
Kubernetes ist eine beliebte Plattform zur Container-Orchestrierung, mit der Sie Ihre Anwendungscontainer effizient verwalten können. Mit den Autoskalierungsfunktionen von Kubernetes kann Software skalieren, um sich an die durch Benutzer veränderte Arbeitslast anzupassen. Dies bietet Vorteile wie eine optimale Ressourcennutzung, Kosteneffizienz und die ununterbrochene Verfügbarkeit Ihrer Anwendungen. Der Einstieg kann allerdings eine Herausforderung sein. In diesem Artikel erklären wir Ihnen, wie die automatische Skalierung von Kubernetes funktioniert und wie Sie die automatische Skalierung für Ihre Kubernetes-Pods und Kubernetes-Knoten anwenden, damit Sie von den Vorteilen profitieren können.
Was ist Kubernetes Autoscaling?
Kubernetes Autoscaling ist eine dynamische Funktion innerhalb des Kubernetes-Container-Orchestrierungssystems, die die Rechenressourcen automatisch an den Bedarf der Arbeitslast anpasst. Dies trägt dazu bei, die Anwendungsleistung aufrechtzuerhalten und finanzielle Einbußungen zu vermeiden, indem die Ressourcenzuweisung ausgeglichen und optimiert wird. Traffic-Spitzen werden durch zusätzliche Ressourcen bewältigt, um eine optimale Performance zu gewährleisten, und in Leerlaufzeiten werden weniger Ressourcen eingesetzt, um Geld zu sparen.
Die automatische Skalierung von Kubernetes gewährleistet eine optimale Ressourcennutzung, Kosteneffizienz und die ununterbrochene Verfügbarkeit Ihrer Anwendungen. Jeder, der Kubernetes einsetzt, kann von der automatischen Skalierung profitieren, insbesondere wenn Ihre Anwendung Phasen mit hoher Arbeitslast aber auch Leerlaufzeiten hat.
Wie funktioniert Kubernetes Autoscaling?
Im Allgemeinen funktioniert die automatische Skalierung von Kubernetes wie jede andere Art der automatischen Skalierung: Sie passt die Serverressourcen dynamisch an die von den Endbenutzern erzeugte aktuelle Arbeitslast an.

Der Autoscaler ist für die Skalierung der Rechenressourcen zur Anpassung an die von den Benutzern erzeugte Arbeitslast verantwortlich. Schauen wir uns an, wie das Ganze funktioniert, wenn die Arbeitslast steigt. Es gibt zwei Möglichkeiten, das System zu skalieren: hochskalieren und herausskalieren. Beim Hochskalieren fügen Sie dem bestehenden Server mehr Systemressourcen hinzu, z. B. mehr RAM, CPUs oder Festplatten. Beim Herausskalieren fügen Sie dem vorhandenen Server nicht direkt Systemressourcen hinzu, sondern weitere Server. Dadurch verfügt Ihr System über mehr Ressourcen, um den wachsenden Benutzer-Traffic zu bewältigen. Wenn die Arbeitslast abnimmt, skaliert das System nach unten (entgegengesetzt zum Hochskalieren) oder nach innen (entgegengesetzt zum Herausskalieren).
Skalierung von Pods und Knoten
Die automatische Skalierung in Kubernetes funktioniert auf zwei Ebenen: Pod- und Knotenebene. Auf Podebene geht es dabei um die Anpassung der Anzahl der Pod-Replikate (horizontale Autoskalierung) oder der Ressourcen eines einzelnen Pods (vertikale Autoskalierung). Auf Knotenebene – bekannt als Cluster-Autoskalierung – geht es um das Hinzufügen oder Entfernen von Knoten innerhalb des Clusters.
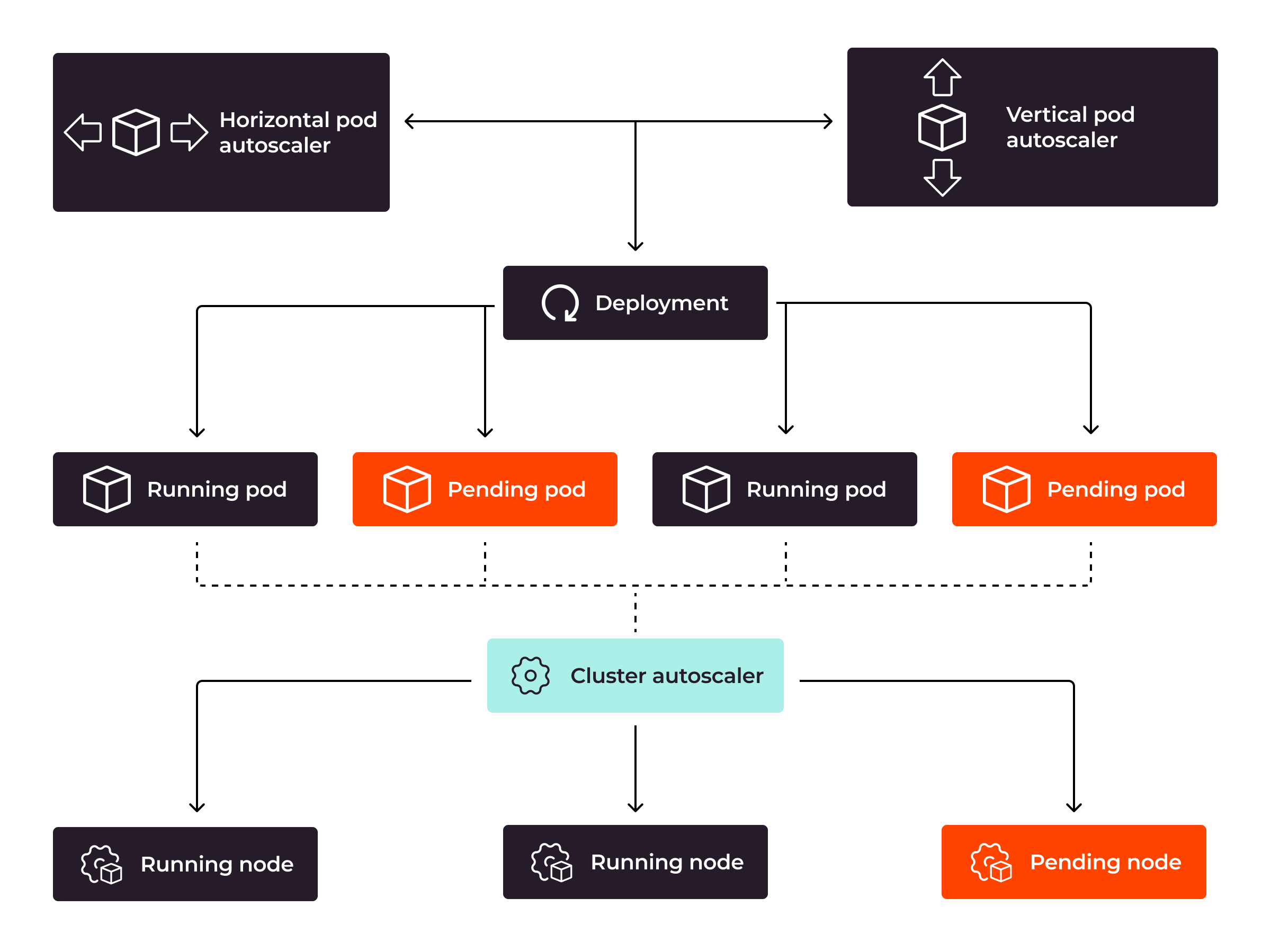
Wenn Kubernetes feststellt, dass der aktuelle Pod die Arbeitslast nicht bewältigen kann, skaliert es die Pods mithilfe von HPA (Horizontal Pod Autoscaler) oder VPA (Vertical Pod Autoscaler), je nachdem, welche Befehle es erhalten hat. Wenn Sie die Pods mit HPA herausskalieren, erstellt Kubernetes weitere Pods. Wenn Sie die Pods mit VPA hochskalieren, fügt Kubernetes dem Pod mehr Systemressourcen hinzu. Wenn Kubernetes die Pods aufgrund unzureichender Ressourcen der vorhandenen Knoten nicht skalieren kann, fügt die Cluster-Autoscaler-Komponente dem Kubernetes-Cluster automatisch weitere Knoten hinzu. Dadurch kann Kubernetes die Pods weiter skalieren, um die Arbeitslast effizienter zu bewältigen, selbst bei extremer Arbeitslast.
Autoscaling für einen Kubernetes-Cluster sollte auf die Kubernetes-Pods und auf die Kubernetes-Knoten angewendet werden. Wenn die aktuellen Kubernetes-Knoten nicht genügend Ressourcen haben, um sie den Pods zuzuweisen, spielt es keine Rolle, wie viele Pods Kubernetes hochskaliert hat, um Benutzeranfragen zu bearbeiten. Als Resultat werden Ihre Benutzer weiterhin mit einer schlechten Anwendungsleistung konfrontiert – oder sogar mit der Nichterreichbarkeit der Anwendung.
Implementierung von Autoscaling für Kubernetes-Pods
Es gibt drei Möglichkeiten, Kubernetes Pod Autoscaling zu implementieren:
- Vertical Autoscaling mit Hilfe von Kubernetes Autoscaler GitHub Repository.
- Horizontales Autoscaling mit der integrierten Unterstützung von Kubernetes.
- Kubernetes event-driven Autoscaling (KEDA) zur Skalierung der Pods nach Events.
Vertikale Autoskalierung
Vertikale Autoskalierung in Kubernetes bedeutet, dass die Kapazität eines Pods je nach Bedarf angepasst wird.
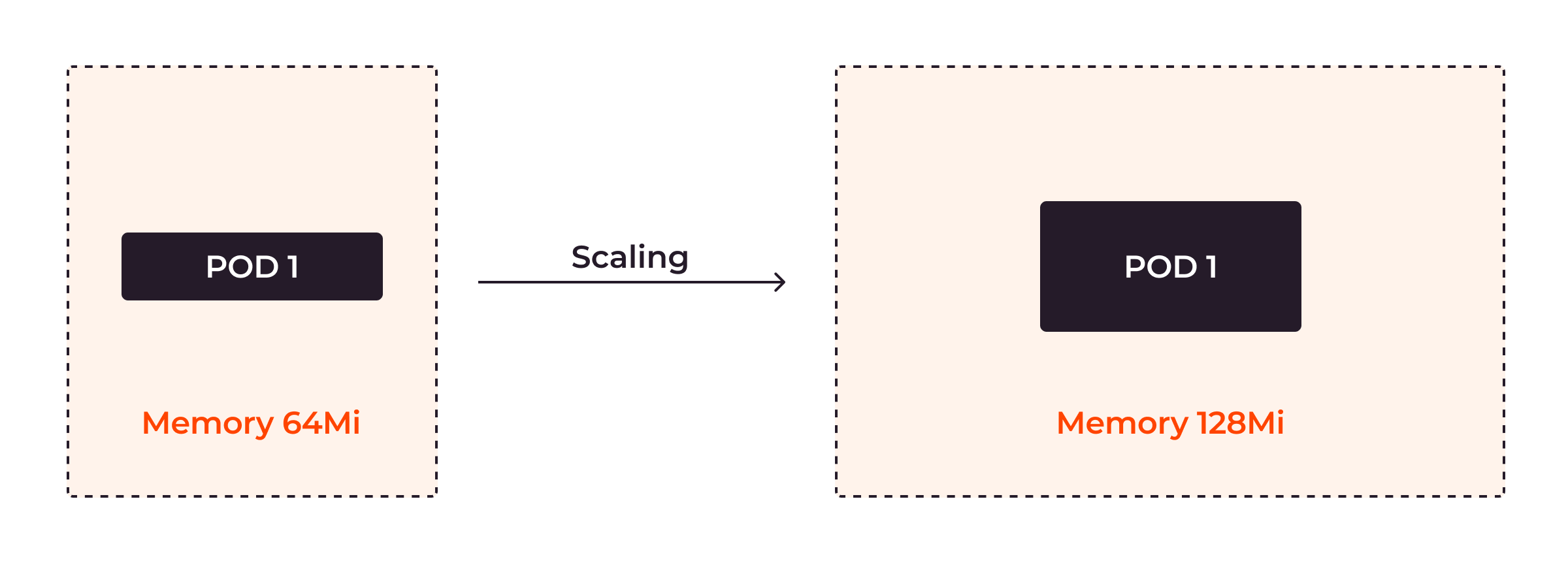
Installieren Sie zunächst den VPA.
git clone https://github.com/kubernetes/autoscaler.git cd autoscaler ./hack/vpa-up.sh
Mit dem VPA können Sie den Minimal- und Maximalwert der CPU- und Speichernutzung für die Pods konfigurieren, sodass die Ressourcennutzung der Pods garantiert zwischen den Minimal- und Maximalwerten liegt.
apiVersion: "autoscaling.k8s.io/v1"
kind: VerticalPodAutoscaler
metadata:
name: example-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: example
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 50Mi
maxAllowed:
cpu: 1
memory: 500Mi
controlledResources: ["cpu", "memory"]
In der obigen Konfiguration weisen Sie Kubernetes an, die CPU-Auslastung des Pods im Bereich von 100 millicpu (10 % des Kerns) bis 1 Kern festzulegen. Der Speicherbedarf des Pods liegt zwischen 50–500 MiB (Mebibytes).
Horizontale Autoskalierung
Horizontale Autoskalierung in Kubernetes bedeutet, dass die Anzahl der Pods je nach Bedarf angepasst wird.
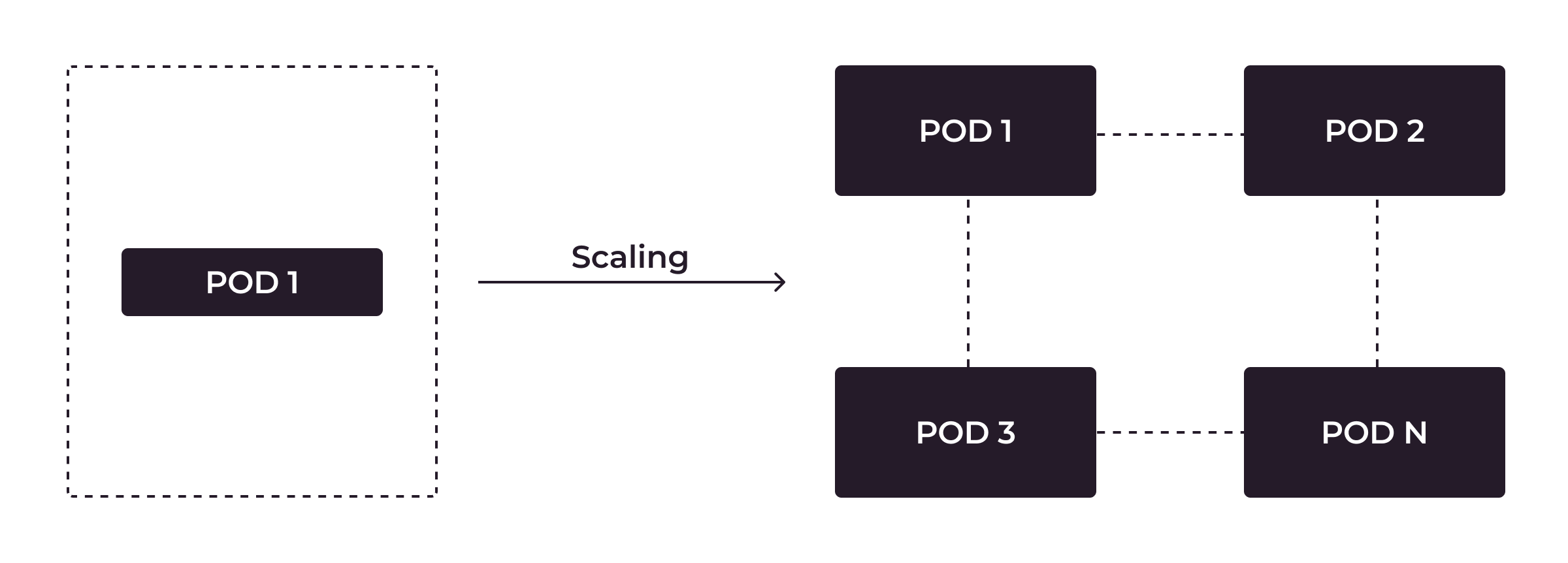
Die horizontale automatische Skalierung ist eine integrierte Funktion von Kubernetes. Sie können den HPA-Mechanismus für die Pods auf der Grundlage ihrer CPU- oder Speichernutzung einstellen.
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: app spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: appdeploy minReplicas: 1 maxReplicas: 10 targetCPUUtilizationPercentage: 70
Wenn im obigen Beispiel für HorizontalPodAutoscalerRessourcendefinition wenn targetCPUUtilizationPercentage über 70 ist, erstellt die Kubernetes mehr Pods. Die maximale Anzahl von Pods ist 10. Wenn targetCPUUtilizationPercentage unter 70 ist, werden nicht mehr benötigte Pods von Kubernetes entfernt. Die Mindestanzahl von Pods ist 1.
Ereignisbasiertes Kubernetes Autoscaling
Bei der horizontalen Autoskalierung können Sie Pods nur auf der Grundlage von Metriken zur CPU-Auslastung und Speichernutzung automatisch skalieren. Wenn Sie eine ausgefeiltere Methode zur automatischen Skalierung Ihrer Pods verwenden möchten, beispielsweise durch verschiedene Metriken wie total_http_request aus einer Prometheus-Datenbank, können Sie KEDA verwenden, was für „Kubernetes Event-driven Autoscaling“ steht.
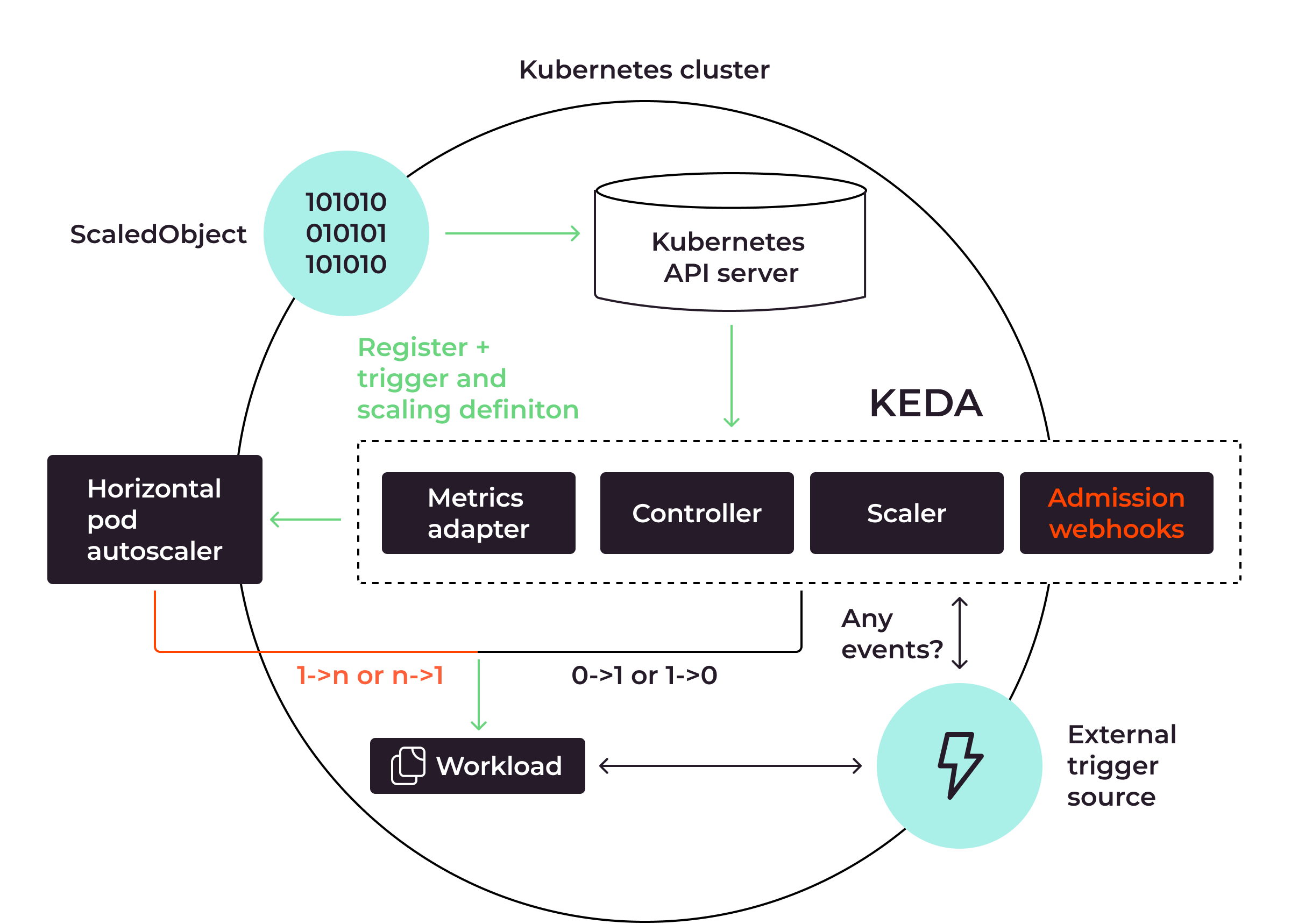
Das obige Diagramm zeigt, wie KEDA mit HPA zusammenarbeitet, um die automatische Skalierung von Pods anzuwenden:
- Der Kubernetes-API-Server fungiert als Brücke, um die Integration zwischen KEDA und Kubernetes zu ermöglichen
- KEDA
ScaledObjectist die benutzerdefinierte Kubernetes-Ressourcendefinition, die die Autoskalierungsmechanismen wie die Auslösetypen oder das Minimum und Maximum der Pods definiert. - Die Kernkomponenten von KEDA sind Metrics Adapter, Controller, Scaler und Admission Webhooks. Der Metrics Adapter und die Admission Webhooks sammeln Metriken von externen Triggerquellen wie Apache Kafka oder Prometheus, abhängig von den Trigger-Typen in der Definition von
ScaledObject. Wenn die Schwellenwerte für die Metrik erreicht sind, weisen Controller und Scaler den horizontalen Pod-Autoscaler an, die Skalierungsaufgabe zu übernehmen. - Die externe Triggerquelle, bei der es sich um eine beliebige Quelle wie Apache Kafka oder Prometheus handeln kann, ist dafür zuständig, Systemmetriken direkt vom laufenden Dienst zu sammeln. Wenn die Arbeitslast hoch ist, werden die Pods herausskaliert. Wenn die Arbeitslast gering ist, werden die Pods hineinskaliert. Wenn überhaupt keine Arbeitslast vorhanden ist, werden die Pods gelöscht, um die Ressourcen der Infrastruktur zu optimieren.
Hier sehen Sie ein Beispiel für KEDA, das Prometheus-Metriken verwendet, um den Autoscaling-Mechanismus auszulösen:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scale
namespace: default
spec:
scaleTargetRef:
name: app
minReplicaCount: 3
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress: http://103.56.156.199:9090/
metricName: total_http_request
threshold: '60'
query: sum(irate(by_path_counter_total{}[60s]))
In der obigen ScaledObject Definition für KEDA weisen Sie KEDA an, HPA zu benachrichtigen, die Pods so zu skalieren, dass die Mindestanzahl der Pods 3 und die Höchstanzahl 10 beträgt. Die serverAddress der Prometheus-Datenbank ist http://103.56.156.199:9090/. Die automatische Skalierung wird durch die Untersuchung einer Metrik namens total_http_request die mit Hilfe der Abfrage sum(irate(by_path_counter_total{}[60s])) aus der Prometheus-Datenbank abgerufen wird. Wenn das Ergebnis der Metrik größer als 60 ist, wird Kubernetes mehr Pods erstellen.
Autoscaling für Kubernetes-Knoten
Sie wissen jetzt, wie Sie die automatische Skalierung für Kubernetes-Pods implementieren. Die automatische Skalierung für Kubernetes-Pods allein reicht jedoch nicht aus, wenn die Pods aufgrund mangelnder Systemressourcen, die die aktuellen Kubernetes-Knoten bieten, nicht erstellt werden können. Um Ihre Anwendung bei der Arbeit mit Kubernetes effizient automatisch zu skalieren, sollten Sie die automatische Skalierung sowohl für Ihre Pods als auch für die Kubernetes-Knoten anwenden, damit Sie nicht manuell weitere Knoten zu Ihrem Cluster hinzufügen müssen.
Der Kubernetes Cluster Autoscaler ist eine Komponente des Kubernetes-Autoscaler-Tools, das die automatische Skalierung von Knoten unterstützt. Wenn es dem Kubernetes-Cluster an Ressourcen mangelt, werden dem aktuellen Cluster weitere Knoten hinzugefügt. Wenn Kubernetes-Knoten nicht genutzt werden, werden sie aus dem Cluster entfernt, damit Sie sie für andere Zwecke verwenden können.
Der Kubernetes Cluster-Autoscaler wird derzeit nicht für On-Premise-Infrastrukturen unterstützt, da Sie dort virtuelle Maschinen nicht automatisch erstellen oder löschen können; dies ist jedoch erforderlich, damit der Kubernetes Cluster-Autoscaler funktioniert. Wenn Sie den Kubernetes Cluster-Autoscaler für die automatische Skalierung der Kubernetes-Knoten verwenden möchten, können Sie einen verwalteten Kubernetes-Cloud-Dienst wie Managed Kubernetes von Gcore verwenden.
Mit Managed Kubernetes von Gcore können Sie einen Pool von Knoten mit spezifischen Informationen über die minimalen und maximalen Knoten erstellen, die Ihr Kubernetes-Cluster benötigt. Im Pool der Knoten können Sie den Typ der Knoten angeben: virtuelle Instanzen oder Bare-Metal-Instanzen (mit der genauen Angabe der gewünschten Systemressource). Sie können sogar mehrere Pools erstellen, sodass Ihr Cluster verschiedene Arten von Knoten haben kann, z. B. verschiedene Größen von virtuellen Instanzen oder sowohl virtuelle als auch Bare-Metal-Instanzen für Ihren Cluster.
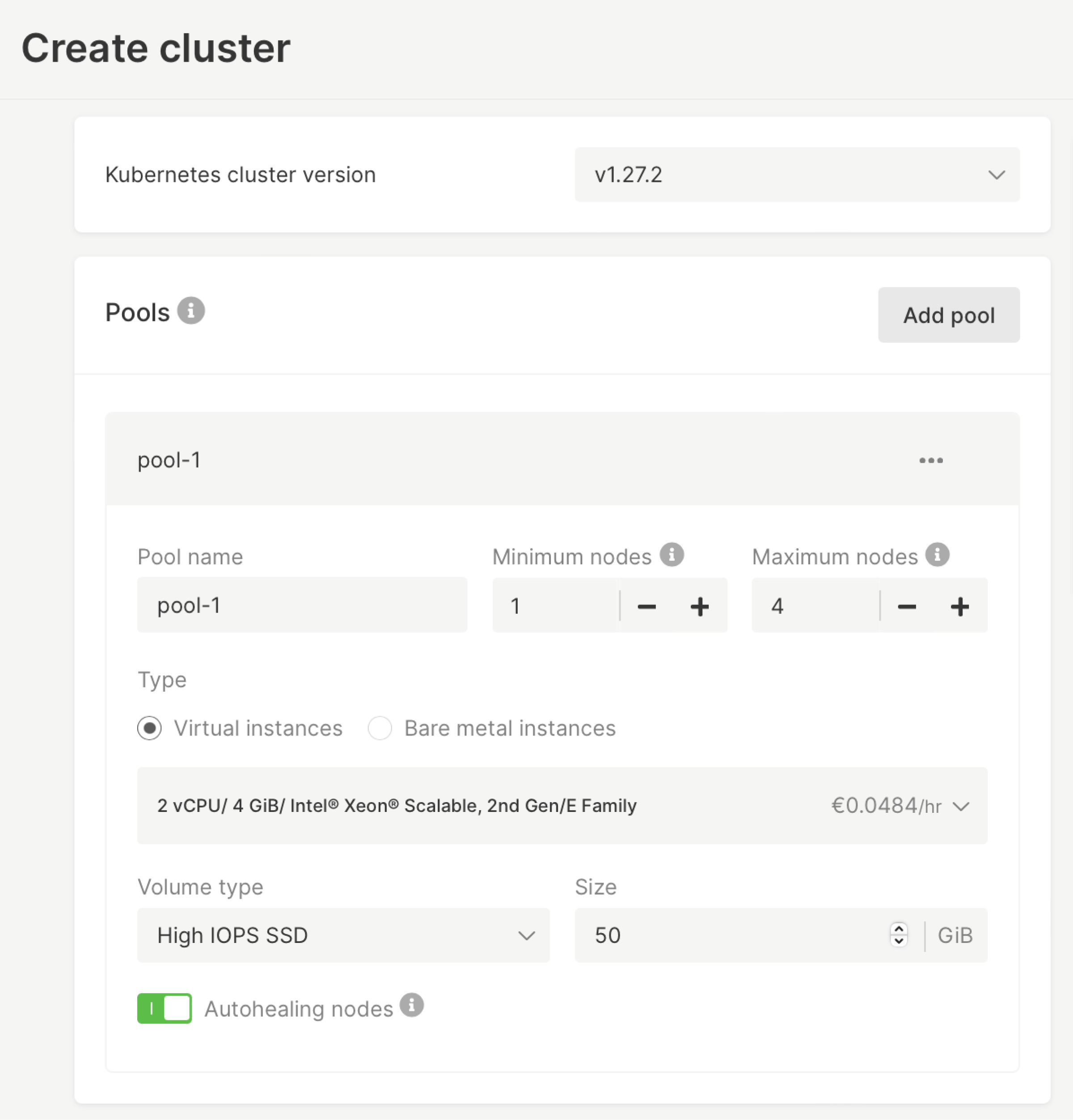
Best Practices für die Implementierung von Kubernetes Autoscaling
Um Autoscaling für Ihren Kubernetes-Cluster effizient einzusetzen, sollten Sie die folgenden bewährten Verfahren anwenden:
- Bevorzugen Sie HPA gegenüber VPA, wenn Sie die automatische Skalierung für Ihre Pods anwenden. VPA sollte nur verwendet werden, wenn Sie mit vorhersehbar steigenden Arbeitslasten arbeiten oder große Dateien speichern müssen, die nicht auf mehrere Kubernetes-Knoten aufgeteilt werden können. Andernfalls sollten Sie HPA verwenden, denn damit können Sie Ihre Anwendung mit weiteren Pods unbegrenzt skalieren. Außerdem müssen Ihre laufenden Pods nicht neu erstellt werden, um weitere Ressourcen hinzuzufügen, was die Verfügbarkeit Ihrer Anwendung im Gegensatz zu VPA verbessert.
- Mischen Sie VPA und HPA nicht basierend auf CPU- und Speichermetriken. Dies würde die Autoscaler verwirren, da sowohl VPA als auch HPA sich auf die CPU- und Speichermetriken verlassen, um Autoscaling anzuwenden. Wenn Sie diese beiden Autoscaler miteinander mischen möchten, verwenden Sie HPA mit der Option custom metrics.
- Legen Sie immer die Mindest- und Höchstwerte für die Anwendung der automatischen Skalierung von Pods fest. Auf diese Weise verfügt Ihre Anwendung immer über die Mindestkapazität, die für einen effektiven Betrieb erforderlich ist. Außerdem wird das finanzielle Risiko minimiert, wenn ein DDoS-Angriff oder ein kritischer Fehler in der Anwendung dazu führt, dass die Pods unendlich oft hinzugefügt werden.
- Legen Sie geeignete Schwellenwerte fest, um die automatische Skalierung auszulösen. Ein niedriger Schwellenwert kann zu einem unnötigen Herausskalieren führen. Bei einem hohen Schwellenwert kann es bei Ihrer Anwendung zu Ausfällen kommen, da Ihre Kubernetes nicht schnell genug skalieren kann, um den wachsenden Traffic zu bewältigen.
- Nutzen Sie Cluster-Autoskalierung, um zu verhindern, dass Ihre Anwendung ausfällt. Wenn Ihre Kubernetes-Pods nicht automatisch skaliert werden können, weil die Systemressourcen der Kubernetes-Knoten nicht ausreichen, müssen Sie Ihrem Kubernetes-Cluster weitere Knoten hinzufügen. Das manuelle Hinzufügen von Knoten nimmt jedoch viel Zeit in Anspruch, da Sie den Knoten für den Zugriff auf den Kubernetes-Cluster einrichten und dann darauf warten müssen, dass der Kubernetes-Cluster die Aufgaben an den neuen Knoten verteilt. Dies kann zu erheblichen Ausfallzeiten Ihrer Anwendung führen. Durch die Anwendung der automatischen Cluster-Skalierung können Sie weitere Knoten zu Kubernetes hinzufügen, wenn sich der Cluster der Grenze seiner aktuellen Systemressourcen nähert. Dies ermöglicht eine reibungslose automatische Skalierung des Clusters, ohne dass dies Auswirkungen auf Ihre Benutzer hat.
- Verwenden Sie KEDA für die automatische Skalierung Ihrer Pods, wenn Sie eine flexiblere Methode benötigen, um die automatische Skalierung des Pods auszulösen, anstatt sich nur auf CPU- und Speichermetriken zu verlassen. Sie können KEDA mit verschiedenen Ereignissen aus unterschiedlichen Quellen verwenden, darunter Apache Kafka und Prometheus. So können Sie die Art des Auslösemechanismus wählen, die am besten zu Ihrem Szenario passt. KEDA unterstützt auch die Null-Autoskalierung, die von Kubernetes nicht unterstützt wird. Mit der Null-Autoskalierung müssen Sie nicht einmal einen Pod laufen lassen, wenn er nicht benötigt wird. Das bedeutet, dass Sie die Kosten für Ihre Infrastruktur ohne Autoscaling optimieren können.
- Nutzen Sie ein Budget für Pod-Störungen, um zu gewährleisten, dass Ihre Anwendung immer über das erforderliche Minimum an Pods verfügt, insbesondere wenn Ihre Pods neu geplant werden müssen. Dazu gehören Fälle wie Anwendungsaktualisierungen oder wenn der Kubernetes-Cluster mit einem Knotenausfall zu kämpfen hat. Auf diese Weise können Sie die hohe Verfügbarkeit Ihrer Anwendung aufrechterhalten.
Fazit
Kubernetes ist eine leistungsstarke Plattform, mit der Sie Ihre Anwendungscontainer effizient verwalten können, wodurch Ihre Anwendung widerstandsfähiger und fehlertoleranter wird. Durch die Anwendung von Autoscaling für Ihre Kubernetes können Sie sicher sein, dass Ihre Anwendung skaliert werden kann, um einer wachsenden Zahl von Benutzern gerecht zu werden. Die automatische Skalierung von Kubernetes trägt auch zur Optimierung der Kosten Ihrer Infrastruktur bei, da die Ressourcen bei geringer Arbeitslast skaliert werden können.
Allerdings unterstützt Kubernetes derzeit keine automatische Skalierung von Clustern vor Ort. Ohne die Möglichkeit, Ihren Cluster automatisch zu skalieren, müssen Sie die Kubernetes-Knoten manuell anpassen, was zu erheblichen Ausfallzeiten Ihrer Anwendung führen kann, wenn Ihre Kubernetes aufgrund unzureichender Systemressourcen keine weiteren Pods erstellen kann. Mit dem Managed-Kubernetes-Cluster von Gcore können Sie Ihrem Kubernetes-Cluster sofort Knoten hinzufügen, damit Ihre Anwendung reibungslos und ohne Ausfallzeiten laufen kann. Wir bieten Bare-Metal-Server als Option an, mit der Sie die Performance des Kubernetes-Clusters maximieren können, indem Sie den Overhead der Virtualisierung durch virtuelle Maschinen entfernen.
Möchten Sie die Leistungsfähigkeit und Einfachheit des Managed-Kubernetes-Clusters von Gcore in Aktion erleben? Starten Sie kostenlos.





