Developers
Discover the latest industry trends, get ahead with cutting‑edge insights, and be in the know about the newest Gcore innovations.
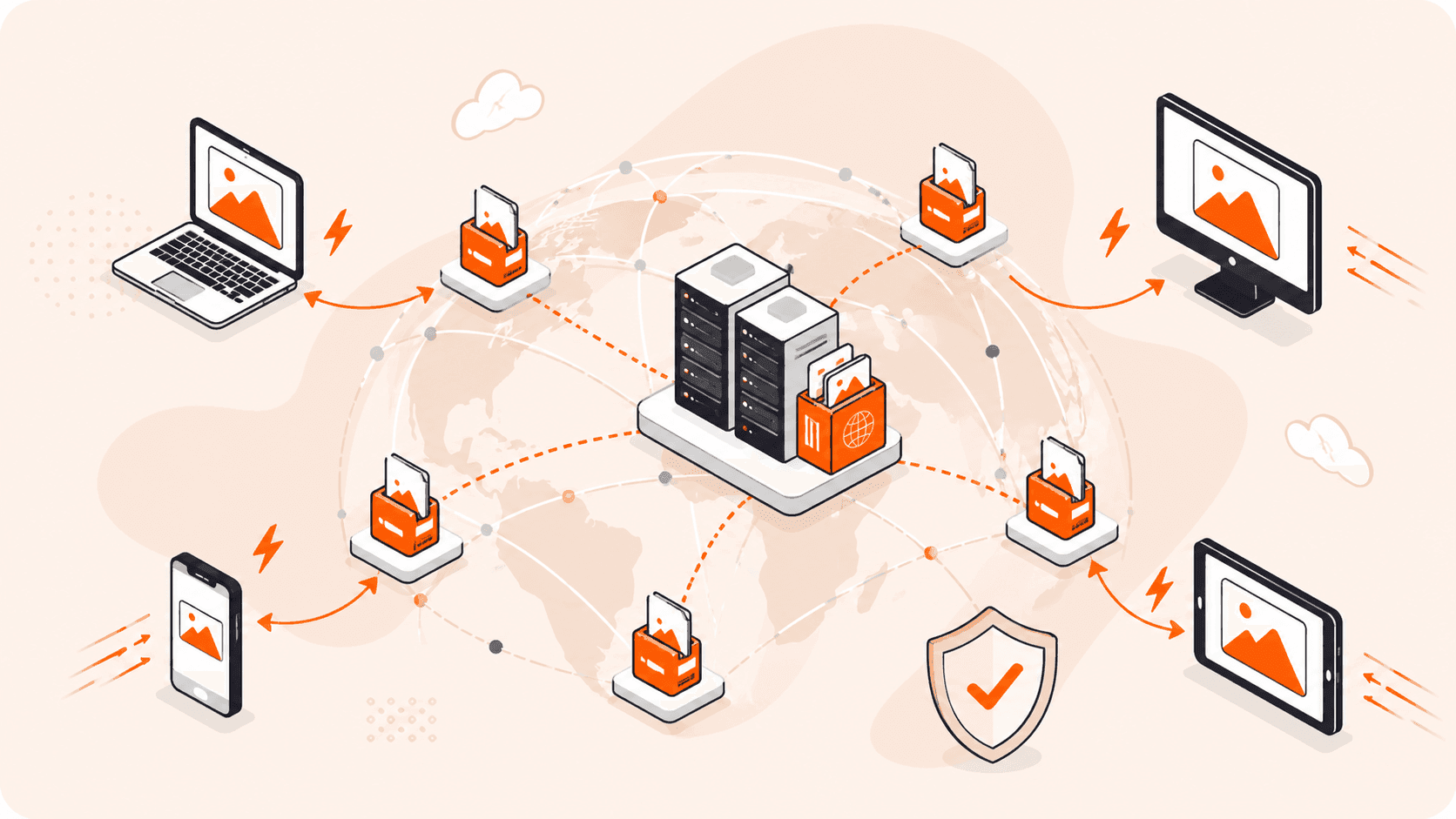
Every second of load time costs you. During a traffic spike, an uncached origin server can buckle under the pressure, and CDN caching can offload 70% to 90% of that traffic before it ever reaches your Gcore infrastructure. For a user in New
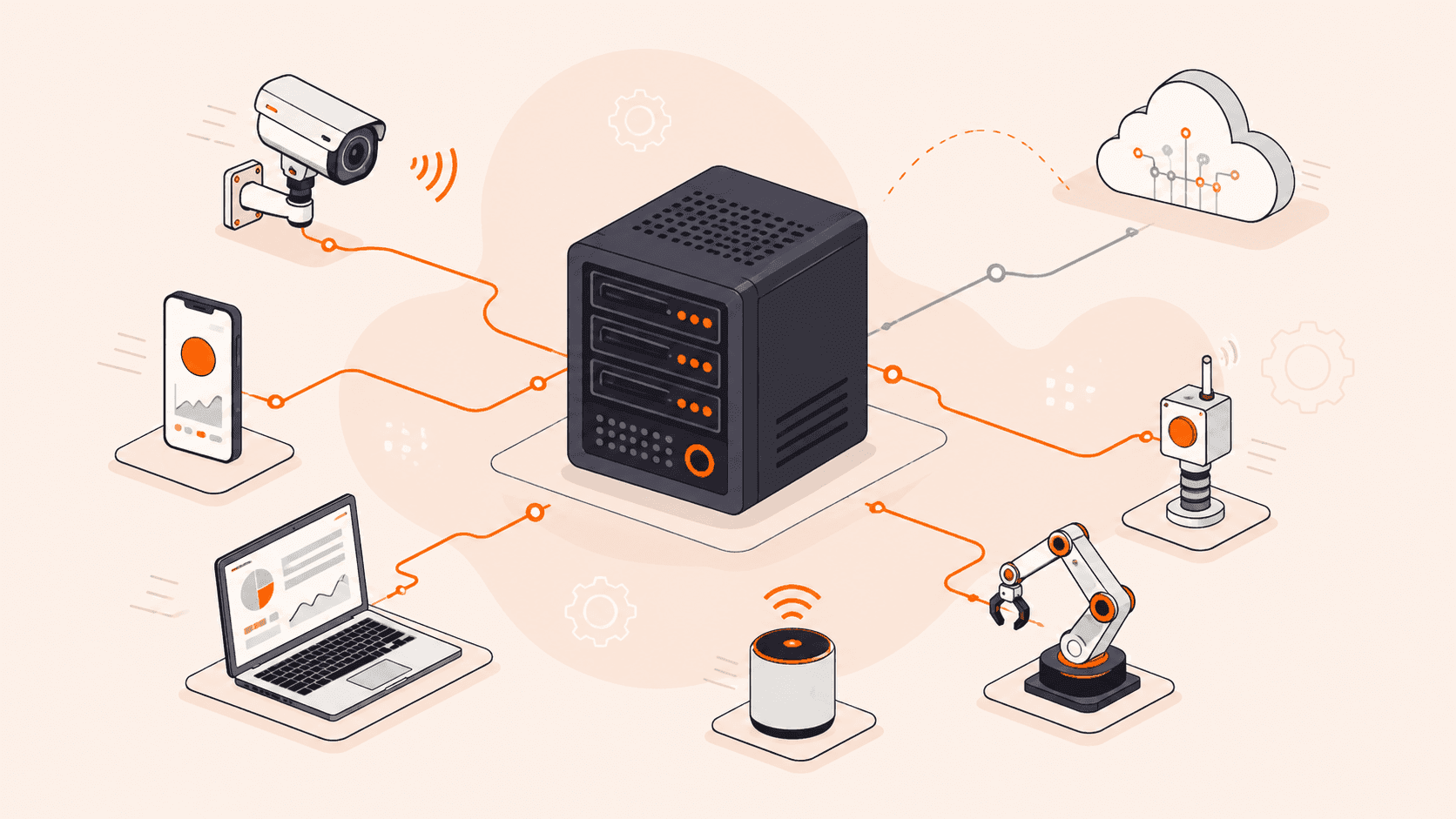
Picture an autonomous vehicle doing 70 mph on the highway, waiting on a response from a data center hundreds of miles away. Or a surgeon depending on real-time imaging that freezes mid-procedure because data has to make a round trip across
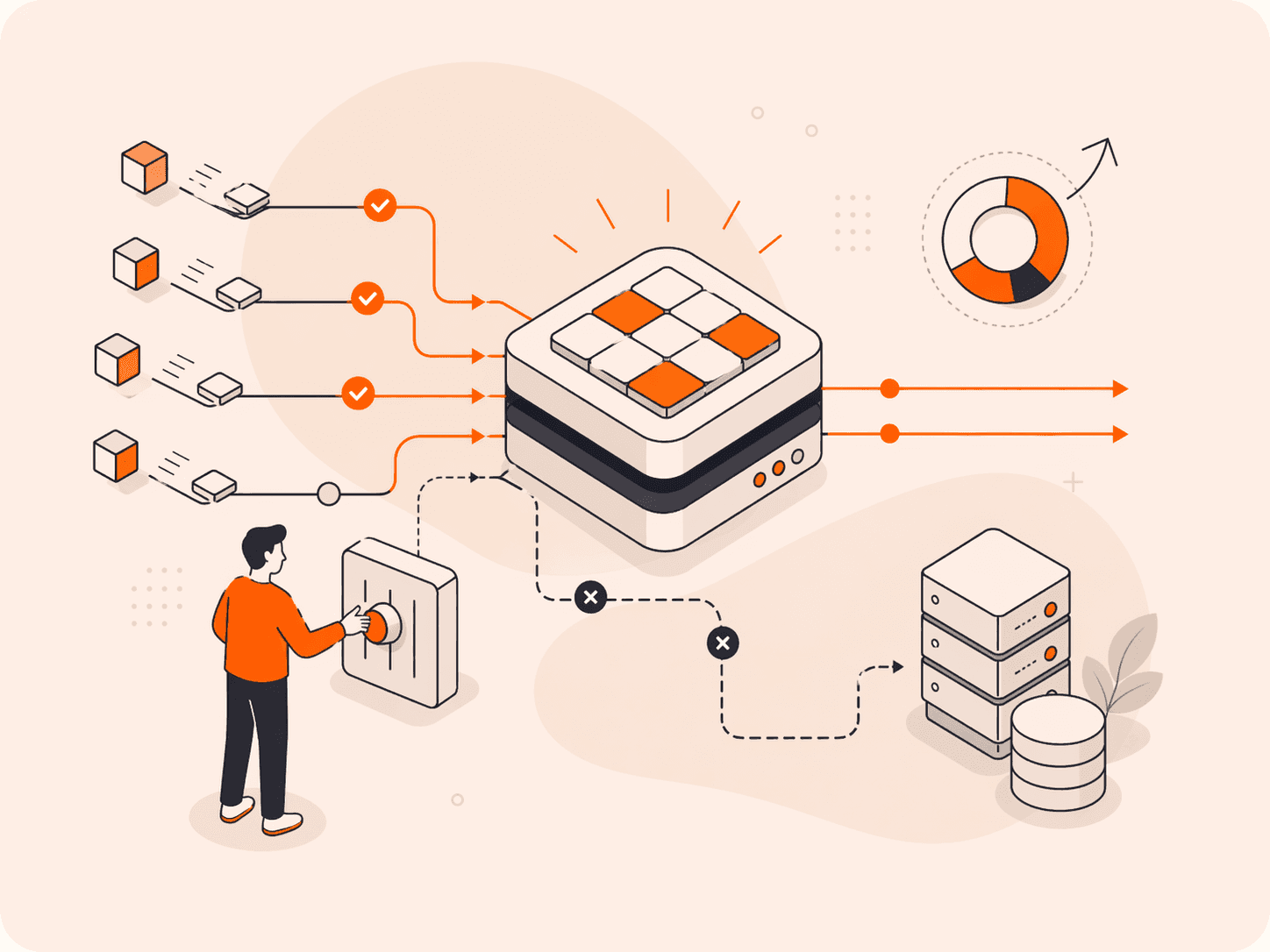
Every cache miss is a trip your server didn't need to make. And those trips add up fast. Sites with poorly optimized caching can see cache hit ratios as low as 70%, meaning three in 10 requests are hitting your origin server directly, dragg

Every minute your servers are down, your business is bleeding. For e-commerce sites, healthcare platforms, and revenue-critical applications, an outage isn't just an inconvenience. It's a direct hit to your bottom line, your reputation, and

Your server choice could be quietly costing you, or quietly holding you back. Pick the wrong infrastructure for your workload and you're either overpaying for idle hardware every month or watching your site buckle under traffic spikes you c

Your site is humming along fine, until it isn't. Traffic spikes, page loads crawl, and your hosting plan buckles under pressure right when it matters most. Choosing between a VPS and a dedicated server isn't just a technical checkbox. It's
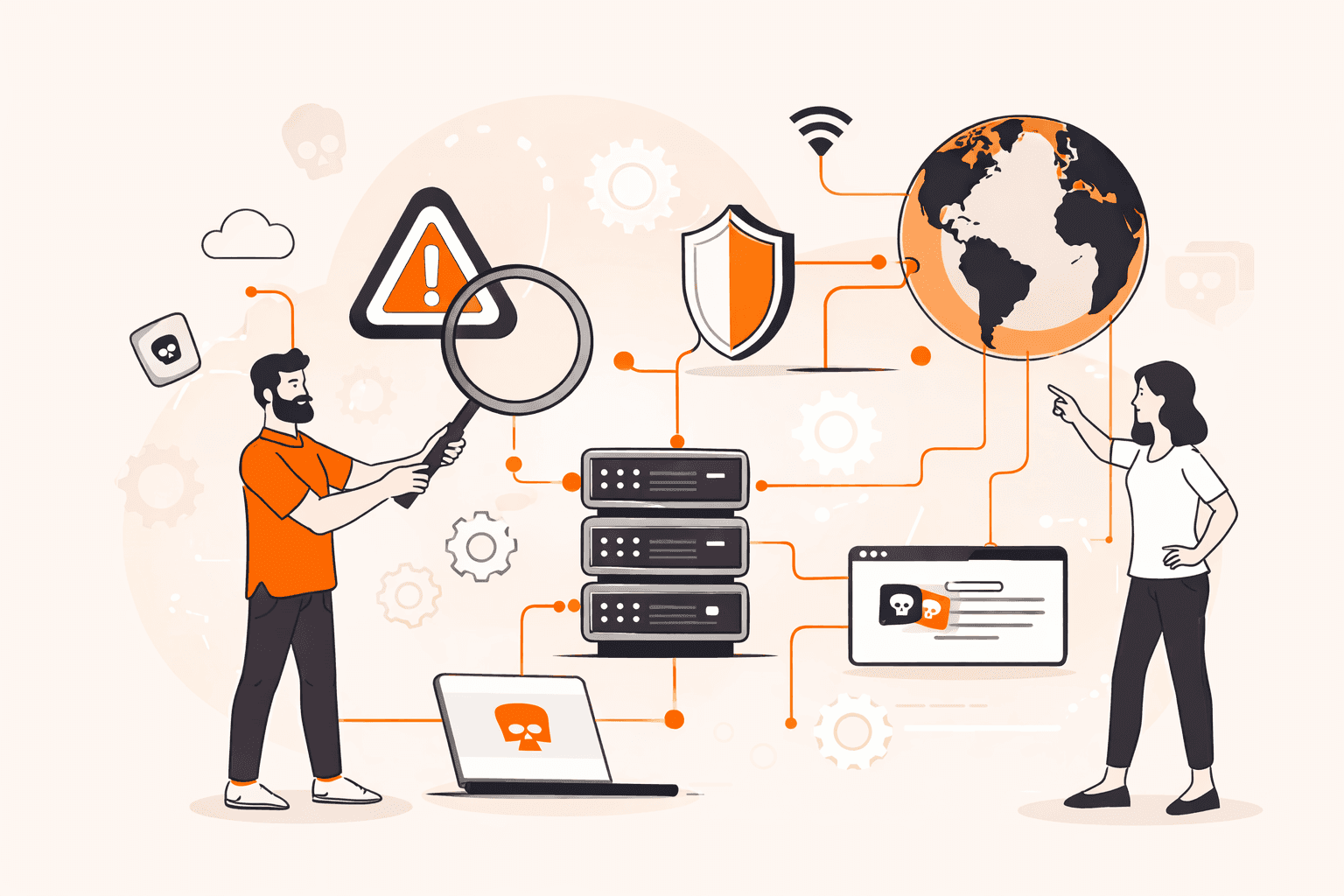
Your website stops loading. Email bounces back. Users can't access your application. The culprit? A DNS failure that's invisible to most monitoring tools but devastating to your operations. When DNS breaks, every service that depends on it
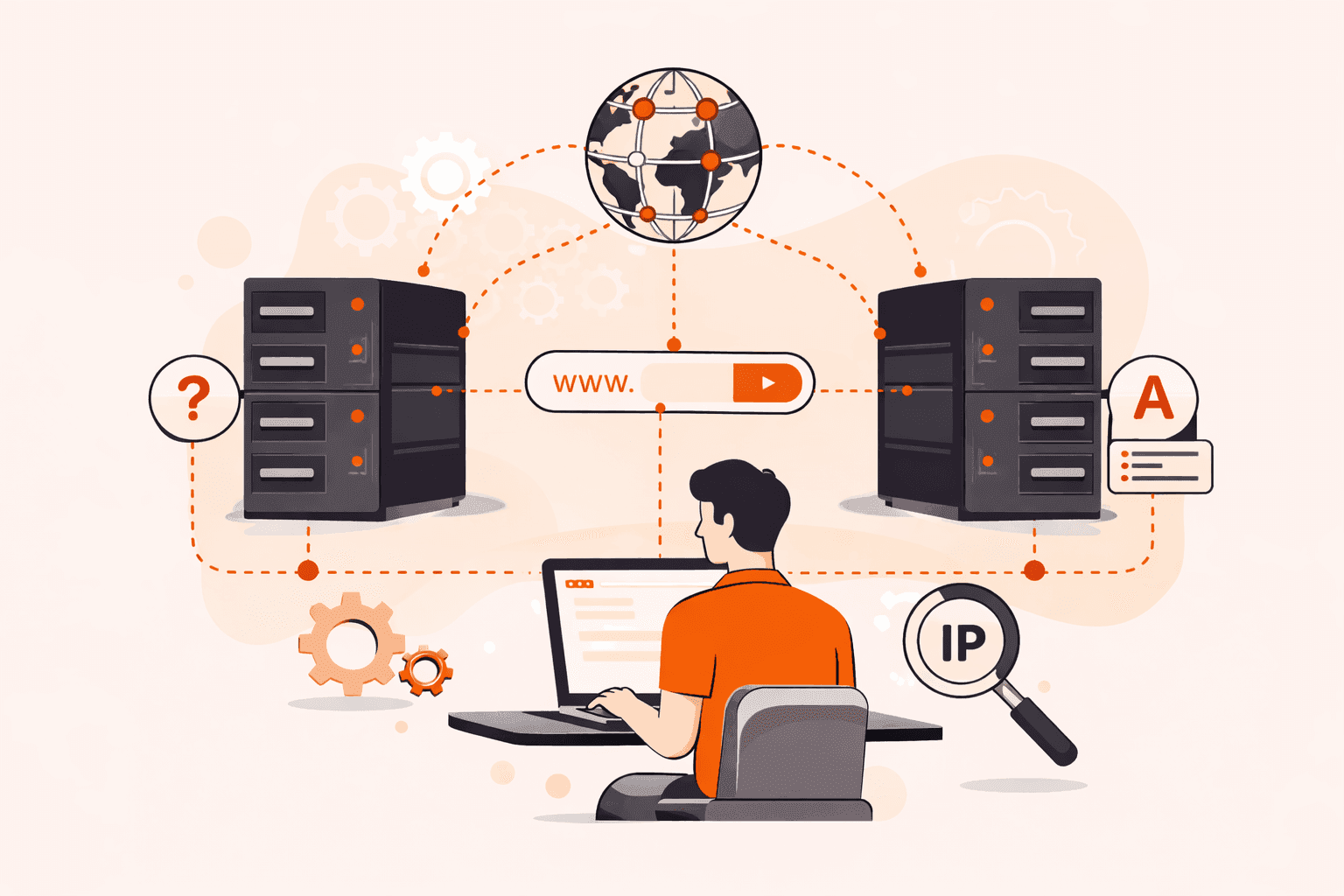
Every time you type a website address into your browser, an invisible infrastructure processes your request in milliseconds, and it's handling billions of these lookups every single day. Without this system, you'd need to memorize strings o
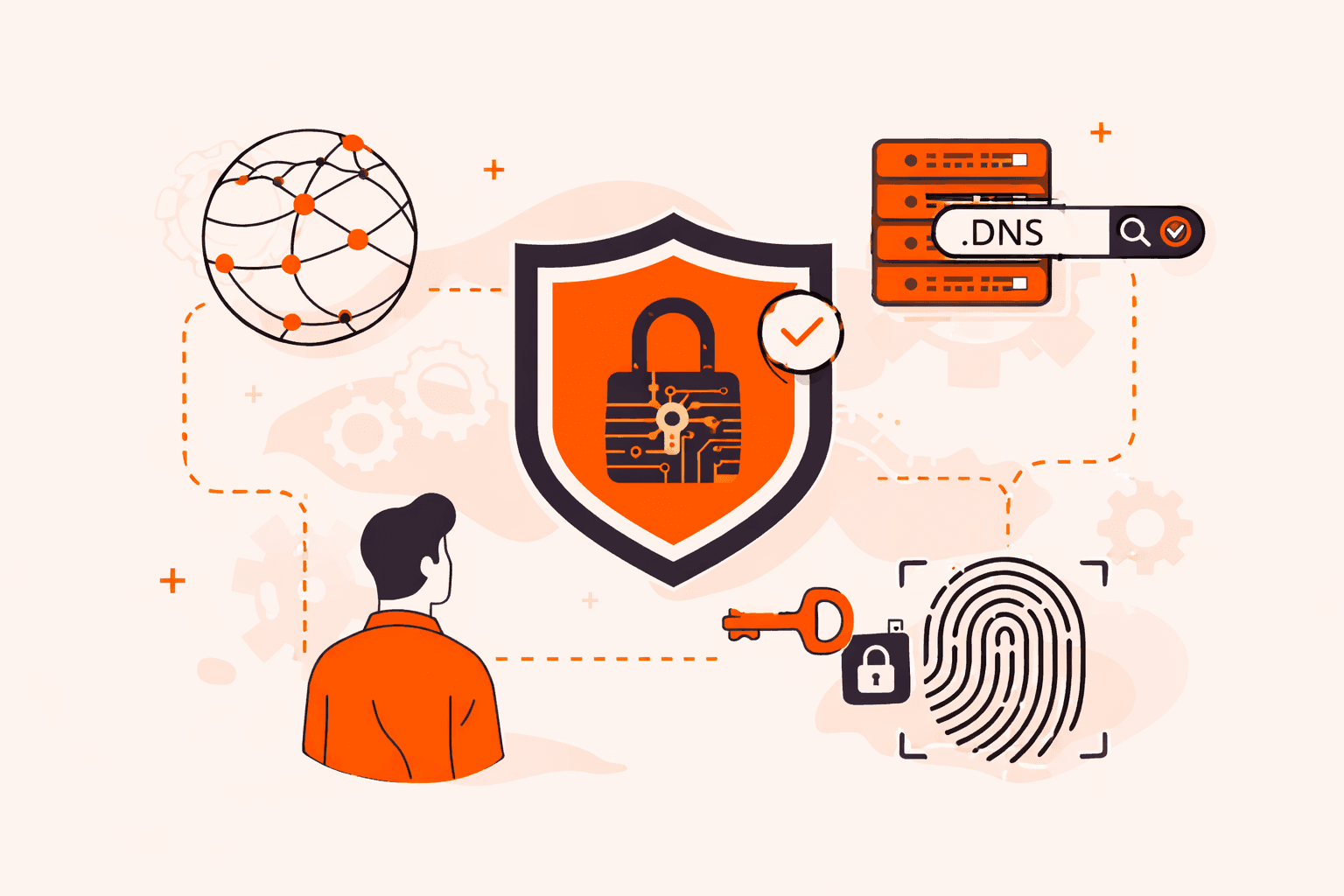
Your DNS queries get hijacked. Users land on fake versions of your website. Credentials get stolen before you even know you're under attack. DNS cache poisoning and spoofing attacks exploit a fundamental vulnerability: the Domain Name Syste

Your cloud provider goes down. Applications fail. Customers can't access your services. And because you've built everything around a single vendor, there's nothing you can do but wait. For organizations locked into one cloud platform, this

Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial
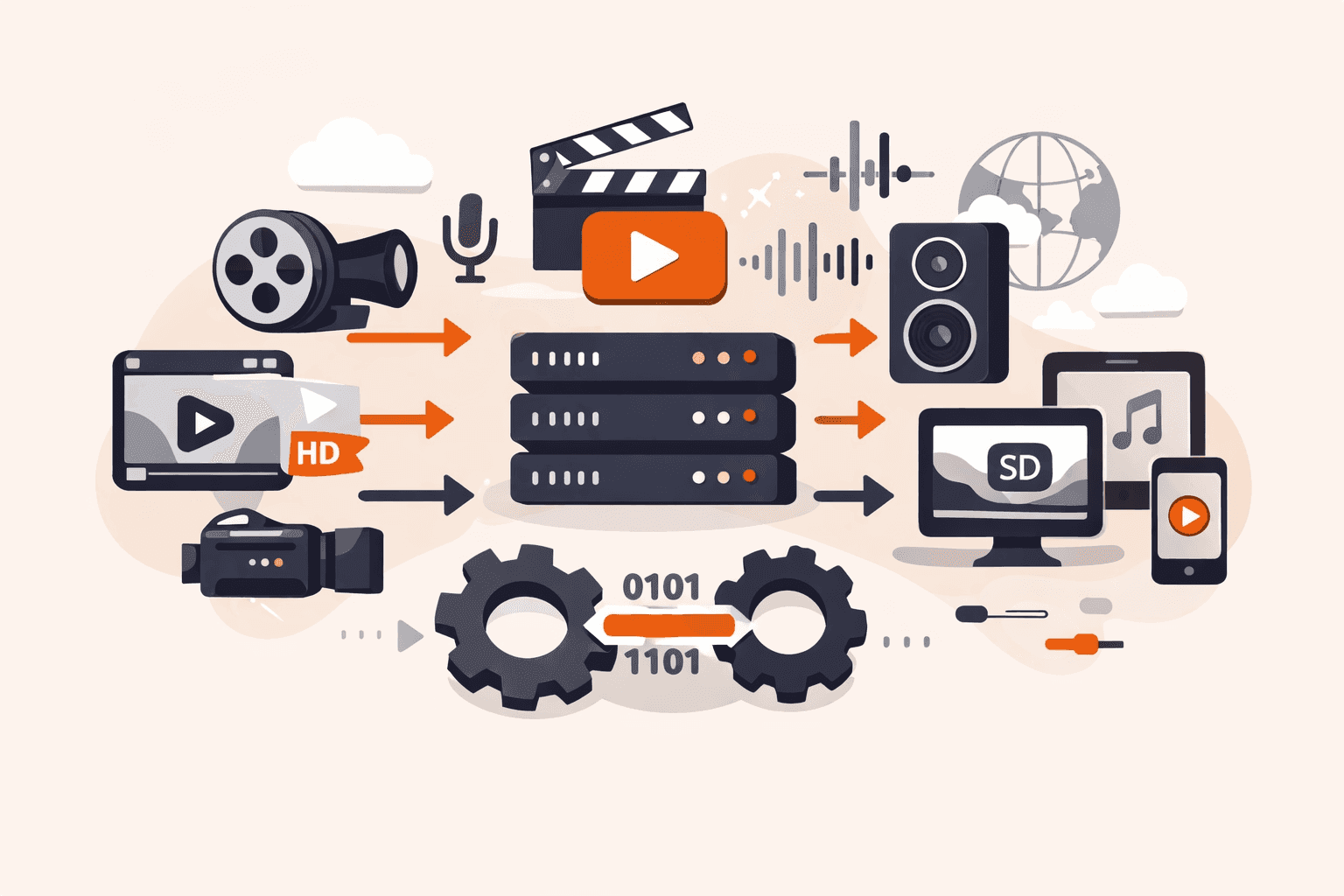
You're watching a video on your phone during your commute when it suddenly buffers, pixelates, and freezes, despite having full bars. Meanwhile, your friend streams the same content flawlessly on their laptop at home. Behind the scenes, str

Picture this: a foreign government issues a legal order forcing your cloud provider to hand over sensitive patient records, classified research data, or critical national infrastructure details. You can't stop it. This isn't hypothetical. G
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.