server has been lostFor guests joining or leaving:
func roomClient(roomClient: GCoreRoomClient, handlePeer: PeerObject)///Notify room members that peer joined the roomfunc roomClient(roomClient: GCoreRoomClient, peerClosed: String)//Notify room members that peer left the roomNote that the
peerClosedparameter contains the ID of the peer who left the room.
For audio and video events:
func roomClient(roomClient: GCoreRoomClient, produceLocalVideoTrack videoTrack: RTCVideoTrack)///Local client notifies peers that their video is onfunc roomClient(roomClient: GCoreRoomClient, produceLocalAudioTrack audioTrack: RTCAudioTrack)///Local client notifies peers that their audio is onfunc roomClient(roomClient: GCoreRoomClient, didCloseLocalVideoTrack videoTrack: RTCVideoTrack?)//Local client notifies peers that their video is offfunc roomClient(roomClient: GCoreRoomClient, didCloseLocalAudioTrack audioTrack: RTCAudioTrack?)///Local client notifies peers that their audio is offfunc roomClient(roomClient: GCoreRoomClient, handledRemoteVideo videoObject: VideoObject)///Peers notify local clients about the state of their video stream(on/off).func roomClient(roomClient: GCoreRoomClient, produceRemoteAudio audioObject: AudioObject)Let me break some of that down:
roomClientis an instance of the GCoreRoomClient class, which contains information about the room and its participants.videoTrackcontains information about the video stream.audioObjectcontains information about the audio stream.
For changes in user info:
func roomClient( roomClient: GCoreRoomClient, updateMeInfo: UpdateMeInfoObject)This function is called when the user’s information changes. It takes in a parameter of type UpdateMeInfoObject, which contains all of the new information about the user. That includes:
peerId: The id of the peer who’s info has changed.displayName: The display name for this peer.isModerator: Whether or not this peer is a moderator.isAudioOnly: Whether or not this peer has audio only enabled.isVideoOnly: Whether or not this peer has video only enabled.isScreenShareOnly: Whether or not this peer has screen share only enabled.
For session info events:
func roomClient( roomClient: GCoreRoomClient, captureSession: AVCaptureSession, captureDevice: AVCaptureDevice)This is a function that allows you to set the camera and microphone settings. It takes three parameters:
roomClient: A reference to an object that implements theGCoreRoomClientprotocol. This parameter is required and cannot be nil.captureSession: A reference to an object of typeAVCaptureSession, which allows you to configure the camera settings. This parameter is required and cannot be nil.captureDevice: A reference to an object of typeAVCaptureDevice, which allows you to configure the microphone settings. Again, this parameter is required and cannot be nil.
Listen to moderator events
Moderator events are actions triggered by the admin of the room, such as:
- Creating and closing the room
- Muting and unmuting participants
- Admitting or expelling participants
For a moderator closing someone else’s video or audio:
func roomClient(roomClient: GCoreRoomClient, didCloseRemoteVideoByModerator byModerator: Bool, videoObject: VideoObject)///Moderator closed peer videofunc roomClient(roomClient: GCoreRoomClient, didCloseRemoteAudioByModerator byModerator: Bool, audioObject: AudioObject)///Moderator closed peer audioThis function takes three parameters:
roomClient: The room client contains all the information about the current room.byModerator: A Boolean value that indicates whether it was closed by a moderator or not.videoObject: An object containing all the information about the video stream.audioObject: An object containing all the information about the audio track.
The following function notifies a waiting peer that the moderator has not yet accepted the user’s request to join the room. The peer receives a message that says You are waiting for permission from the moderator.
func roomClientWaitingForModeratorJoinAccept()This function notifies a waiting peer that the moderator has rejected their request to enter the room. The peer receives a message that says You have been rejected by the moderator.
func roomClientModeratorRejectedJoinRequest()This function notifies a moderator of a request to join a room:
func roomClient( roomClient: GCoreRoomClient, moderatorIsAskedToJoin: ModeratorIsAskedToJoin)This function notifies a peer that a moderator has removed them. The function itself doesn’t do anything, but you can use it to add custom functionality, like displaying an alert message to the user that they’ve been removed from the room.
func roomClientRemovedByModerator()Toggle a user’s mic and cam
Use the following code to set the user video:
func roomClientDidConnected() { DispatchQueue.main.asyncAfter(deadline: .now() + 1) { self.client?.toggleVideo(isOn: true) self.client?.toggleAudio(isOn: true) } }This is called when the client connects to a room. After one second, the video and audio turn on. Set the Boolean value in (isOn: true) to false to turn off the corresponding feature.
Display remote user video
If the connection is successful, a method is called that returns all the participants in the room, saves them, and draws elements to display the participants:
func joinWithPeersInRoom(_ peers: [PeerObject]) { peers.forEach { peer in let remoteItem = GCLRemoteItem(peerObject: peer) remoteItems.insert(remoteItem) mainScrollView.addSubview(remoteItem.view) }}When a new participant enters a room, this adds them to the array of connected participants and to the ScrollView, respectively:
func handledPeer(_ peer: PeerObject) { let remoteItem = GCLRemoteItem(peerObject: peer) remoteItems.insert(remoteItem) mainScrollView.addSubview(remoteItem.view)}When a participant disconnects, this removes them from the array:
func peerClosed(_ peer: String) { if let remoteItem = remoteItems.first(where: { $0.peerId == peer }) { remoteItem.view.removeFromSuperview() remoteItems.remove(remoteItem) }}Implementing real-time video call for Android
Before we begin with the Android part of this tutorial, there are a few requirements you’ll need to make sure you’re up to date on:
- The latest version of Android Studio
- Android 7.0 Nougat (API level 24) on your target device
You can check out the Android demo project on GitHub if you want to follow along with it for this tutorial.
As with the iOS version of the tutorial, this demo features a production-ready GCore videocall SDK implementation, written in a way that’s easy to read and understand. Through this demo project, you’ll get a better understanding of the features of the SDK. The SDK’s simplicity makes it perfect for rapid prototyping and experimentation.
Installing the Gcore SDK
Copy GCoreVideoCallsSDK and mediasoup-android-client to the root of your project folder.
Add them both to your app/build.gradle file in the dependencies section:
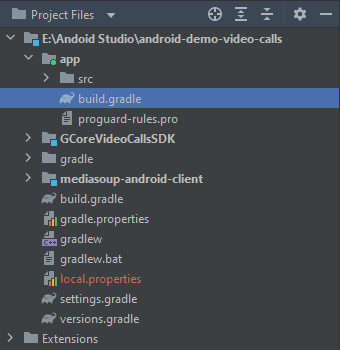
implementation project(':GCoreVideoCallsSDK')implementation project(':mediasoup-android-client')Include them in settings.gradle as follows:
include ':mediasoup-android-client'include ':GCoreVideoCallsSDK'Import the dependencies from the SDK archive, but go ahead and add the following in the dependencies section of app/build.gradle as well:
implementation 'androidx.core:core-ktx:1.7.0'implementation 'androidx.appcompat:appcompat:1.4.1'implementation 'com.google.android.material:material:1.5.0'implementation 'androidx.constraintlayout:constraintlayout:2.1.3'testImplementation 'junit:junit:4.13.2'androidTestImplementation 'androidx.test.ext:junit:1.1.3'androidTestImplementation 'androidx.test.espresso:espresso-core:3.4.0'implementation("androidx.fragment:fragment-ktx:1.4.1")implementation("androidx.navigation:navigation-fragment-ktx:2.4.2")implementation("androidx.navigation:navigation-ui-ktx:2.4.2")implementation "androidx.lifecycle:lifecycle-extensions:$LIFECYCLE_VERSION"implementation "com.google.dagger:dagger:$DAGGER_VERSION"kapt "com.google.dagger:dagger-compiler:$DAGGER_VERSION"implementation "com.jakewharton.timber:timber:$TIMBER_VERSION"implementation("io.reactivex.rxjava2:rxjava:$RX_JAVA_VERSION")implementation("io.reactivex.rxjava2:rxandroid:$RX_VERSION")implementation "org.protoojs.droid:protoo-client:$PROTO_VERSION"implementation("com.squareup.okhttp3:okhttp:$OKHTTP_VERSION")implementation("com.squareup.okhttp3:logging-interceptor:$OKHTTP_VERSION")def camerax_version = "1.1.0-rc01"implementation("androidx.camera:camera-core:${camerax_version}")implementation("androidx.camera:camera-camera2:${camerax_version}")implementation("androidx.camera:camera-lifecycle:${camerax_version}")implementation("androidx.camera:camera-view:${camerax_version}")In the plugins section in app/build.gradle, include:
id 'kotlin-kapt'Create a new file in the root directory of the project and name it versions.gradle. Go ahead and add the following:
ext { KOTLIN_VERSION = "1.5.30" CORE_KTX_VERSION = "1.6.0" ANDROID_GRADLE_PLUGIN_VERSION = '4.0.0' PROTO_VERSION = "4.0.3" DRIOD_VERSION = "3.0.8-beta-3" LIFECYCLE_VERSION = "2.2.0" COROUTINE_VERSION = "1.5.0" DAGGER_VERSION = '2.37' RX_JAVA_VERSION = "2.2.17" RX_VERSION = "2.1.1" TIMBER_VERSION = "4.7.1" LOGGING_INTERCEPTOR_VERSION = '4.9.0' OKHTTP_VERSION = '4.9.0'}In the build.gradle file, add:
buildscript { apply from: 'versions.gradle'}In the settings.gradle file, add the following pluginManagement{} and dependencyResolutionManagement{}:
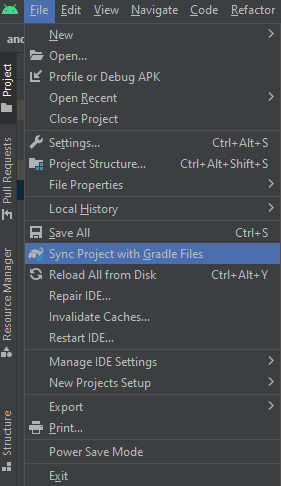
maven {url ' https://jitpack.io '}jcenter()It should look something like this:
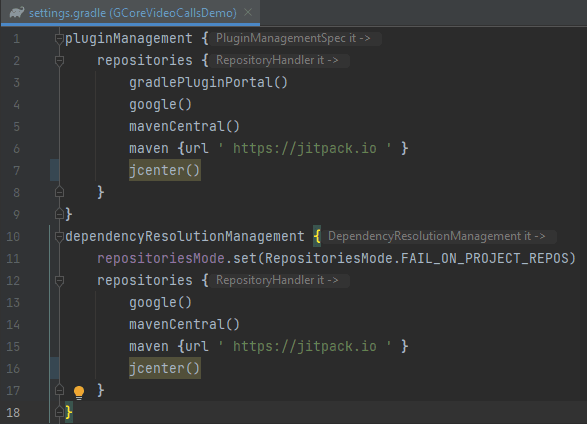
Now, resync the project!
Set user permissions
The Gcore SDK requires internet connection and access to microphone and camera. Requesting those permissions takes just a couple steps.
First, to declare the permissions, navigate to AndroidManifest.xml in app/src/main and add the following:
<uses-permission android:name="android.permission.INTERNET"/><uses-permission android:name="android.permission.CALL_PHONE"/><uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/>And finally, request the permissions:
if (!allPermissionGranted()) { requestPermissions.launch(REQUIRED_PERMISSIONS) }companion object { private val REQUIRED_PERMISSIONS = arrayOF( Manifest.permission.CAMERA, Manifest.permision.RECORD_AUDIO)}Create and join a room
Creating or joining a room requires a few steps. First, initialize the Gcore SDK:
GCoreMeet.instance.init( applicationContext: Application, logger: null, enableLogs: false)Then define the parameters for connecting to the server:
GCoreMeet.instance.clientHostName = "meet.gcore.com"GCoreMeet.instance.roomManager.displayName = "Jane Doe"GCoreMeet.instance.setRoomId("SampleVideoCall1234")GCoreMeet.instance.roomManager.peerId = ""GCoreMeet.instance.roomManager.isModer = true| Method | Type | Description |
| setRoomId | String | Room ID to connect to. Example: roomId: "SampleVideoCall1234". |
| Parameter | Type | Description |
| displayName | String | Set display name of participant. Example: displayName: "Jane Doe". |
| peerId | String (optional) | ID of a participant from your internal system. Please specify userID, if you have your own or leave it blank to autogenerate. Example: peerId:"user0000000001". |
| clientHostName | String (optional) | Client passes the domain name used to operate the web version of the meet. Value: domain only, no protocol specified. Example: clientHostName: "meet.gcore.com". |
| isModer | Boolean | If true, then the user will be a moderator, with access to additional functionality. |
Next, set audio and video:
GCoreMeet.instance.roomManager.options.startWithCam = trueGCoreMeet.instance.roomManager.options.startWithMic = trueAnd establish a connection to the server:
GCoreMeet.instance.startConnection(getApplication())Finally, join the room:
if GCoreMeet.instance.roomManager.isClosed()) { GCoreMeet.instance.roomManager.join()}At the end of a session, go ahead and close the room for all participants:
GCoreMeet.instance.roomManager.destroyRoom()Display room members
To properly display the members of a room, this function observes the number of peers present in a room and changes the layout manager span count accordingly.
private val _layoutManagerSpanCount = MutableLiveData<Int>()val layoutManagerSpanCount: LiveData<Int> = _layoutManagerSpanCountprivate fun connect() { GCoreMeet.instance.getPeers().observeForever { peers: Peers? -> val peersCount = peers?.allPeers?.size ?: 0 if (peersCount > 1) { _layoutManagerSpanCount.value = 2 } else { _layoutManagerSpanCount.value = 1 } } }Enable and disable user mic and cam
To enable and disable a microphone, respectively:
GCoreMeet.instance.roomManager.enableMic()GCoreMeet.instance.roomManager.disableMic()To enable and disable a camera, respectively:
GCoreMeet.instance.roomManager.enableCam() GCoreMeet.instance.roomManager.disableCam()Subscribe to room changes
The following functions provide notifications regarding changes to the room.
The state of the connection:
GCoreMeet.instance.roomManager.roomProvider.connectedWhat peers or members are in the room:
GCoreMeet.instance.roomManager.roomProvider.peers GCoreMeet.instance.getPeers()What speakers are active:
GCoreMeet.instance.roomManager.roomProvider.roomInfo.observeForever{ roomInfo-> roomInfo.activeSpeakerIds roomInfo.connectionState}In the previous function, room.ConnectionState can have the following states:
DISCONNECTED: No data is received from the server and no requests are sent to it.CONNECTING: The connection with the server is established, but there is no information about other participants in the room yet.CONNECTED: Connected to a room and receiving data from other participants in it.RECONNECTING: The connection with the server was interrupted for some reason (for example, due to a network failure).
To be informed of changes in local user state:
roomManager.roomProvider.me.observeForever { localState: LocalState ->}The following are possible returns for user state:
localState.isAudioMuted: Checks whether a user’s microphone is muted or not.localState.isVideoMuted: Checks whether a user’s camera is on or not.localState.isScreenSharingEnabled: Checks whether demonstration is enabled or not.
For changes in entry request state:
roomManager.roomProvider.waitingState.observeForever{state: WaitingState -> }This function checks for changes to a join request with the following possible states:
NOTHINGIN_WAITING: Waiting for moderator response.ACCEPTED: A moderator allowed a user entry.REJECTED: A moderator denied a user entry.
For when a moderator kicks out a peer:
roomManager.roomProvider.closedByModerator.observeForever{}For changes in a room’s permissions:
roomManager.roomProvider.micAllowed.observeForever{allowet: Boolean -> } roomManager.roomProvider.camAllowed.observeForever{allowet: Boolean -> } roomManager.roomProvider.acceptedAudioPermission.observeForever{}///Audio use is permitted in the room roomManager.roomProvider.acceptedVideoPermission.observeForever{}///Video use is permitted in the roomFor a moderator’s response to peer:
roomManager.roomProvider.acceptedAudioPermissionFromModerator.observeForever{}///Mod allows use of audio in the roomroomManager.roomProvider.acceptedVideoPermissionFromModerator.observeForever{}///Mod allows use of video in the roomFor changes in blocked user states, for example, if a user has a microphone or camera blocked, but wants to turn them on:
roomManager.askUserConfirmMic.observeForever{}roomManager.askUserConfirmCam.observeForever{}For peer requests to moderator:
roomManager.roomProvider.requestToModerator.observeForever { data: RequestPeerData ->}In the previous function, RequestPeerData contains userName, peerId, requestType. requestType can be AUDIO, VIDEO, and SHARE requests for microphone, camera, and demonstration, respectively.
Conclusion
With Gcore’s SDK, you’ve created and joined RTC rooms for both iOS and Android platforms. You’ve walked through enabling and disabling the microphone and camera, setting the client as moderator, and listening to changes in a meeting. You’re now equipped to implement video call features in your application, with an SDK that’s easy to integrate, easy to scale with, and affordable.
If you want to experiment further with Gcore’s SDK, remember that you can check out the iOS demo project and the Android demo project on Gcore’s GitHub.
Written by Michael Simiyu

Related articles


At Gcore, delivering exceptional streaming experiences to users across our global network is at the heart of what we do. We're excited to share how we're taking our CDN performance monitoring to new heights through our partnership with AVEQ

As streaming demand surges worldwide, providers face mounting pressure to deliver high-quality video without buffering, lag, or quality dips, no matter where the viewer is or what device they're using. That pressure is only growing as audie

Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.