
Whether you’re at home or the office, your router plays a critical role in providing essential internet connectivity needed for work, entertainment, and communication. When issues arise or it’s time for an upgrade, it can be daunting to know where to begin. In this article, we’ll help you gain a comprehensive understanding of your router. You will discover how to avoid and resolve frustrating network issues, sluggish internet speeds, and security vulnerabilities, and choose the right router for your needs.
What Is a Router?
A router is a central hub that enables the seamless sharing of resources—like servers, printers, networks, and internet connections—between multiple devices. Routers play a vital role in efficiently managing the transfer of data between devices within a local network and across different networks.
Consider the router you might have in your apartment or home. It connects your devices, like your laptop or smartphone, to the internet, thus allowing you to browse websites, stream videos, and download files. Without it, your devices would not be able to communicate with the broader internet.
In an office environment, a router’s role becomes even more critical. In addition to providing internet access to multiple devices, a router can also facilitate the sharing of resources, such as servers and printers. Imagine you’re at your office desk, and you’ve just finished a report that you need to print. When you hit print on your computer, it’s the router that makes a pathway for your file to travel from your computer to the printer in the network, ensuring that your file reaches the correct destination and is printed out as you intended.
What Is a Router Used For?
A router facilitates data transfer between devices or can forward data to another router. Routers connect devices on a local network, allow them to communicate and transfer data. They enable devices to access the internet or external networks via a single connection point. Routers also allow connection and exchange of data between networks in different geographical locations. For example, a router can connect a regional or remote office to the head office.
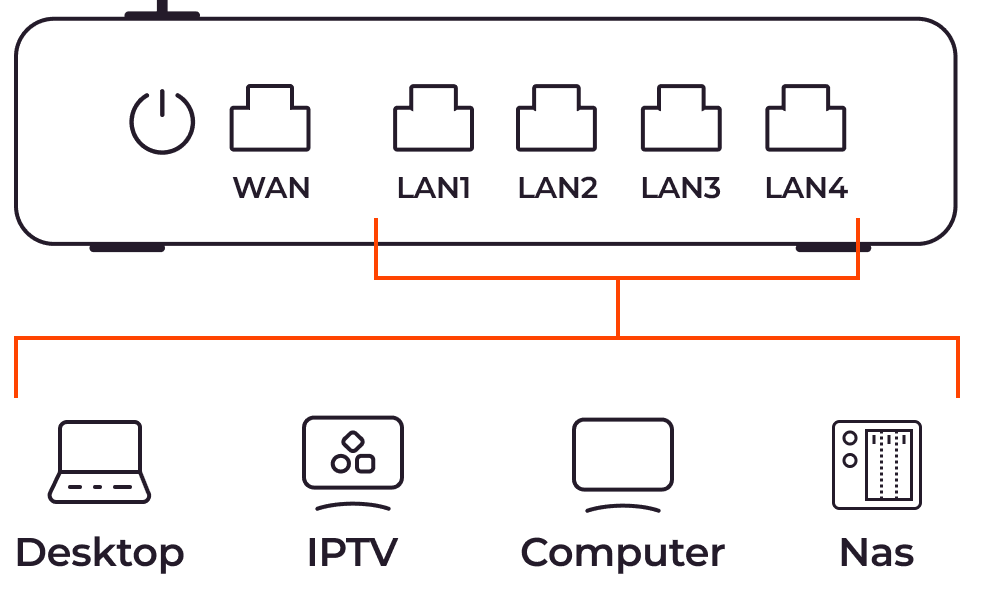
In addition to data transfer between networks, routers can perform other functions, which are indispensable tools for network management, security, and resource sharing.
- DHCP server: A router often includes an integrated DHCP server, which can be enabled to automatically assign and manage IP addresses for devices joining the network. This streamlines the process of connecting new devices and ensures efficient allocation of IP addresses within the network.
- Firewall protection: The majority of routers are equipped with inbuilt firewalls, serving as a robust defense against malware and other threats. These firewalls safeguard the network and its connected devices from unauthorized access and malicious activities.
- VPN services: Some routers have the capability to support virtual private network (VPN) connections. By enabling VPN services on the router, users can access secure, private connections without the need to install VPN applications on individual devices. This enhances privacy and security for data transmissions across the network.
- File server: Some advanced routers, such as the Linksys E3200 and E4200, are equipped with a USB port that supports the connection of external drives. This feature effectively transforms the router into a file server, enabling shared access to files and resources within the network or over the internet.
How Does a Router Work?
Routers function as data traffic controllers, directing and forwarding data packets between devices or networks with precision and efficiency. Upon receiving a data packet, the router identifies the destination IP address from its header and consults its routing table—a comprehensive list of paths to various network destinations—to determine the most efficient route for data transfer.
By evaluating factors like speed, reliability, and network congestion, the router ensures that the data packet is forwarded through the best available path. This intelligent decision-making process enables the router to optimize the data transfer process, resulting in swift and accurate delivery to the intended recipient across the interconnected network landscape.
How to Set Up a Router
Setting up a router is typically a straightforward process, especially with the user-friendly apps or web-based dashboards provided by most manufacturers for home or small office routers. However, for larger networks and commercial routers, advanced networking skills may be required. Though specific steps may differ between routers, the following basic steps apply to most models:
- Gather information. Determine the default IP address, username, and password for your router. The information often is available on a sticker under the device, in a manual, or on the manufacturer’s website.
- Connect the router. Connect the computer’s LAN port to the router’s WAN port using an Ethernet cable. Note that most WAN ports on a router have a different color from the LAN ports.
- IP address configuration. If the router’s DHCP server is enabled, it will automatically assign a unique IP address to your computer. Otherwise, manually configure your computer with an IP address on the same network. For example, if the router’s IP is 198.168.1.1, assign your computer 192.168.1.2.
- Access router settings. Open a web browser and type the router’s IP address in the address bar. Then, enter the provided username and password. For example, for a Linksys E1200 router, use 192.168.1.1 as the IP address, and “admin” for both the username and password.
- Configure router settings. Navigate to the Administration page and modify the LAN IP, admin username, and password. Download and update the router’s firmware for optimal performance.
- Wireless network setup. On the Wireless page, customize the name of the wireless network or service set identifier (SSID), and enable encryption such as WPA2-PSK. Ensure you create a strong and unique Wi-Fi password.
- Customization. Explore other pages to tailor the router’s settings to your specific requirements, such as port forwarding, quality of service (QoS,) and parental controls.
- Save settings. After making the necessary adjustments, save your settings. This may cause the router to restart in order to apply the changes.
Key Components, Features, and Capabilities of Routers
Routers are smart devices, equipped with components including a CPU, memory, storage, and interface ports, enabling them to manage network traffic efficiently and perform logical functions.
- CPU: The central processing unit executes and processes router commands. Its speed dictates how quickly the router processes commands.
- Read-only memory (ROM): This storage contains the power-on self-test (POST) script, crucial for router startup or restart. It also contains password recovery software and retains its content even after power loss or restart.
- RAM: The random-access memory provides temporary storage for the files running on a router. Unlike the ROM, the RAM loses its content when the router loses power or restarts.
- Flash memory: The memory stores the router’s operating system and other files. Flash memory retains its content even after powering off the router, and allows for easy replacement and updating of files.
- Ports: Routers feature various ports to connect to different networks and devices. Commonly, routers have at least one WAN port for connecting to a modem or ISP, as well as LAN ports for local area network connections. Wired routers may have multiple LAN ports, while most wireless routers have four ports. Some routers also have dual WAN ports, allowing for backup connections via USB wireless modems or Ethernet in case of failure.
- Quality of Service (QoS): QoS is a crucial control mechanism that allows users to prioritize critical applications by dedicating adequate bandwidth. Doing so prevents performance degradation resulting from other network activities. For instance, with QoS, you can ensure that video calls or online games maintain stable connections, even when other users engage in bandwidth-intensive tasks like streaming media.
- Firewall and VPN features: Some routers come with built-in firewall and VPN capabilities, providing an extra layer of protection for devices on the local network. This eliminates the need to install firewall hardware or VPN apps on individual devices, streamlining security measures for the entire network.
Router Operating System
The router operating system (OS) manages and controls router resources and processes. It is loaded during router startup and remains operational until the device is powered down. The OS plays several key roles, including executing programs, controlling input/output operations, allocating resources, and managing file systems. Most commercial and enterprise-grade routers run on the vendor’s proprietary operating systems.
In addition to vendor-specific OS options, there are generic, open-source, and premium router operating systems available. These versatile alternatives can be deployed across several brands of small office/home office (SOHO) Wi-Fi devices or x86 computer-based routers.
Popular router operating systems include:
- Cisco IOS: This is a monolithic router operating system where all files run on a single image, and the processes share the same memory. However, one drawback of this approach is that if one service fails, it may lead to a system crash, and a bug in one process can impact other processes. Additionally, introducing new features or services may require upgrading the entire IOS image.
- Jupiter JUNOS: This modular OS is based on FreeBSD, with processes running as separate modules in protected memory spaces. Unlike monolithic OS designs, the modular approach ensures that a bug in one process will not affect the OS. In addition, adding new features can be accomplished without a full upgrade.
- Cisco IOS XR7: This modular-based OS overcomes the limitations of the monolithic IOS by providing a simple, flexible design that is easy to program. The Cisco IOS XR7 offers faster boot times, consumes less memory, and supports both access-level and core devices.
Router Protocols
Routing protocols serve as the rules and algorithms that routers use to determine the optimal path for reaching a destination. These protocols play a critical role in how routers identify one another and how data reaches its destination across a network. However, the routing protocols themselves do not move the information; instead, they update the routing table to facilitate efficient router communication.
Depending on the specific application and network requirements, a router may implement one or more routing protocols.
- Routing Information Protocol (RIP): RIP is designed to facilitate information sharing among routers when moving data across a group of LANs. It imposes a maximum limit of 15 hops, which can restrict its effectiveness in supporting larger networks.
- Interior Gateway Routing Protocol (IGRP): IGRP defines the process of exchanging routing information between gateways or edge routers within an independent network. Other network protocols can then use this information to establish how to route traffic effectively.
- Open Shortest Path First (OSPF): OSPF is a highly scalable protocol that dynamically calculates the best routes for data packets as they move through interconnected networks. This makes it particularly suitable for large, complex networks.
- Border Gateway Protocol (BGP): BGP is responsible for routing packets on the internet by facilitating the exchange of information between edge routers. Internet service providers (ISPs) use BGP to share routing information between different networks, ensuring network stability by rapidly switching to alternative network connections if the current one fails before packets reach their destination.
Routing Table: Static and Dynamic Routing
The routing table plays a crucial role in determining the best routes to all destinations within a network. When a router forwards data, it consults the routing table to determine the optimal path to the intended destination. Routing table information can be populated in two ways: through manual entry (static routing) or automatic updates (dynamic routing.)
Static Routing
In static routing, the paths between two routers are manually configured and cannot be updated automatically. If there are changes on the network side, the routing table must be manually updated to reflect the new paths. Static routing offers enhanced security, simplicity in design, and ease of implementation. It is ideal for smaller and less complex networks where changes occur infrequently.
Dynamic Routing
Conversely, dynamic routing automatically updates the routing table, adapting to changes in the network. When a change occurs, like a failure or new connection, the affected routers exchange information, and algorithms are used to calculate new routing paths. The routing table is then updated accordingly. Dynamic routing is particularly suitable for larger and more complex networks where frequent changes occur. However, due to the automatic updates and potential exposure to network changes, dynamic routing is considered to be less secure than static routing.
Router Bands: Single, Dual, and Tri-Band
Wireless routers come in a range of configurations, including single, dual, or tri-band models, each offering unique advantages to meet network needs. The number of bands in a router directly impacts its performance, flexibility, and ability to handle multiple devices simultaneously.
- Single-band router: This type of router operates on a single 2.4 GHz band and is suitable for smaller networks with fewer than ten devices. While it provides basic connectivity, its limited bandwidth may lead to congestion and interference, especially in areas with numerous Wi-Fi networks.
- Dual-band router: Dual-band routers offer both a 2.4 GHz and a 5.0 GHz band. The presence of two bands allows for improved performance compared to single-band routers, accommodating more devices and reducing network congestion. Older devices can connect to the 2.4 GHz channel, while newer and faster devices utilize the 5.0 GHz channel, mitigating interference and ensuring smoother data transmission.
- Tri-band router: A tri-band router boasts one 2.4 GHz band and two 5.0 GHz bands, making it ideal for power users and more demanding network environments. With the additional band, it can support a higher number of devices without compromising network performance or speed. Moreover, users have the option to dedicate a band to specific devices, further minimizing interference and optimizing performance.
Selecting the appropriate type of router depends on factors like the size and location of the network, the number and compatibility of the devices, and the desired level of performance. While tri-band routers provide the highest performance and flexibility, they may be costlier and unnecessary for smaller networks or those with older devices primarily running on the 2.4 GHz band. For most applications, a dual-band router strikes a balance between performance and affordability, catering to the needs of the majority of users.
Main Types of Routers
Different types of routers are each optimized for a particular application and location. Some can only support home or small office networks. High-performance, commercial routers can forward several gigabytes of data per second and are suitable for data centers and other high-traffic applications. Here are some of the most common router types:
- Core routers: Core routers are designed to deliver maximum bandwidth, connecting multiple routers and switches within large networks. They are used by cloud providers, high-traffic communication service providers, and organizations with extensive networks and multiple locations. Core routers operate within the organization and do not connect to external networks.
- Edge routers: Positioned at the edge of the network, edge routers act as gateways, connecting the core router to external networks. They are high-bandwidth devices supporting many end-user devices.
- Mesh router: Mesh routers offer improved wireless coverage by deploying multiple Wi-Fi transmitters throughout an area. They work as a single network, allowing seamless expansion and enhanced coverage.
- Virtual router: Virtual routers are software-defined and operate via the cloud, providing similar functionality to physical devices. Virtual routers offer low entry costs, easy scalability, flexibility, and reduced local network hardware management, making them ideal for large organizations with complex network requirements.
- Wired routers: Wired routers use Ethernet or fiber cables to connect devices to the internet, local or external networks. They feature WAN ports and several LAN ports to connect servers, computers, and network switches, expanding the local area network.
- Wireless routers: Wireless routers use wireless radio signals to connect compatible devices to the local area network or the internet. They typically have WAN and LAN ports, along with a wireless radio, enabling devices to access the internet and local and external networks.
- Distribution routers: Distribution routers receive data from edge routers through physical cables and distribute it to end users via Wi-Fi connections. The router also comes with additional Ethernet ports to connect additional routers, switches, or user devices physically.
- VPN router: VPN routers provide hardware-level protection for all devices on the local network, ensuring enhanced privacy and security for data transmission.
Wired vs. Wireless Routers
Wired and wireless routers have distinct characteristics in terms of device connectivity and transfer data. The key differences lie in how devices connect to them and the means through which data is transmitted.
Wired routers are equipped with physical WAN and LAN ports, and devices can connect to them using Ethernet cables. These routers require devices to have a wired connection for data transfer. They are typically more robust and suitable for larger networks, offering reliable and stable connections. Due to their design and capabilities, wired routers are often more expensive and physically larger than their wireless counterparts.
In contrast, wireless routers not only have WAN and LAN ports for wired connections but also include a wireless adapter that allows devices to connect wirelessly via radio signals. This wireless capability provides greater flexibility and convenience, enabling devices to connect without the need for physical cables. Wireless routers are often smaller, more affordable, and commonly used in home and small office networks, where wired connections may not be feasible or convenient.
Most wireless routers are small, cheap, and designed for home and small office networks. They support both wired and wireless connections. Wired routers are large, expensive devices that can support large networks.
Differences Between Routers and Modems
Routers and modems serve distinct functions and play different roles in network connectivity.
Connectivity
A router connects multiple devices within a network, managing the flow of data between different networks or multiple devices in a local area network. On the other hand, a modem connects devices or a local network to external networks, including the Internet.
Internet Access
While a modem connects a single device or local network to the internet or external network, a router allows multiple devices to access the internet using a single modem. A router distributes the internet signal to all connected devices within its network, enabling simultaneous access.
Data Conversion
A modem functions as a data converter, converting digital signals from the router into analog signals before sending them to the internet. Similarly, it converts analog signals from the internet into digital form before forwarding them to the router. In contrast, a router does not provide any conversion; it solely focuses on managing data flow and directing network traffic.
Router Security Vulnerabilities and Solutions
Routers are prime targets for cybercrime due to their significant role in network connectivity and data flow. Default or weak passwords, unpatched firmware, lack of encryption, misconfigurations, and other security flaws in routers are vulnerabilities exploited by criminals to gain unauthorized access to a computer network.
Once compromised, attackers can install malware on computers, reroute traffic, steal data, or disable the router and the entire network. In early 2022, a security researcher exploited vulnerabilities in routers and servers to disconnect North Korea from the internet.
How to Reduce Router Security Risks
Understanding router vulnerabilities helps address them before adding the router to your network. To reduce router security risks and enhance network protections, consider implementing the following measures:
- Check vendor security. Before adding a router to your network, research the vendor’s track record in addressing security vulnerabilities. Choose a vendor known for promptly releasing updates and patches to address known issues.
- Use strong passwords. Create strong and unique administrator and Wi-Fi passwords. Change the default IP address, username, and password to further secure router access.
- Enable strong encryption. Utilize strong encryption to secure data transmitted through the router and prevent unauthorized network access. Choose the highest standard of encryption supported by your wireless router.
- Update router firmware. Regularly update router firmware to improve security, connectivity, and performance. Manually update the firmware during the initial setup and then enable automatic updates to keep the router up-to-date.
- Unique SSID. Use a unique, nondescript SSID for your wireless network to avoid identifying your organization and personal information. This prevents attackers from associating you with the network.
Conclusion
Routers play a crucial role in modern networks, enabling seamless communication and resource sharing. Whether for individual users or large organizations, routers provide the backbone for internet connectivity and data transfer. Given the diverse range of routers available, it is essential to carefully consider your specific needs before making a purchase. By understanding the various features, capabilities, and potential associated security risks, you can select the most suitable router for your network requirements and take necessary precautions to minimize security vulnerabilities.
Gcore's Virtual Private Cloud utilizes virtualized routers to create private networks within our cloud and public-private interconnections with the user’s other infrastructure. You get outstanding connectivity, an isolated and protected network for your servers, and flexible subnet management using private address ranges.
Related articles


Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.