
Kubernetes is now the de-facto standard for container orchestration. With more and more organizations adopting Kubernetes, it is essential that we get our fundamental ops-infra in place before any migration. This post will focus on pushing out new releases of the application to our Kubernetes cluster i.e. Continuous Delivery.
Pre-requisites
- Running Kubernetes Cluster.
- A Spinnaker set-up with Jenkins CI enabled.
- Github webhook enabled for Jenkins jobs.
Strategy Overview
- Github + Jenkins : CI System to build the docker image and push to registry.
- Docker hub: Registry to store docker images.
- Spinnaker : CD System to enable automatic deployments to Staging environment and supervised deployment to Production.

Continuous Integration System
Although this post is about the CD system using Spinnaker. I want to briefly go over the CI pipeline so that the bigger picture is clear.
- Whenever the master branch of a Git repo gets merged, a Jenkins job is triggered via Github webhook. The commit message for the master merge should include the updated version of the app, and whether it is Kubernetes Deploy action or Patch action.
- The Jenkins job checks out the repo, builds code and the docker image according to the Dockerfile, and pushes it to Docker hub.
- It then triggers a Spinnaker pipeline and sends a trigger.properties file as a build artifact. This properties file contains very crucial info that is consumed by Spinnaker and will be explained later in this post.
Properties File
TAG=1.7-SNAPSHOTACTION=DEPLOYContinuous Delivery System
This is the crucial part. Spinnaker offers a ton of options for Kubernetes deployments. You can either consume manifests from GCS or S3 bucket or you can provide manifest as text within the pipeline.
Consuming manifests from GCS or S3 buckets includes more moving parts, and since this is an introductory blog, it is beyond this article’s scope right now. However, with that being said, I extensively use that approach as it is best in scenarios where you need to deploy a large number of micro-services running in Kubernetes as such pipelines are highly templatized and re-usable.
Today, we will deploy a sample Nginx Service which reads the app version from a pom.xml file and renders it on the browser. Application code and Dockerfile can be found here. The part where index.html is updated can be seen below (This is what the Jenkins job does basically).
#!/bin/bash#Author: Vaibhav Thakur#Checking whether commit was in master of not.if_master=`echo $payload | jq '.ref' | grep master`if [ $? -eq 1 ]; then echo "Pipeline should not be triggered" exit 2fi#Getting tag from pom.xmlTAG=`grep SNAPSHOT pom.xml | sed 's|[<,>,/,version ]||g'`echo $TAG#Getting action from commit messageACTION=$(echo $payload | jq -r '.commits[0].message' | cut -d',' -f2)#Updating index.htmlsed -i -- "s/VER/${TAG}/g" app/index.html#Pushing to dockerhubdocker build -t vaibhavthakur/nginx-demo:$TAG .docker push vaibhavthakur/nginx-demo:$TAGecho TAG=${TAG} > trigger.propertiesecho ACTION=${ACTION} >> trigger.propertiesThe manifest for the Nginx deployment and service is below:
apiVersion: v1kind: Namespacemetadata: name: nginx---apiVersion: extensions/v1beta1kind: Deploymentmetadata: namespace: nginx name: nginx-deploymentspec: replicas: 1 template: metadata: annotations: prometheus.io/path: "/status/format/prometheus" prometheus.io/scrape: "true" prometheus.io/port: "80" labels: app: nginx-server spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - nginx-server topologyKey: kubernetes.io/hostname containers: - name: nginx-demo image: vaibhavthakur/nginx-demo:1.0-SNAPSHOT imagePullPolicy: Always resources: limits: cpu: 2500m requests: cpu: 2000m ports: - containerPort: 80 name: http---apiVersion: v1kind: Servicemetadata: namespace: nginx name: nginx-service annotations: cloud.google.com/load-balancer-type: Internalspec: ports: - port: 80 targetPort: 80 name: http selector: app: nginx-server type: LoadBalancerSteps to Set-up the Pipeline
- Create a new application under the Aplications tab and add Project Name and you Email to it. Remaining fields can be left blank.
- Create a new project under Spinnaker and add your application under it. Also, you can add your staging and production Kubernetes cluster under it.

- Under the Application section add the Pipeline. Make sure that in the Trigger stage of the pipeline, Jenkins is enabled and the artifacts are consumed appropriately. (Don’t forget to modify it according to your credentials and endpoints.)
Spinnaker Pipeline
The pipeline configuration can be found here.
- Once you add it, the pipeline will look something like this:

Deep dive into the Pipeline
- Configuration: This is the stage where you mention the Jenkins endpoint, the job name and expected artifact from the job. In our case
trigger. properties. - Deploy (Manifest): The
trigger.propertiesfile has an action variable based on which we decide wether we need to trigger a new deployment for the new image tag to patch an existing deployment. The properties file (set in the TAG variable) also tells which version to deploy the patch with.

- Patch (Manifest): Similar to the Deploy stage this stage will check the same variable and if it evaluates to “PATCH”, then the current deployment will be patched. It should be noted that in both these stages, the Kubernetes cluster is being used as a staging cluster. Therefore, our deployments/patches for staging environment will be automatic.

- Manual Judgement: This is a very important stage. It is here where you decide whether or not you want to promote the currently running build in the staging cluster to the production cluster. This should be approved only when the staging build has been thoroughly tested by various stake holders.
- Deploy(Manifest) and Patch(Manifest): The final stages in both paths are similar to their counterparts in pre-approval stages. The only difference being that the cluster under Account is a production Kubernetes cluster.
Now you are ready to push out releases for your app. Once triggered, the pipeline will look like this:
- Pipeline triggered and automated deploy to Staging Cluster

- Manual Judgement stage gating the deploy to Production cluster

- Once Manual Judegement is approved, Pipeline proceeds and deploys to Production cluster

- Successful deploy to Production cluster

The sections in Grey have been skipped as the ACTION variable did not evaluate “PATCH”. Once you deploy, you can view the current version and also the previous versions under the Infrastructure Section.

Key Takeaways
- Emit as much data as you like to the properties file, and later consume it in a Spinnaker Pipeline.
- Trigger other Jenkins jobs from Spinnaker and then consume it’s artifacts in the subsequent stages.
- Spinnaker is quite a powerful tool which helps you perform all kinds of actions like roll-backs, scaling etc., right from the console.
- Not only deployments but all kinds of Kubernetes resources can be managed using Spinnaker.
- Spinnaker also provides excellent integration with Slack/Hipchat/Email for pipeline notifications.
Conclusion
We hope this helps you get started Continuous Delivery to your Kubernetes clusters. Spinnaker is an awesome tool which can deploy easily to multiple environments providing you with a single-pane-of-glass view for all your workloads across different clusters. Feel free to reach out in case you have any questions around the set-up.
Related articles

Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial
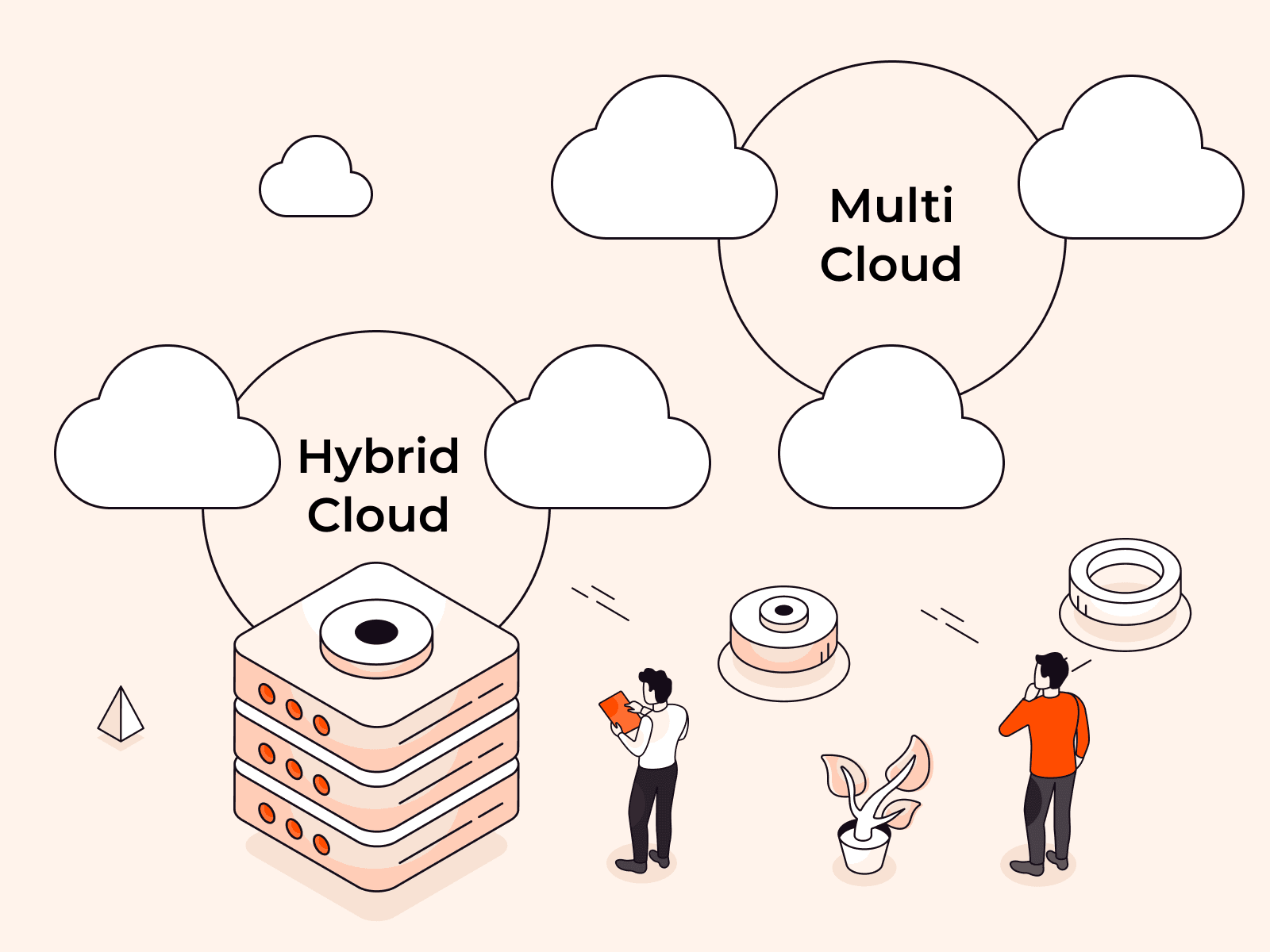
Multi-cloud and hybrid cloud represent two distinct approaches to distributed computing architecture that build upon the foundation of cloud computing to help organizations improve their IT infrastructure.Multi-cloud environments involve us
Multi-cloud is a cloud usage model where an organization utilizes public cloud services from two or more cloud service providers, often combining public, private, and hybrid clouds, as well as different service models, such as Infrastructur
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.