
Egal, ob Sie zu Hause oder im Büro sind, Ihr Router spielt eine wichtige Rolle bei der Bereitstellung der für Arbeit, Unterhaltung und Kommunikation erforderlichen Internetverbindung. Wenn Probleme auftreten oder es Zeit für ein Upgrade ist, kann es entmutigend sein, zu wissen, wo man anfangen soll. In diesem Artikel helfen wir Ihnen, ein umfassendes Verständnis Ihres Routers zu erlangen. Sie erfahren, wie Sie frustrierende Netzwerkprobleme, langsame Internetgeschwindigkeiten und Sicherheitslücken vermeiden und beheben können, und wie Sie den richtigen Router für Ihre Bedürfnisse auswählen.
Was ist ein Router?
Ein Router ist ein zentraler Knotenpunkt, der die nahtlose gemeinsame Nutzung von Ressourcen, wie Servern, Druckern, Netzwerken und Internetverbindungen, durch mehrere Geräte ermöglicht. Router spielen eine wichtige Rolle bei der effizienten Verwaltung der Datenübertragung zwischen Geräten innerhalb eines lokalen Netzwerks und zwischen verschiedenen Netzwerken.
Denken Sie an den Router, den Sie vielleicht in Ihrer Wohnung oder Ihrem Haus haben. Er verbindet Ihre Geräte, wie z. B. Ihren Laptop oder Ihr Smartphone, mit dem Internet und ermöglicht Ihnen so das Surfen auf Websites, das Streamen von Videos und das Herunterladen von Dateien. Ohne könnten Ihre Geräte nicht mit dem Internet kommunizieren.
In einem Büroumfeld wird die Rolle des Routers noch entscheidender. Ein Router ermöglicht nicht nur den Internetzugang für mehrere Geräte, sondern kann auch die gemeinsame Nutzung von Ressourcen wie Servern und Druckern erleichtern. Stellen Sie sich vor, Sie sitzen an Ihrem Schreibtisch im Büro und haben gerade einen Bericht fertiggestellt, den Sie ausdrucken müssen. Wenn Sie auf Ihrem Computer auf „Drucken“ klicken, stellt der Router sicher, dass Ihre Datei den richtigen Weg von Ihrem Computer zum Drucker im Netzwerk findet und wie von Ihnen gewünscht ausgedruckt wird.
Wozu dient ein Router?
Ein Router ermöglicht die Datenübertragung zwischen Geräten oder kann Daten an einen anderen Router weiterleiten. Router verbinden Geräte in einem lokalen Netzwerk und ermöglichen ihnen die Kommunikation und die Übertragung von Daten. Sie ermöglichen Geräten, über einen einzigen Verbindungspunkt auf das Internet oder externe Netzwerke zuzugreifen. Router ermöglichen auch die Verbindung und den Austausch von Daten zwischen Netzwerken an verschiedenen geografischen Standorten. Ein Router kann zum Beispiel ein regionales oder weit entferntes Büro mit der Hauptgeschäftsstelle verbinden.
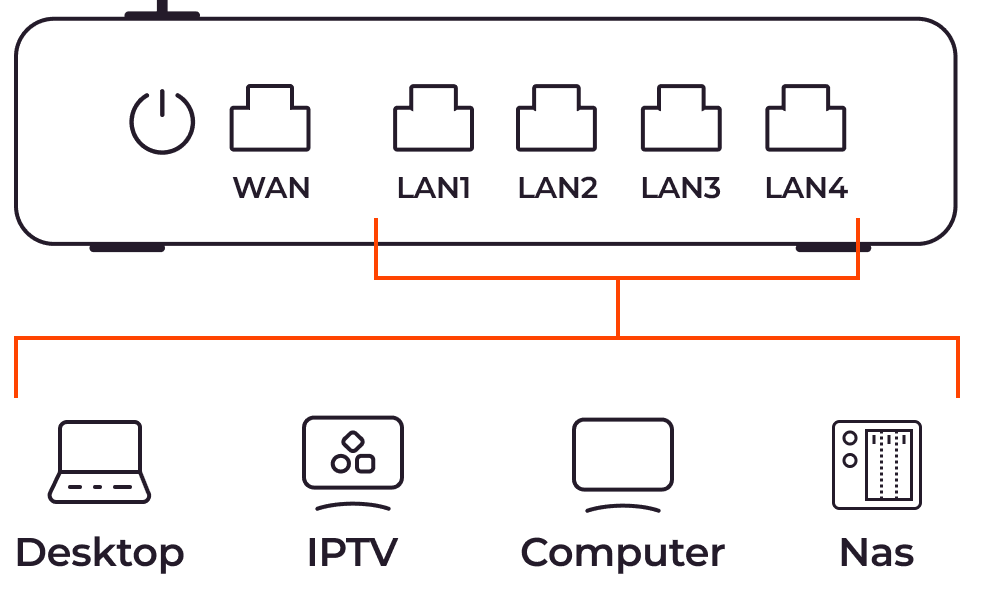
Neben der Datenübertragung zwischen Netzwerken können Router auch andere Funktionen erfüllen, die für die Netzwerkverwaltung, die Sicherheit und die gemeinsame Nutzung von Ressourcen unerlässlich sind.
- DHCP-Server: Ein Router enthält oft einen integrierten DHCP-Server, der aktiviert werden kann, um IP-Adressen für Geräte, die dem Netzwerk beitreten, automatisch zuzuweisen und zu verwalten. Dadurch wird der Anschluss neuer Geräte vereinfacht und eine effiziente Zuweisung von IP-Adressen im Netzwerk gewährleistet.
- Firewall-Schutz: Die meisten Router sind mit eingebauten Firewalls ausgestattet, die als robuster Schutz vor Malware und anderen Bedrohungen dienen. Diese Firewalls schützen das Netzwerk und die angeschlossenen Geräte vor unbefugtem Zugriff und bösartigen Aktivitäten.
- VPN-Dienste: Einige Router sind in der Lage, virtuelle private Netzwerkverbindungen (VPN) zu unterstützen. Durch die Aktivierung von VPN-Diensten auf dem Router können Benutzer auf sichere, private Verbindungen zugreifen, ohne VPN-Anwendungen auf einzelnen Geräten installieren zu müssen. Dies erhöht den Datenschutz und die Sicherheit der Datenübertragungen im Netzwerk.
- Dateiserver: Einige fortschrittliche Router, wie z. B. der Linksys E3200 und E4200, sind mit einem USB-Anschluss ausgestattet, der den Anschluss von externen Laufwerken unterstützt. Diese Funktion verwandelt den Router in einen Dateiserver und ermöglicht den gemeinsamen Zugriff auf Dateien und Ressourcen innerhalb des Netzwerks oder über das Internet.
Wie funktioniert ein Router?
Router fungieren als Traffic-Kontrolleure, die Datenpakete zwischen Geräten oder Netzwerken präzise und effizient weiterleiten. Beim Empfang eines Datenpakets identifiziert der Router die Ziel-IP-Adresse anhand des Headers und konsultiert seine Routing-Tabelle – eine umfassende Liste von Pfaden zu verschiedenen Netzwerkzielen – um die effizienteste Route für die Datenübertragung zu ermitteln.
Durch die Auswertung von Faktoren wie Geschwindigkeit, Zuverlässigkeit und Netzwerküberlastung stellt der Router sicher, dass das Datenpaket über den besten verfügbaren Pfad weitergeleitet wird. Dieser intelligente Entscheidungsprozess ermöglicht dem Router, den Datentransfer so zu optimieren, dass die Daten schnell und präzise an den gewünschten Empfänger übermittelt werden.
Einrichtung eines Routers
Die Einrichtung eines Routers ist in der Regel ein unkomplizierter Prozess, insbesondere mit den benutzerfreundlichen Apps oder webbasierten Dashboards, die von den meisten Herstellern für Router zu Hause oder in kleinen Büros angeboten werden. Für größere Netzwerke und kommerzielle Router können jedoch fortgeschrittene Netzwerkkenntnisse erforderlich sein. Auch wenn die einzelnen Schritte von Router zu Router unterschiedlich sein können, gelten die folgenden grundlegenden Schritte für die meisten Modelle:
- Daten sammeln. Ermitteln Sie die Standard-IP-Adresse, den Benutzernamen und das Passwort für Ihren Router. Diese Daten finden Sie oft auf einem Aufkleber unter dem Gerät, in einem Handbuch oder auf der Website des Herstellers.
- Router verbinden. Verbinden Sie den LAN-Anschluss des PCs über ein Ethernet-Kabel mit dem WAN-Anschluss des Routers. Beachten Sie, dass die meisten WAN-Ports an einem Router eine andere Farbe haben als die LAN-Ports.
- IP-Adresse konfigurieren. Wenn der DHCP-Server des Routers aktiviert ist, weist er Ihrem Computer automatisch eine eindeutige IP-Adresse zu. Andernfalls konfigurieren Sie Ihren Computer manuell mit einer IP-Adresse im selben Netzwerk. Wenn die IP des Routers beispielsweise 198.168.1.1 lautet, weisen Sie Ihrem Computer 192.168.1.2 zu.
- Router-Einstellungen aufrufen. Öffnen Sie einen Webbrowser und geben Sie die IP-Adresse des Routers in die Adressleiste ein. Geben Sie dann den bereitgestellten Benutzernamen und das Passwort ein. Für einen Linksys E1200 Router verwenden Sie beispielsweise 192.168.1.1 als IP-Adresse und „admin“ als Benutzernamen und Passwort.
- Router-Einstellungen konfigurieren. Navigieren Sie zum Administrationsbereich und ändern Sie die LAN IP sowie den Benutzernamen und das Passwort des Administrators. Laden Sie die Firmware des Routers herunter und aktualisieren Sie sie für eine optimale Leistung.
- Drahtloses Netzwerk einrichten. Passen Sie im Abschnitt für drahtlose Netzwerke den Namen des Netzwerks oder die SSID (Service Set Identifier) an und aktivieren Sie eine Verschlüsselung wie WPA2-PSK. Vergewissern Sie sich, dass Sie ein sicheres und eindeutiges WLAN-Passwort erstellen.
- Anpassungsfähig. Erkunden Sie die anderen Seiten, um die Einstellungen des Routers an Ihre speziellen Anforderungen anzupassen, wie z. B. Portweiterleitung, Quality of Service (QoS) und Kindersicherung.
- Einstellungen speichern. Nachdem Sie die notwendigen Anpassungen vorgenommen haben, speichern Sie Ihre Einstellungen. Dies kann dazu führen, dass der Router neu gestartet werden muss, um die Änderungen zu übernehmen.
Wichtige Komponenten, Funktionen und Möglichkeiten von Routern
Router sind intelligente Geräte, die mit Komponenten wie einer CPU, Arbeitsspeicher, Speicher und Schnittstellenports ausgestattet sind und so den Netzwerkverkehr effizient verwalten und logische Funktionen ausführen können.
- CPU: Der Hauptprozessor führt Router-Befehle aus und verarbeitet sie. Seine Geschwindigkeit bestimmt, wie schnell der Router Befehle verarbeitet.
- Read-only Memory (ROM): Dieser Speicher enthält das Power-on Self-test-Script (POST), das für den Start oder Neustart des Routers eine wichtige Rolle spielt. Er enthält außerdem eine Software zur Wiederherstellung von Passwörtern und behält den Inhalt auch nach einem Stromausfall oder Neustart bei.
- RAM: Random-Access Memory bietet temporären Speicherplatz für die Dateien, die auf einem Router laufen. Im Gegensatz zum ROM verliert der RAM seinen Inhalt, sobald der Router die Stromversorgung verliert oder neu startet.
- Flash-Speicher: Dieser Speicher speichert das Betriebssystem des Routers und andere Dateien. Flash-Speicher behält den Inhalt auch nach dem Ausschalten des Routers bei und ermöglicht ein einfaches Ersetzen und Aktualisieren von Dateien.
- Ports: Router verfügen über verschiedene Ports für den Anschluss an verschiedene Netzwerke und Geräte. Üblicherweise haben Router mindestens einen WAN-Port fürdie Verbindung zu einem Modem oder Internetanbieter sowie LAN-Ports für lokale Netzwerkverbindungen. Kabelgebundene Router können mehrere LAN-Ports haben, während die meisten drahtlosen Router vier Ports haben. Einige Router verfügen auch über zwei WAN-Anschlüsse, die im Falle eines Ausfalls eine Backup-Verbindung über USB-Funkmodems oder Ethernet ermöglichen.
- Quality of Service (QoS): QoS ist ein entscheidender Kontrollmechanismus, der Benutzern ermöglicht, kritischen Anwendungen Priorität einzuräumen, indem eine angemessene Bandbreite zugewiesen wird. Auf diese Weise verhindern Sie Leistungseinbußen durch andere Netzwerkaktivitäten. Sie mit QoS sicherstellen, dass Videoanrufe oder Online-Spiele stabile Verbindungen aufrechterhalten, selbst wenn andere Benutzer bandbreitenintensive Aufgaben durchführen, wie etwa Medienstreaming.
- Firewall- und VPN-Funktionen: Einige Router verfügen über integrierte Firewall- und VPN-Funktionen, die einen zusätzlichen Schutz für Geräte im lokalen Netzwerk bieten. Dadurch entfällt die Notwendigkeit, Firewall-Hardware oder VPN-Anwendungen auf einzelnen Geräten zu installieren, und die Sicherheitsmaßnahmen für das gesamte Netzwerk werden optimiert.
Router-Betriebssystem
Das Router-Betriebssystem verwaltet und steuert die Ressourcen und Prozesse des Routers. Es wird beim Start des Routers geladen und bleibt betriebsbereit, bis das Gerät ausgeschaltet wird. Das Betriebssystem spielt mehrere Schlüsselrollen, darunter die Ausführung von Programmen, die Steuerung von Ein-/Ausgabeoperationen, die Zuweisung von Ressourcen und die Verwaltung von Dateisystemen. Die meisten kommerziellen und unternehmenstauglichen Router laufen mit den proprietären Betriebssystemen des Herstellers.
Neben den herstellerspezifischen Betriebssystemen gibt es auch generische, Open-Source- und Premium-Router-Betriebssysteme. Diese vielseitigen Alternativen können über verschiedene Marken von SOHO-WLAN-Geräten (Small Office/Home Office) oder auf x86-Computer basierten Routern eingesetzt werden.
Zu den gängigen Router-Betriebssystemen gehören:
- Cisco IOS: Hierbei handelt es sich um ein monolithisches Router-Betriebssystem, bei dem alle Dateien auf einem einzigen Image laufen und die Prozesse sich denselben Speicher teilen. Ein Nachteil dieses Ansatzes ist jedoch, dass der Ausfall eines Dienstes zu einem Systemabsturz führen kann und ein Fehler in einem Prozess andere Prozesse beeinträchtigen kann. Außerdem kann die Einführung neuer Funktionen oder Dienste ein Upgrade des gesamten IOS-Images erfordern.
- Jupiter JUNOS: Dieses modulare Betriebssystem basiert auf FreeBSD, mit Prozessen, die als separate Module in geschützten Speicherbereichen laufen. Im Gegensatz zu monolithischen Betriebssystemen stellt der modulare Ansatz sicher, dass ein Fehler in einem Prozess nicht das Betriebssystem beeinträchtigt. Darüber hinaus können neue Funktionen ohne ein vollständiges Upgrade hinzugefügt werden.
- Cisco IOS XR7: Dieses modular aufgebaute Betriebssystem überwindet die Einschränkungen des monolithischen IOS durch ein einfaches, flexibles Design, das leicht zu programmieren ist. Das Cisco IOS XR7 bietetschnellere Boot-Zeiten, verbrauchtweniger Speicher und unterstützt sowohl Access-Level- als auch Core-Geräte.
Routing-Protokolle
Routing-Protokolle sind die Regeln und Algorithmen, die Router verwenden, um den optimalen Pfad zum Erreichen eines Ziels zu bestimmen. Diese Protokolle spielen eine entscheidende Rolle dabei, wie Router sich gegenseitig identifizieren und wie Daten ihr Ziel im Netzwerk erreichen. Routing-Protokolle selbst bewegen diese Daten jedoch nicht, sondern aktualisieren die Routing-Tabelle, um eine effiziente Router-Kommunikation zu ermöglichen.
Je nach spezifischer Anwendung und Netzwerkanforderungen kann ein Router ein oder mehrere Routing-Protokolle implementieren.
- Routing Information Protocol (RIP): RIP wurde entwickelt, um den Informationsaustausch zwischen Routern bei der Übertragung von Daten über eine Gruppe von LANs zu erleichtern. Es sieht eine Höchstgrenze von 15 Sprüngen vor, was die Effektivität bei der Unterstützung größerer Netzwerke einschränken kann.
- Interior Gateway Routing Protocol (IGRP): IGRP definiert den Prozess des Austauschs von Routing-Informationen zwischen Gateways oder Edge-Routern innerhalb eines unabhängigen Netzwerks. Andere Netzwerkprotokolle können diese Daten dann nutzen, um festzustellen, wie der Traffic effektiv weitergeleitet werden kann.
- Open Shortest Path First (OSPF): OSPF ist ein hochgradig skalierbares Protokoll, das dynamisch die besten Routen für Datenpakete berechnet, während sie sich durch zusammengeschaltete Netzwerke bewegen. Das macht es besonders geeignet für große, komplexe Netzwerke.
- Border Gateway Protocol (BGP): BGP ist für das Routing von Paketen im Internet verantwortlich, indem es den Austausch von Daten zwischen Edge-Routern erleichtert. Internetanbieter verwenden BGP, um Routing-Informationen zwischen verschiedenen Netzwerken auszutauschen und so die Stabilität des Netzwerks zu gewährleisten, indem sie schnell auf alternative Netzwerkverbindungen umschalten, wenn die aktuelle Verbindung ausfällt, bevor die Pakete ihr Ziel erreichen.
Routing-Tabelle: Statisches und dynamisches Routing
Die Routing-Tabelle spielt eine entscheidende Rolle bei der Ermittlung der besten Routen zu allen Zielen innerhalb eines Netzwerks. Wenn ein Router Daten weiterleitet, konsultiert er die Routing-Tabelle, um den optimalen Pfad zum gewünschten Ziel zu ermitteln. Die Informationen in der Routing-Tabelle können auf zwei Arten eingegeben werden: durch manuelle Eingabe (statisches Routing) oder durch automatische Aktualisierung (dynamisches Routing).
Statisches Routing
Beim statischen Routing werden die Pfade zwischen zwei Routern manuell konfiguriert und können nicht automatisch aktualisiert werden. Wenn es Änderungen auf der Netzwerkseite gibt, muss die Routing-Tabelle manuell aktualisiert werden, um die neuen Pfade zu berücksichtigen. Statisches Routing bietet mehr Sicherheit, ein einfaches Design und eine leichte Implementierung. Es ist ideal für kleinere und weniger komplexe Netzwerke, in denen Änderungen seltener vorkommen..
Dynamisches Routing
Umgekehrt aktualisiert dynamisches Routing automatisch die Routing-Tabelle und passt sich so den Veränderungen im Netzwerk an. Wenn eine Änderung eintritt, z. B. ein Ausfall oder eine neue Verbindung, tauschen die betroffenen Router Informationen aus, und es werden Algorithmen verwendet, um neue Routing-Pfade zu berechnen. Die Routing-Tabelle wird dann entsprechend aktualisiert. Dynamisches Routing eignet sich besonders für größere und komplexere Netzwerke, in denen häufig Änderungen auftreten. Aufgrund der automatischen Aktualisierungen und der potenziellen Anfälligkeit für Netzwerkveränderungen gilt das dynamische Routing jedoch als weniger sicher als das statische Routing.
Router-Bänder: Einzel-, Dual- und Tri-Band
Drahtlose Router sind in verschiedenen Konfigurationen erhältlich, darunter Single-, Dual- oder Tri-Band-Modelle, die jeweils einzigartige Vorteile für Ihre Netzwerkanforderungen bieten. Die Anzahl der Bänder in einem Router wirkt sich direkt auf seine Leistung, Flexibilität und Fähigkeit aus, mehrere Geräte gleichzeitig zu bedienen.
- Single-Band-Router: Dieser Router-Typ arbeitet auf einem einzigen 2,4-GHz-Band und ist für kleinere Netzwerke mit weniger als zehn Geräten geeignet. Er bietet zwar eine grundlegende Konnektivität, aber seine begrenzte Bandbreite kann zu Überlastungen und Störungen führen, insbesondere in Gebieten mit zahlreichen WLAN-Netzwerken.
- Dual-Band-Router: Dual-Band-Router bieten sowohl ein 2,4-GHz- als auch ein 5,0-GHz-Band. Das Vorhandensein von zwei Bändern ermöglicht eine bessere Leistung im Vergleich zu Routern mit nur einem Band, die mehr Geräte aufnehmen können und die Überlastung des Netzwerks verringern. Ältere Geräte können sich mit dem 2,4-GHz-Kanal verbinden, während neuere und schnellere Geräte den 5,0-GHz-Kanal nutzen, um Interferenzen zu minimieren und eine reibungslosere Datenübertragung zu gewährleisten.
- Tri-Band-Router: Ein Tri-Band-Router verfügt über ein 2,4-GHz-Band und zwei 5,0-GHz-Bänder und ist damit ideal für Power-User und anspruchsvollere Netzwerkumgebungen. Mit dem zusätzlichen Band kann er eine größere Anzahl von Geräten unterstützen, ohne die Netzwerkleistung oder -geschwindigkeit zu beeinträchtigen. Darüber hinaus haben Benutzer die Möglichkeit, ein Band für bestimmte Geräte zu reservieren, um Interferenzen weiter zu minimieren und die Leistung zu optimieren.
Die Auswahl des geeigneten Routertyps hängt von Faktoren wie der Größe und dem Standort des Netzwerks, der Anzahl und der Kompatibilität der Geräte sowie der gewünschten Leistung ab. Tri-Band-Router bieten zwar die höchste Leistung und Flexibilität, sind aber unter Umständen teurer und für kleinere Netzwerke oder solche mit älteren Geräten, die hauptsächlich im 2,4-GHz-Band betrieben werden, unnötig. Für die meisten Anwendungen bietet ein Dualband-Router ein ausgewogenes Verhältnis zwischen Leistung und Erschwinglichkeit und erfüllt die Bedürfnisse der meisten Nutzer.
Wichtigste Routertypen
Die verschiedenen Routertypen sind jeweils für eine bestimmte Anwendung und einen bestimmten Standort optimiert. Einige können nur Heim- oder kleine Büronetzwerke unterstützen. Kommerzielle Hochleistungsrouter können mehrere Gigabyte an Daten pro Sekunde weiterleiten und eignen sich für Rechenzentren und andere Anwendungen mit hohem Datenverkehr. Hier sind einige der gängigsten Routertypen:
- Core-Router: Core-Router sind für eine maximale Bandbreite ausgelegt und verbinden mehrere Router und Switches in großen Netzwerken. Sie werden von Cloud-Anbietern, Anbietern von Kommunikationsdiensten mit hohem Datenverkehr und Organisationen mit umfangreichen Netzwerken und mehreren Standorten verwendet. Core-Router arbeiten innerhalb des Unternehmens und stellen keine Verbindung zu externen Netzwerken her.
- Edge-Router: Am Rande des Netzwerks positioniert, fungieren Edge-Router als Gateways und verbinden den Core-Router mit externen Netzwerken. Es handelt sich um Geräte mit hoher Bandbreite, die viele Endgeräte unterstützen.
- Mesh-Router: Mesh-Router bieten eine verbesserte drahtlose Abdeckung, indem sie mehrere WLAN-Sender in einem Gebiet einsetzen. Sie arbeiten als ein einziges Netzwerk und ermöglichen so eine nahtlose Erweiterung und verbesserte Abdeckung.
- Virtuelle Router: Virtuelle Router sind softwaredefiniert und werden über die Cloud betrieben. Sie bieten ähnliche Funktionen wie physische Geräte. Virtuelle Router bieten niedrige Einstiegskosten, einfache Skalierbarkeit, Flexibilität und eine reduzierte Verwaltung der lokalen Netzwerkhardware, was sie ideal für große Unternehmen mit komplexen Netzwerkanforderungen macht.
- Kabelrouter: Kabelrouter verwenden Ethernet- oder Glasfaserkabel, um Geräte mit dem Internet, lokalen oder externen Netzwerken zu verbinden. Sie verfügen über WAN-Ports und mehrere LAN-Ports für den Anschluss von Servern, Computern und Netzwerk-Switches zur Erweiterung des lokalen Netzwerks.
- Drahtlose Router: Drahtlose Router verwenden drahtlose Funksignale, um kompatible Geräte mit dem lokalen Netzwerk oder dem Internet zu verbinden. Sie verfügen in der Regel über WAN- und LAN-Ports sowie ein drahtloses Funksystem, mit dem Geräte auf das Internet sowie lokale und externe Netzwerke zugreifen können.
- Distribution Router: Diese Verteilungsrouter empfangen Daten von Edge-Routern über physische Kabel und verteilen sie über WLAN-Verbindungen an die Endbenutzer. Der Router verfügt außerdem über zusätzliche Ethernet-Ports, um weitere Router, Switches oder Benutzergeräte physisch anzuschließen.
- VPN-Router: VPN-Router bieten Schutz auf Hardware-Ebene für alle Geräte im lokalen Netzwerk und sorgen so für mehr Datenschutz und Sicherheit bei der Datenübertragung.
Kabelgebundene vs. drahtlose Router
Kabelgebundene und drahtlose Router haben unterschiedliche Eigenschaften in Bezug auf Gerätekonnektivität und Datenübertragung. Die Hauptunterschiede liegen in der Art und Weise, wie sich die Geräte mit ihnen verbinden und wie die Daten übertragen werden.
Kabelgebundene Router sind mit physischen WAN- und LAN-Ports ausgestattet, an die sich Geräte über Ethernet-Kabel anschließen können. Diese Router erfordern für die Datenübertragung eine kabelgebundene Verbindung zu den Geräten. Sie sind in der Regel robuster und für größere Netzwerke geeignet und bieten zuverlässige und stabile Verbindungen. Aufgrund ihres Designs und ihrer Fähigkeiten sind kabelgebundene Router oft teurer und größer als ihre drahtlosen Gegenstücke.
Im Gegensatz dazu verfügen drahtlose Router nicht nur über WAN- und LAN-Ports für kabelgebundene Verbindungen, sondern auch über einen Wireless-Adapter, mit dem sich Geräte drahtlos über Funksignale verbinden können. Diese kabellose Funktion bietet mehr Flexibilität und Komfort, denn sie ermöglicht die Verbindung von Geräten ohne physische Kabel. Drahtlose Router sind oft kleiner und erschwinglicher und werden häufig in Heim- und kleinen Büronetzwerken eingesetzt, in denen eine kabelgebundene Verbindung nicht möglich oder nicht sinnvoll ist.
Die meisten drahtlosen Router sind klein, billig und für Heim- und kleine Büronetzwerke konzipiert. Sie unterstützen sowohl kabelgebundene als auch drahtlose Verbindungen. Kabelgebundene Router sind große, teure Geräte, die große Netzwerke unterstützen können.
Unterschiede zwischen Router und Modems
Router und Modems haben unterschiedliche Funktionen und spielen eine unterschiedliche Rolle bei der Netzwerkkonnektivität.
Konnektivität
Ein Router verbindet mehrere Geräte in einem Netzwerk miteinander und verwaltet den Datenfluss zwischen verschiedenen Netzwerken oder mehreren Geräten in einem lokalen Netzwerk. Hingegen verbindet ein Modem Geräte oder ein lokales Netzwerk mit externen Netzwerken, einschließlich dem Internet.
Internetzugang
Während ein Modem ein einzelnes Gerät oder ein lokales Netzwerk mit dem Internet oder einem externen Netzwerk verbindet, ermöglicht ein Router mehreren Geräten den Zugriff auf das Internet über ein einziges Modem. Ein Router verteilt das Internetsignal an alle angeschlossenen Geräte innerhalb seines Netzwerks und ermöglicht so den gleichzeitigen Zugriff.
Datenkonvertierung
Ein Modem fungiert als Datenkonverter, der digitale Signale vom Router in analoge Signale umwandelt, bevor er sie an das Internet sendet. In ähnlicher Weise wandelt er analoge Signale aus dem Internet in digitale Form um, bevor er sie an den Router weiterleitet. Im Gegensatz dazu bietet ein Router keine Konvertierung; er konzentriert sich ausschließlich auf die Verwaltung des Datenflusses und die Lenkung des Netzwerkverkehrs.
Sicherheitsprobleme und Lösungen bei Routern
Router sind aufgrund ihrer wichtigen Rolle für die Netzwerkkonnektivität und den Datenfluss ein bevorzugtes Ziel für Cyberkriminalität. Standardmäßige oder schwache Passwörter, ungepatchte Firmware, fehlende Verschlüsselung, Fehlkonfigurationen und andere Sicherheitslücken in Routern sind Schwachstellen, die von Kriminellen ausgenutzt werden, um sich unerlaubt Zugang zu einem Computernetzwerk zu verschaffen.
Einmal kompromittiert, können Angreifer Malware auf Computern installieren, den Traffic umleiten, Daten stehlen oder den Router und das gesamte Netzwerk deaktivieren. Anfang 2022 hat ein Sicherheitsforscher Schwachstellen in Routern und Servern ausgenutzt, um Nordkorea vom Internet zu trennen.
Sicherheitsrisiken von Routern reduzieren
Wenn Sie die Schwachstellen eines Routers kennen, können Sie diese beheben, bevor Sie den Router in Ihr Netzwerk aufnehmen. Um die Sicherheitsrisiken für Router zu verringern und den Netzwerkschutz zu verbessern, sollten Sie die folgenden Maßnahmen in Betracht ziehen:
- Sicherheit des Anbieters prüfen. Bevor Sie einen Router in Ihr Netzwerk einbauen, sollten Sie die Erfolgsbilanz des Anbieters bei der Behebung von Sicherheitsschwachstellen überprüfen. Wählen Sie einen Anbieter, der dafür bekannt ist, dass er umgehend Updates und Patches zur Behebung bekannter Probleme bereitstellt.
- Starke Passwörter verwenden. Erstellen Sie starke und eindeutige Administrator- und Wi-Fi-Passwörter. Ändern Sie die Standard-IP-Adresse, den Benutzernamen und das Kennwort, um den Zugang zum Router weiter zu sichern.
- Starke Verschlüsselung aktivieren. Verwenden Sie eine starke Verschlüsselung, um die über den Router übertragenen Daten zu sichern und einen unbefugten Netzwerkzugriff zu verhindern. Wählen Sie den höchsten Verschlüsselungsstandard, der von Ihrem WLAN-Router unterstützt wird.
- Router-Firmware aktualisieren. Aktualisieren Sie regelmäßig die Router-Firmware, um Sicherheit, Konnektivität und Leistung zu verbessern. Aktualisieren Sie die Firmware bei der Ersteinrichtung manuell und aktivieren Sie anschließend automatische Updates, um den Router auf dem neuesten Stand zu halten.
- Eindeutige SSID verwenden. Verwenden Sie eine eindeutige, inhaltslose SSID für Ihr drahtloses Netzwerk, um die Identifizierung Ihrer Organisation und Ihrer persönlichen Daten zu vermeiden. So können Angreifer Sie nicht mit dem Netzwerk in Verbindung bringen.
Fazit
Router spielen in modernen Netzwerken eine entscheidende Rolle, da sie nahtlose Kommunikation und gemeinsame Nutzung von Ressourcen ermöglichen. Ob für einzelne Benutzer oder große Unternehmen, Router bilden das Rückgrat für die Internetverbindung und die Datenübertragung. In Anbetracht des vielfältigen Angebots an Routern ist es wichtig, dass Sie sich vor dem Kauf genau überlegen, welche Bedürfnisse Sie haben. Wenn Sie die verschiedenen Funktionen, Möglichkeiten und potenziell damit verbundenen Sicherheitsrisiken kennen, können Sie den für Ihre Netzwerkanforderungen am besten geeigneten Router auswählen und die notwendigen Vorkehrungen treffen, um Sicherheitslücken zu minimieren.
Die virtuelle private Cloud von Gcore nutzt virtualisierte Router, um private Netzwerke innerhalb unserer Cloud und öffentlich-private Verbindungen mit der Infrastruktur des Benutzers zu schaffen. Sie erhalten hervorragende Konnektivität, ein isoliertes und geschütztes Netzwerk für Ihre Server und eine flexible Subnetzverwaltung mit privaten Adressbereichen. Entdecken Sie die leistungsstarken Router von Gcore in unserem Blogbeitrag.
Starten Sie kostenlos mit der VP Cloud.
Ähnliche Artikel
Die KI-Infrastruktur, das Rückgrat der modernen Technologie, hat einen bedeutenden Wandel erfahren. Ursprünglich war sie in traditionellen On-Premises-Konfigurationen verwurzelt, hat sich allerdings zu dynamischeren, cloudbasierten und Edge




Melden Sie sich für unseren Newsletter an
Erhalten Sie die neuesten Branchentrends, exklusive Einblicke und Gcore-Updates direkt in Ihren Posteingang.