How to add a VOD uploading feature to your iOS app in 15 minutes
- March 30, 2023
- 13 min read

This is a step-by-step guide on Gcore’s solution for adding a new VOD feature to your iOS application in 15 minutes. The feature allows users to record videos from their phone, upload videos to storage, and play videos in the player inside the app.
Here is what the result will look like:
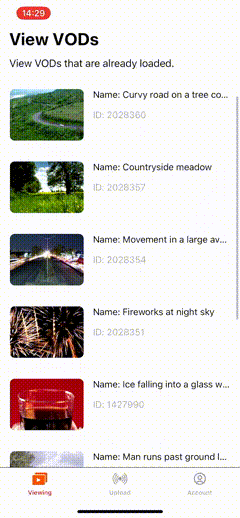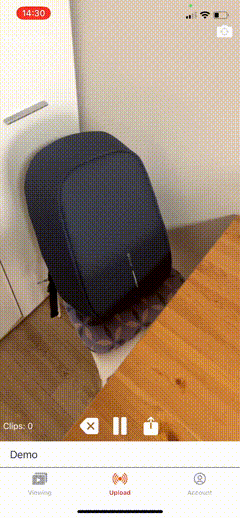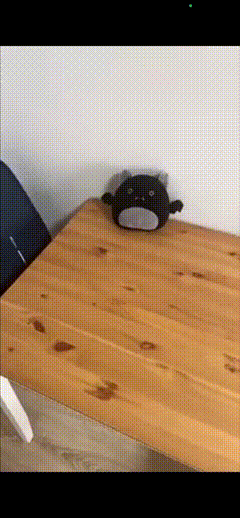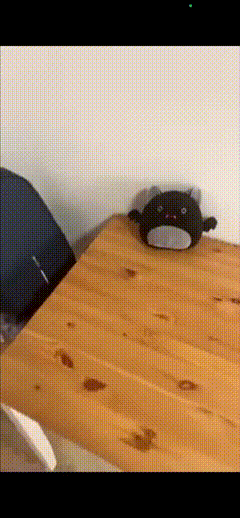
This is part of a series of guides about adding new video features to an iOS application. In other articles, we show you how to create a mobile streaming app on iOS, and how to add video call and smooth scrolling VOD features to an existing app.
What functions you can add with the help of this guide
The solution includes the following:
- Recording: Local video recording directly from the device’s camera; gaining access to the camera and saving raw video to internal storage.
- Uploading to the server: Uploading the recorded video to cloud video hosting, uploading through TUSclient, async uploading, and getting a link to the processed video.
- List of videos: A list of uploaded videos with screenshot covers and text descriptions.
- Player: Playback of the selected video in AVPlayer with ability to cache, play with adaptive bitrate of HLS, rewind, etc.
How to add the VOD feature
Step 1: Permissions
The project uses additional access rights that need to be specified. These are:
- NSMicrophoneUsageDescription (Privacy: Microphone Usage Description)
- NSCameraUsageDescription (Privacy: Camera Usage Description).
Step 2: Authorization
You’ll need a Gcore account, which can be created in just 1 minute at gcore.com. You won’t need to pay anything; you can test the solution with a free plan.
To use Gcore services, you’ll need an access token, which comes in the server’s response to the authentication request. Here’s how to get it:
1. Create a model that will come from the server.
struct Tokens: Decodable { let refresh: String let access: String }2. Create a common protocol for your requests.
protocol DataRequest { associatedtype Response var url: String { get } var method: HTTPMethod { get } var headers: [String : String] { get } var queryItems: [String : String] { get } var body: Data? { get } var contentType: String { get } func decode(_ data: Data) throws -> Response } extension DataRequest where Response: Decodable { func decode(_ data: Data) throws -> Response { let decoder = JSONDecoder() return try decoder.decode(Response.self, from: data) } } extension DataRequest { var contentType: String { "application/json" } var headers: [String : String] { [:] } var queryItems: [String : String] { [:] } var body: Data? { nil } }3. Create an authentication request.
struct AuthenticationRequest: DataRequest { typealias Response = Tokens let username: String let password: String var url: String { GсoreAPI.authorization.rawValue } var method: HTTPMethod { .post } var body: Data? { try? JSONEncoder().encode([ "password": password, "username": username, ]) } }4. Then you can use the request in any part of the application, using your preferred approach for your internet connection. For example:
func signOn(username: String, password: String) { let request = AuthenticationRequest(username: username, password: password) let communicator = HTTPCommunicator() communicator.request(request) { [weak self] result in switch result { case .success(let tokens): Settings.shared.refreshToken = tokens.refresh Settings.shared.accessToken = tokens.access Settings.shared.username = username Settings.shared.userPassword = password DispatchQueue.main.async { self?.view.window?.rootViewController = MainController() } case .failure(let error): self?.errorHandle(error) } } }Step 3: Setting up the camera session
In mobile apps on iOS systems, the AVFoundation framework is used to work with the camera. Let’s create a class that will work with the camera at a lower level.
1. Create a protocol in order to send the path to the recorded fragment and its time to the controller, as well as the enumeration of errors that may occur during initialization. The most common error is that the user did not grant the rights for camera use.
import Foundation import AVFoundation enum CameraSetupError: Error { case accessDevices, initializeCameraInputs } protocol CameraDelegate: AnyObject { func addRecordedMovie(url: URL, time: CMTime) }2. Create the camera class with properties and initializer.
final class Camera: NSObject { var movieOutput: AVCaptureMovieFileOutput! weak var delegate: CameraDelegate? private var videoDeviceInput: AVCaptureDeviceInput! private var rearCameraInput: AVCaptureDeviceInput! private var frontCameraInput: AVCaptureDeviceInput! private let captureSession: AVCaptureSession // There may be errors during initialization, if this happens, the initializer throws an error to the controller init(captureSession: AVCaptureSession) throws { self.captureSession = captureSession //check access to devices and setup them guard let rearCamera = AVCaptureDevice.default(for: .video), let frontCamera = AVCaptureDevice.default(.builtInWideAngleCamera, for: .video, position: .front), let audioInput = AVCaptureDevice.default(for: .audio) else { throw CameraSetupError.accessDevices } do { let rearCameraInput = try AVCaptureDeviceInput(device: rearCamera) let frontCameraInput = try AVCaptureDeviceInput(device: frontCamera) let audioInput = try AVCaptureDeviceInput(device: audioInput) let movieOutput = AVCaptureMovieFileOutput() if captureSession.canAddInput(rearCameraInput), captureSession.canAddInput(audioInput), captureSession.canAddInput(frontCameraInput), captureSession.canAddOutput(movieOutput) { captureSession.addInput(rearCameraInput) captureSession.addInput(audioInput) self.videoDeviceInput = rearCameraInput self.rearCameraInput = rearCameraInput self.frontCameraInput = frontCameraInput captureSession.addOutput(movieOutput) self.movieOutput = movieOutput } } catch { throw CameraSetupError.initializeCameraInputs } }3. Create methods. Depending on user’s actions on the UI layer, the controller will call the corresponding method.
func flipCamera() { guard let rearCameraIn = rearCameraInput, let frontCameraIn = frontCameraInput else { return } if captureSession.inputs.contains(rearCameraIn) { captureSession.removeInput(rearCameraIn) captureSession.addInput(frontCameraIn) } else { captureSession.removeInput(frontCameraIn) captureSession.addInput(rearCameraIn) } } func stopRecording() { if movieOutput.isRecording { movieOutput.stopRecording() } } func startRecording() { if movieOutput.isRecording == false { guard let outputURL = temporaryURL() else { return } movieOutput.startRecording(to: outputURL, recordingDelegate: self) DispatchQueue.main.asyncAfter(deadline: .now() + 0.1) { [weak self] in guard let self = self else { return } self.timer = Timer.scheduledTimer(timeInterval: 1, target: self, selector: #selector(self.updateTime), userInfo: nil, repeats: true) self.timer?.fire() } } else { stopRecording() } }4. To save a video fragment in memory, you will need a path for it. This method returns this path:
// Creating a temporary storage for the recorded video fragment private func temporaryURL() -> URL? { let directory = NSTemporaryDirectory() as NSString if directory != "" { let path = directory.appendingPathComponent(UUID().uuidString + ".mov") return URL(fileURLWithPath: path) } return nil } }5. Subscribe to the protocol in order to send the path to the controller.
//MARK: - AVCaptureFileOutputRecordingDelegate //When the shooting of one clip ends, it sends a link to the file to the delegate extension Camera: AVCaptureFileOutputRecordingDelegate { func fileOutput(_ output: AVCaptureFileOutput, didFinishRecordingTo outputFileURL: URL, from connections: [AVCaptureConnection], error: Error?) { if let error = error { print("Error recording movie: \(error.localizedDescription)") } else { delegate?.addRecordedMovie(url: outputFileURL, time: output.recordedDuration) } } }Step 4: Layout for the camera
Create a class that will control the camera on the UI level. The user will transmit commands through this class, and it will send its delegate to send the appropriate commands to the preceding class.
Note: You will need to add your own icons or use existing ones in iOS.
1. Create a protocol so that your view can inform the controller about user actions.
protocol CameraViewDelegate: AnyObject { func tappedRecord(isRecord: Bool) func tappedFlipCamera() func tappedUpload() func tappedDeleteClip() func shouldRecord() -> Bool }2. Create the camera view class and initialize the necessary properties.
final class CameraView: UIView { var isRecord = false { didSet { if isRecord { recordButton.setImage(UIImage(named: "pause.icon"), for: .normal) } else { recordButton.setImage(UIImage(named: "play.icon"), for: .normal) } } } var previewLayer: AVCaptureVideoPreviewLayer? weak var delegate: CameraViewDelegate? let recordButton: UIButton = { let button = UIButton() button.setImage(UIImage(named: "play.icon"), for: .normal) button.imageView?.contentMode = .scaleAspectFit button.addTarget(self, action: #selector(tapRecord), for: .touchUpInside) button.translatesAutoresizingMaskIntoConstraints = false return button }() let flipCameraButton: UIButton = { let button = UIButton() button.setImage(UIImage(named: "flip.icon"), for: .normal) button.imageView?.contentMode = .scaleAspectFit button.addTarget(self, action: #selector(tapFlip), for: .touchUpInside) button.translatesAutoresizingMaskIntoConstraints = false return button }() let uploadButton: UIButton = { let button = UIButton() button.setImage(UIImage(named: "upload.icon"), for: .normal) button.imageView?.contentMode = .scaleAspectFit button.addTarget(self, action: #selector(tapUpload), for: .touchUpInside) button.translatesAutoresizingMaskIntoConstraints = false return button }() let clipsLabel: UILabel = { let label = UILabel() label.textColor = .white label.font = .systemFont(ofSize: 14) label.textAlignment = .left label.text = "Clips: 0" return label }() let deleteLastClipButton: Button = { let button = Button() button.setTitle("", for: .normal) button.setImage(UIImage(named: "delete.left.fill"), for: .normal) button.addTarget(self, action: #selector(tapDeleteClip), for: .touchUpInside) return button }() let recordedTimeLabel: UILabel = { let label = UILabel() label.text = "0s / \(maxRecordTime)s" label.font = .systemFont(ofSize: 14) label.textColor = .white label.textAlignment = .left return label }() }3. Since the view will show the image from the device’s camera, you need to link it to the session and configure it.
func setupLivePreview(session: AVCaptureSession) { let previewLayer = AVCaptureVideoPreviewLayer.init(session: session) self.previewLayer = previewLayer previewLayer.videoGravity = .resizeAspectFill previewLayer.connection?.videoOrientation = .portrait layer.addSublayer(previewLayer) session.startRunning() backgroundColor = .black } // when the size of the view is calculated, we transfer this size to the image from the camera override func layoutSubviews() { previewLayer?.frame = bounds }4. Create a layout for UI elements.
private func initLayout() { [clipsLabel, deleteLastClipButton, recordedTimeLabel].forEach { $0.translatesAutoresizingMaskIntoConstraints = false addSubview($0) } NSLayoutConstraint.activate([ flipCameraButton.topAnchor.constraint(equalTo: topAnchor, constant: 10), flipCameraButton.rightAnchor.constraint(equalTo: rightAnchor, constant: -10), flipCameraButton.widthAnchor.constraint(equalToConstant: 30), flipCameraButton.widthAnchor.constraint(equalToConstant: 30), recordButton.centerXAnchor.constraint(equalTo: centerXAnchor), recordButton.bottomAnchor.constraint(equalTo: bottomAnchor, constant: -5), recordButton.widthAnchor.constraint(equalToConstant: 30), recordButton.widthAnchor.constraint(equalToConstant: 30), uploadButton.leftAnchor.constraint(equalTo: recordButton.rightAnchor, constant: 20), uploadButton.bottomAnchor.constraint(equalTo: bottomAnchor, constant: -5), uploadButton.widthAnchor.constraint(equalToConstant: 30), uploadButton.widthAnchor.constraint(equalToConstant: 30), clipsLabel.leftAnchor.constraint(equalTo: leftAnchor, constant: 5), clipsLabel.centerYAnchor.constraint(equalTo: uploadButton.centerYAnchor), deleteLastClipButton.centerYAnchor.constraint(equalTo: clipsLabel.centerYAnchor), deleteLastClipButton.rightAnchor.constraint(equalTo: recordButton.leftAnchor, constant: -15), deleteLastClipButton.widthAnchor.constraint(equalToConstant: 30), deleteLastClipButton.widthAnchor.constraint(equalToConstant: 30), recordedTimeLabel.topAnchor.constraint(equalTo: layoutMarginsGuide.topAnchor), recordedTimeLabel.leftAnchor.constraint(equalTo: leftAnchor, constant: 5) ]) }The result of the layout will look like this:

5. Add the initializer. The controller will transfer the session in order to access the image from the camera:
convenience init(session: AVCaptureSession) { self.init(frame: .zero) setupLivePreview(session: session) addSubview(recordButton) addSubview(flipCameraButton) addSubview(uploadButton) initLayout() 6. Create methods that will work when the user clicks on the buttons.
@objc func tapRecord() { guard delegate?.shouldRecord() == true else { return } isRecord = !isRecord delegate?.tappedRecord(isRecord: isRecord) } @objc func tapFlip() { delegate?.tappedFlipCamera() } @objc func tapUpload() { delegate?.tappedUpload() } @objc func tapDeleteClip() { delegate?.tappedDeleteClip() } }Step 5: Interaction with recorded fragments
On an iPhone, the camera records video in fragments. When the user decides to upload the video, you need to collect its fragments into one file and send it to the server. Create another class that will do this command.
Note: When creating a video, an additional file will be created. This file will collect all the fragments, but at the same time, these fragments will remain in the memory until the line-up is completed. In the worst case, it can cause a lack of memory and crash from the application. To avoid this, we recommend limiting the recording time allowed.
import Foundation import AVFoundation final class VideoCompositionWriter: NSObject { private func merge(recordedVideos: [AVAsset]) -> AVMutableComposition { // create empty composition and empty video and audio tracks let mainComposition = AVMutableComposition() let compositionVideoTrack = mainComposition.addMutableTrack(withMediaType: .video, preferredTrackID: kCMPersistentTrackID_Invalid) let compositionAudioTrack = mainComposition.addMutableTrack(withMediaType: .audio, preferredTrackID: kCMPersistentTrackID_Invalid) // to correct video orientation compositionVideoTrack?.preferredTransform = CGAffineTransform(rotationAngle: .pi / 2) // add video and audio tracks from each asset to our composition (across compositionTrack) var insertTime = CMTime.zero for i in recordedVideos.indices { let video = recordedVideos[i] let duration = video.duration let timeRangeVideo = CMTimeRangeMake(start: CMTime.zero, duration: duration) let trackVideo = video.tracks(withMediaType: .video)[0] let trackAudio = video.tracks(withMediaType: .audio)[0] try! compositionVideoTrack?.insertTimeRange(timeRangeVideo, of: trackVideo, at: insertTime) try! compositionAudioTrack?.insertTimeRange(timeRangeVideo, of: trackAudio, at: insertTime) insertTime = CMTimeAdd(insertTime, duration) } return mainComposition } /// Combines all recorded clips into one file func mergeVideo(_ documentDirectory: URL, filename: String, clips: [URL], completion: @escaping (Bool, URL?) -> Void) { var assets: [AVAsset] = [] var totalDuration = CMTime.zero for clip in clips { let asset = AVAsset(url: clip) assets.append(asset) totalDuration = CMTimeAdd(totalDuration, asset.duration) } let mixComposition = merge(recordedVideos: assets) let url = documentDirectory.appendingPathComponent("link_\(filename)") guard let exporter = AVAssetExportSession(asset: mixComposition, presetName: AVAssetExportPresetHighestQuality) else { return } exporter.outputURL = url exporter.outputFileType = .mp4 exporter.shouldOptimizeForNetworkUse = true exporter.exportAsynchronously { DispatchQueue.main.async { if exporter.status == .completed { completion(true, exporter.outputURL) } else { completion(false, nil) } } } } }Step 6: Metadata for the videos
There is a specific set of actions for video uploading:
- Recording a video
- Using your token and the name of the future video, creating a request to the server to create a container for the video file
- Getting the usual VOD data in the response
- Sending a request for metadata using the token and the VOD ID
- Getting metadata in the response
- Uploading the video via TUSKit using metadata
Create requests with models. You will use the Decodable protocol from Apple with the enumeration of Coding Keys for easier data parsing.
1. Create a model for VOD, which will contain the data that you need.
struct VOD: Decodable { let name: String let id: Int let screenshot: URL? let hls: URL? enum CodingKeys: String, CodingKey { case name, id, screenshot case hls = "hls_url" } }2. Create a CreateVideoRequest in order to create an empty container for the video on the server. The VOD model will come in response.
struct CreateVideoRequest: DataRequest { typealias Response = VOD let token: String let videoName: String var url: String { GсoreAPI.videos.rawValue } var method: HTTPMethod { .post } var headers: [String: String] { [ "Authorization" : "Bearer \(token)" ] } var body: Data? { try? JSONEncoder().encode([ "name": videoName ]) } }3. Create a VideoMetadata model that will contain data for uploading videos from the device to the server and the corresponding request for it.
struct VideoMetadata: Decodable { struct Server: Decodable { let hostname: String } struct Video: Decodable { let name: String let id: Int let clientID: Int enum CodingKeys: String, CodingKey { case name, id case clientID = "client_id" } } let servers: [Server] let video: Video let token: String var uploadURLString: String { "https://" + (servers.first?.hostname ?? "") + "/upload" } } // MARK: Request struct VideoMetadataRequest: DataRequest { typealias Response = VideoMetadata let token: String let videoId: Int var url: String { GсoreAPI.videos.rawValue + "/\(videoId)/" + "upload" } var method: HTTPMethod { .get } var headers: [String: String] { [ "Authorization" : "Bearer \(token)" ] } }Step 7: Putting the pieces together
We’ve used the code from our demo application as an example. The controller class is described here with a custom view. It will link the camera and the UI as well as take responsibility for creating requests to obtain metadata and then upload the video to the server.
Create View Controller. It will display the camera view and TextField for the video title. This controller has various states (upload, error, common).
MainView
First, create the view.
1. Create a delegate protocol to handle changing the name of the video.
protocol UploadMainViewDelegate: AnyObject { func videoNameDidUpdate(_ name: String) }2. Create the view and initialize all UI elements except the camera view. It will be added by the controller.
final class UploadMainView: UIView { enum State { case upload, error, common } var cameraView: CameraView? { didSet { initLayoutForCameraView() } } var state: State = .common { didSet { switch state { case .upload: showUploadState() case .error: showErrorState() case .common: showCommonState() } } } weak var delegate: UploadMainViewDelegate? }3. Add the initialization of UI elements here, except for the camera view. It will be added by the controller.
let videoNameTextField = TextField(placeholder: "Enter the name video") let accessCaptureFailLabel: UILabel = { let label = UILabel() label.text = NSLocalizedString("Error!\nUnable to access capture devices.", comment: "") label.textColor = .black label.numberOfLines = 2 label.isHidden = true label.textAlignment = .center return label }() let uploadIndicator: UIActivityIndicatorView = { let indicator = UIActivityIndicatorView(style: .gray) indicator.transform = CGAffineTransform(scaleX: 2, y: 2) return indicator }() let videoIsUploadingLabel: UILabel = { let label = UILabel() label.text = NSLocalizedString("video is uploading", comment: "") label.font = UIFont.systemFont(ofSize: 16) label.textColor = .gray label.isHidden = true return label }()4. Create a layout for the elements. Since the camera will be added after, its layout is taken out in a separate method.
private func initLayoutForCameraView() { guard let cameraView = cameraView else { return } cameraView.translatesAutoresizingMaskIntoConstraints = false insertSubview(cameraView, at: 0) NSLayoutConstraint.activate([ cameraView.leftAnchor.constraint(equalTo: leftAnchor), cameraView.topAnchor.constraint(equalTo: topAnchor), cameraView.rightAnchor.constraint(equalTo: rightAnchor), cameraView.bottomAnchor.constraint(equalTo: videoNameTextField.topAnchor), ]) } private func initLayout() { let views = [videoNameTextField, accessCaptureFailLabel, uploadIndicator, videoIsUploadingLabel] views.forEach { $0.translatesAutoresizingMaskIntoConstraints = false addSubview($0) } let keyboardBottomConstraint = videoNameTextField.bottomAnchor.constraint(equalTo: layoutMarginsGuide.bottomAnchor) self.keyboardBottomConstraint = keyboardBottomConstraint NSLayoutConstraint.activate([ keyboardBottomConstraint, videoNameTextField.heightAnchor.constraint(equalToConstant: videoNameTextField.intrinsicContentSize.height + 20), videoNameTextField.leftAnchor.constraint(equalTo: leftAnchor), videoNameTextField.rightAnchor.constraint(equalTo: rightAnchor), accessCaptureFailLabel.centerYAnchor.constraint(equalTo: centerYAnchor), accessCaptureFailLabel.centerXAnchor.constraint(equalTo: centerXAnchor), uploadIndicator.centerYAnchor.constraint(equalTo: centerYAnchor), uploadIndicator.centerXAnchor.constraint(equalTo: centerXAnchor), videoIsUploadingLabel.centerXAnchor.constraint(equalTo: centerXAnchor), videoIsUploadingLabel.topAnchor.constraint(equalTo: uploadIndicator.bottomAnchor, constant: 20) ]) }5. To show different states, create methods responsible for this.
private func showUploadState() { videoNameTextField.isHidden = true uploadIndicator.startAnimating() videoIsUploadingLabel.isHidden = false accessCaptureFailLabel.isHidden = true cameraView?.recordButton.setImage(UIImage(named: "play.icon"), for: .normal) cameraView?.isHidden = true } private func showErrorState() { accessCaptureFailLabel.isHidden = false videoNameTextField.isHidden = true uploadIndicator.stopAnimating() videoIsUploadingLabel.isHidden = true cameraView?.isHidden = true } private func showCommonState() { videoNameTextField.isHidden = false uploadIndicator.stopAnimating() videoIsUploadingLabel.isHidden = true accessCaptureFailLabel.isHidden = true cameraView?.isHidden = false }6. Add methods and a variable for the correct processing of keyboard behavior. The video title input field must always be visible.
private var keyboardBottomConstraint: NSLayoutConstraint? private func addObserver() { [UIResponder.keyboardWillShowNotification, UIResponder.keyboardWillHideNotification].forEach { NotificationCenter.default.addObserver( self, selector: #selector(keybordChange), name: $0, object: nil ) } } @objc private func keybordChange(notification: Notification) { guard let keyboardFrame = notification.userInfo?["UIKeyboardFrameEndUserInfoKey"] as? NSValue, let duration = notification.userInfo?[UIResponder.keyboardAnimationDurationUserInfoKey] as? Double else { return } let keyboardHeight = keyboardFrame.cgRectValue.height - safeAreaInsets.bottom if notification.name == UIResponder.keyboardWillShowNotification { self.keyboardBottomConstraint?.constant -= keyboardHeight UIView.animate(withDuration: duration) { self.layoutIfNeeded() } } else { self.keyboardBottomConstraint?.constant += keyboardHeight UIView.animate(withDuration: duration) { self.layoutIfNeeded() } } }7. Rewrite the initializer. In deinit, unsubscribe from notifications related to the keyboard.
override init(frame: CGRect) { super.init(frame: frame) initLayout() backgroundColor = .white videoNameTextField.delegate = self addObserver() } required init?(coder: NSCoder) { super.init(coder: coder) initLayout() backgroundColor = .white videoNameTextField.delegate = self addObserver() } deinit { NotificationCenter.default.removeObserver(self) }8. Sign the view under UITextFieldDelegate to intercept the necessary actions related to TextField.
extension UploadMainView: UITextFieldDelegate { func textFieldShouldReturn(_ textField: UITextField) -> Bool { delegate?.videoNameDidUpdate(textField.text ?? "") return textField.resignFirstResponder() } func textField(_ textField: UITextField, shouldChangeCharactersIn range: NSRange, replacementString string: String) -> Bool { guard let text = textField.text, text.count < 21 else { return false } return true } }Controller
Create ViewController.
1. Specify the necessary variables and configure the controller.
final class UploadController: BaseViewController { private let mainView = UploadMainView() private var camera: Camera? private var captureSession = AVCaptureSession() private var filename = "" private var writingVideoURL: URL! private var clips: [(URL, CMTime)] = [] { didSet { mainView.cameraView?.clipsLabel.text = "Clips: \(clips.count)" } } private var isUploading = false { didSet { mainView.state = isUploading ? .upload : .common } } // replacing the default view with ours override func loadView() { mainView.delegate = self view = mainView } // initialize the camera and the camera view override func viewDidLoad() { super.viewDidLoad() do { camera = try Camera(captureSession: captureSession) camera?.delegate = self mainView.cameraView = CameraView(session: captureSession) mainView.cameraView?.delegate = self } catch { debugPrint((error as NSError).description) mainView.state = .error } } }2. Add methods that will respond to clicks of the upload button on View. For this, create a full video from small fragments, create an empty container on the server, get metadata, and then upload the video.
// used then user tap upload button private func mergeSegmentsAndUpload() { guard !isUploading, let camera = camera else { return } isUploading = true camera.stopRecording() if let directoryURL = FileManager.default.urls(for: .documentDirectory, in: .userDomainMask).first { let clips = clips.map { $0.0 } // Create a full video from clips VideoCompositionWriter().mergeVideo(directoryURL, filename: "\(filename).mp4", clips: clips) { [weak self] success, outURL in guard let self = self else { return } if success, let outURL = outURL { clips.forEach { try? FileManager.default.removeItem(at: $0) } self.clips = [] let videoData = try! Data.init(contentsOf: outURL) let writingURL = FileManager.default.temporaryDirectory.appendingPathComponent(outURL.lastPathComponent) try! videoData.write(to: writingURL) self.writingVideoURL = writingURL self.createVideoPlaceholderOnServer() } else { self.isUploading = false self.mainView.state = .common self.present(self.createAlert(), animated: true) } } } } // used to send createVideo request private func createVideoPlaceholderOnServer() { guard let token = Settings.shared.accessToken else { refreshToken() return } let http = HTTPCommunicator() let request = CreateVideoRequest(token: token, videoName: filename) http.request(request) { [weak self] result in guard let self = self else { return } switch result { case .success(let vod): self.loadMetadataFor(vod: vod) case .failure(let error): if let error = error as? ErrorResponse, error == .invalidToken { Settings.shared.accessToken = nil self.refreshToken() } else { self.errorHandle(error) } } } } // Requesting the necessary data from the server func loadMetadataFor(vod: VOD) { guard let token = Settings.shared.accessToken else { refreshToken() return } let http = HTTPCommunicator() let request = VideoMetadataRequest(token: token, videoId: vod.id) http.request(request) { [weak self] result in guard let self = self else { return } switch result { case .success(let metadata): self.uploadVideo(with: metadata) case .failure(let error): if let error = error as? ErrorResponse, error == .invalidToken { Settings.shared.accessToken = nil self.refreshToken() } else { self.errorHandle(error) } } } } // Uploading our video to the server via TUSKit func uploadVideo(with metadata: VideoMetadata) { var config = TUSConfig(withUploadURLString: metadata.uploadURLString) config.logLevel = .All TUSClient.setup(with: config) TUSClient.shared.delegate = self let upload: TUSUpload = TUSUpload(withId: filename, andFilePathURL: writingVideoURL, andFileType: ".mp4") upload.metadata = [ "filename" : filename, "client_id" : String(metadata.video.clientID), "video_id" : String(metadata.video.id), "token" : metadata.token ] TUSClient.shared.createOrResume(forUpload: upload) }3. Subscribe to the TUSDelegate protocol to track errors and successful downloads. It can also be used to display the progress of video downloads.
//MARK: - TUSDelegate extension UploadController: TUSDelegate { func TUSProgress(bytesUploaded uploaded: Int, bytesRemaining remaining: Int) { } func TUSProgress(forUpload upload: TUSUpload, bytesUploaded uploaded: Int, bytesRemaining remaining: Int) { } func TUSFailure(forUpload upload: TUSUpload?, withResponse response: TUSResponse?, andError error: Error?) { if let error = error { print((error as NSError).description) } present(createAlert(), animated: true) mainView.state = .common } func TUSSuccess(forUpload upload: TUSUpload) { let alert = createAlert(title: "Upload success") present(alert, animated: true) mainView.state = .common } }4. Subscribe to the protocols of the MainView, the camera, and the camera view in order to correctly link all the work of the module.
//MARK: - extensions CameraViewDelegate, CameraDelegate extension UploadController: CameraViewDelegate, CameraDelegate { func updateCurrentRecordedTime(_ time: CMTime) { currentRecordedTime = time.seconds } func tappedDeleteClip() { guard let lastClip = clips.last else { return } lastRecordedTime -= lastClip.1.seconds clips.removeLast() } func addRecordedMovie(url: URL, time: CMTime) { lastRecordedTime += time.seconds clips += [(url, time)] } func shouldRecord() -> Bool { totalRecordedTime < maxRecordTime } func tappedRecord(isRecord: Bool) { isRecord ? camera?.startRecording() : camera?.stopRecording() } func tappedUpload() { guard !clips.isEmpty && filename != "" else { return } mergeSegmentsAndUpload() } func tappedFlipCamera() { camera?.flipCamera() } } extension UploadController: UploadMainViewDelegate { // used then user change name video in view func videoNameDidUpdate(_ name: String) { filename = name } This was the last step; the job is done! The new feature has been added to your app and configured.
Result
Now you have a full-fledged module for recording and uploading videos.

Conclusion
Through this guide, you’ve learned how to add a VOD uploading feature to your iOS application. We hope this solution will satisfy your needs and delight your users with new options.
Also, we invite you to take a look at our demo application. You will see the result of setting up the VOD viewing for an iOS project.

Related articles


At Gcore, delivering exceptional streaming experiences to users across our global network is at the heart of what we do. We're excited to share how we're taking our CDN performance monitoring to new heights through our partnership with AVEQ

As streaming demand surges worldwide, providers face mounting pressure to deliver high-quality video without buffering, lag, or quality dips, no matter where the viewer is or what device they're using. That pressure is only growing as audie

Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.