| Category | Description |
|---|---|
| Text LLM | Large language models for text generation, summarization, and reasoning |
| Text + Image LLM | Multimodal models that accept both text and image inputs |
| Text + Audio LLM | Multimodal models that accept both text and audio inputs |
| Text embedding | Models that convert text into vector representations for semantic search and retrieval |
| Embedding | Multimodal embedding models |
| Image generation | Models that generate images from text prompts |
| Video Super-Resolution | Models that upscale and enhance video quality |
| Speech recognition | Models that transcribe spoken audio to text |
| Text to speech | Models that convert text to spoken audio |
| Safety model | Models that classify content for safety and policy compliance |
Browse the catalog
1. In the Gcore Customer Portal, navigate to Everywhere Inference > Application Catalog.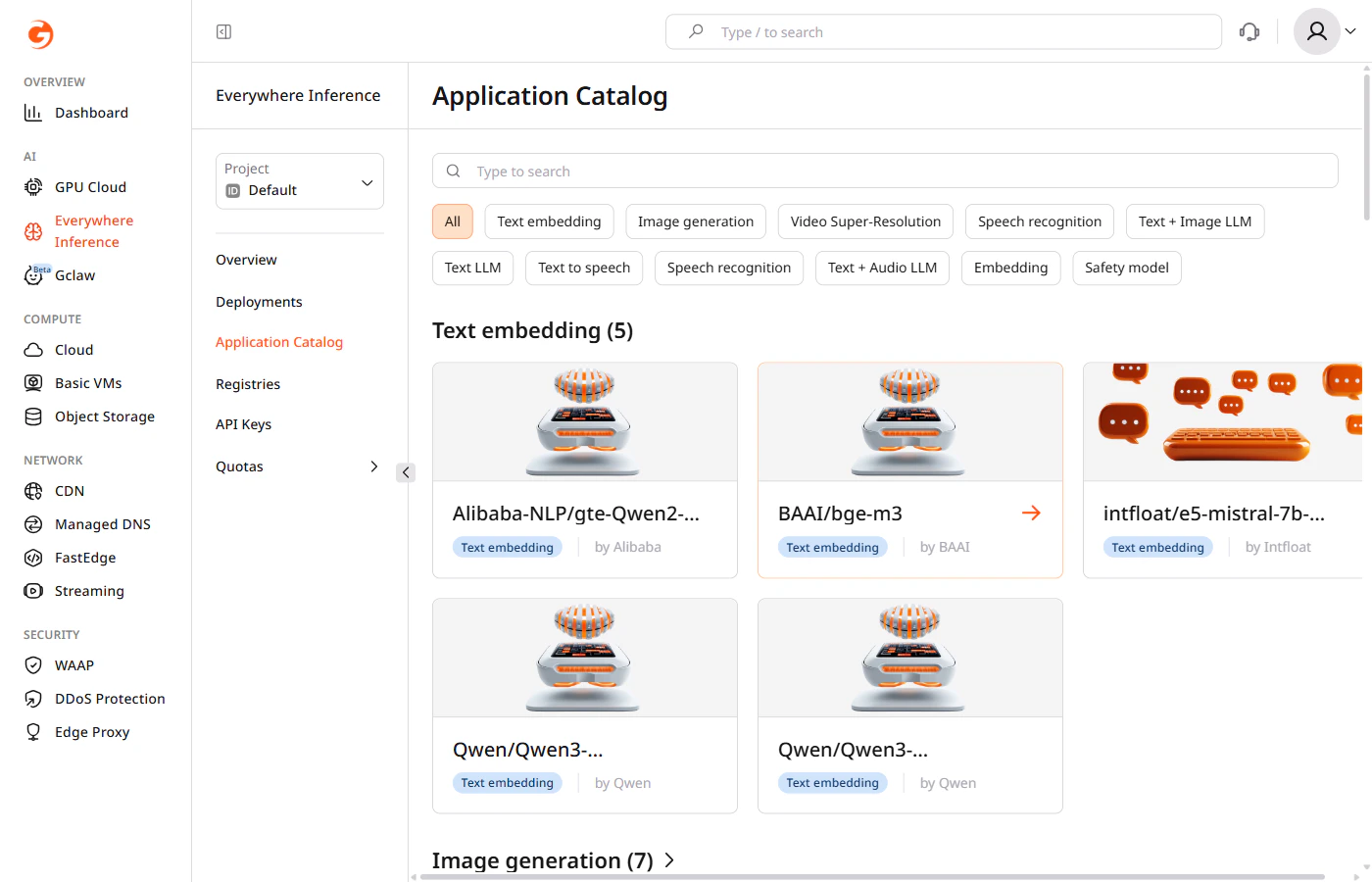
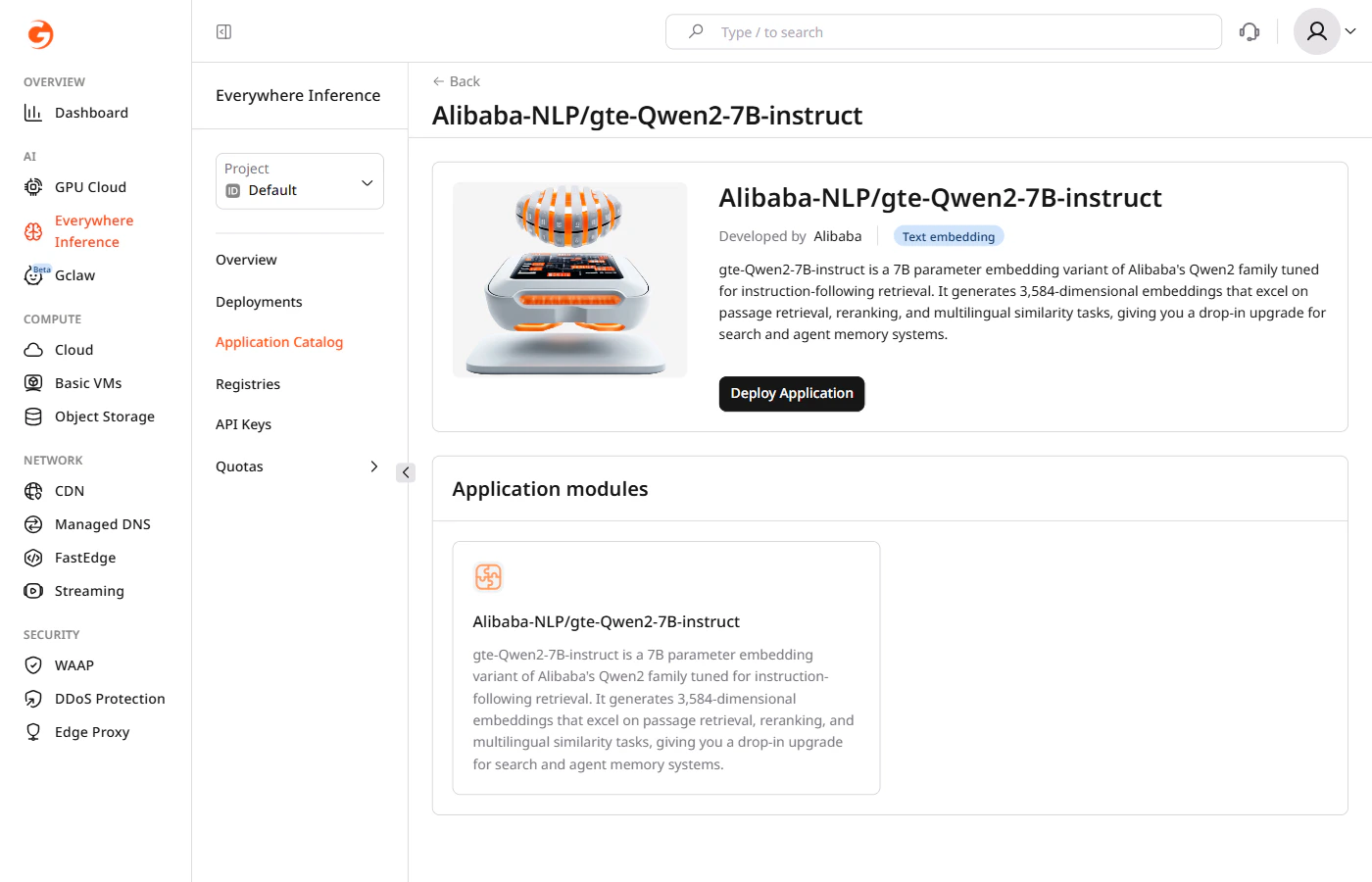
Deploy a model
Request a quota increase if the account quota is insufficient for the selected flavor.
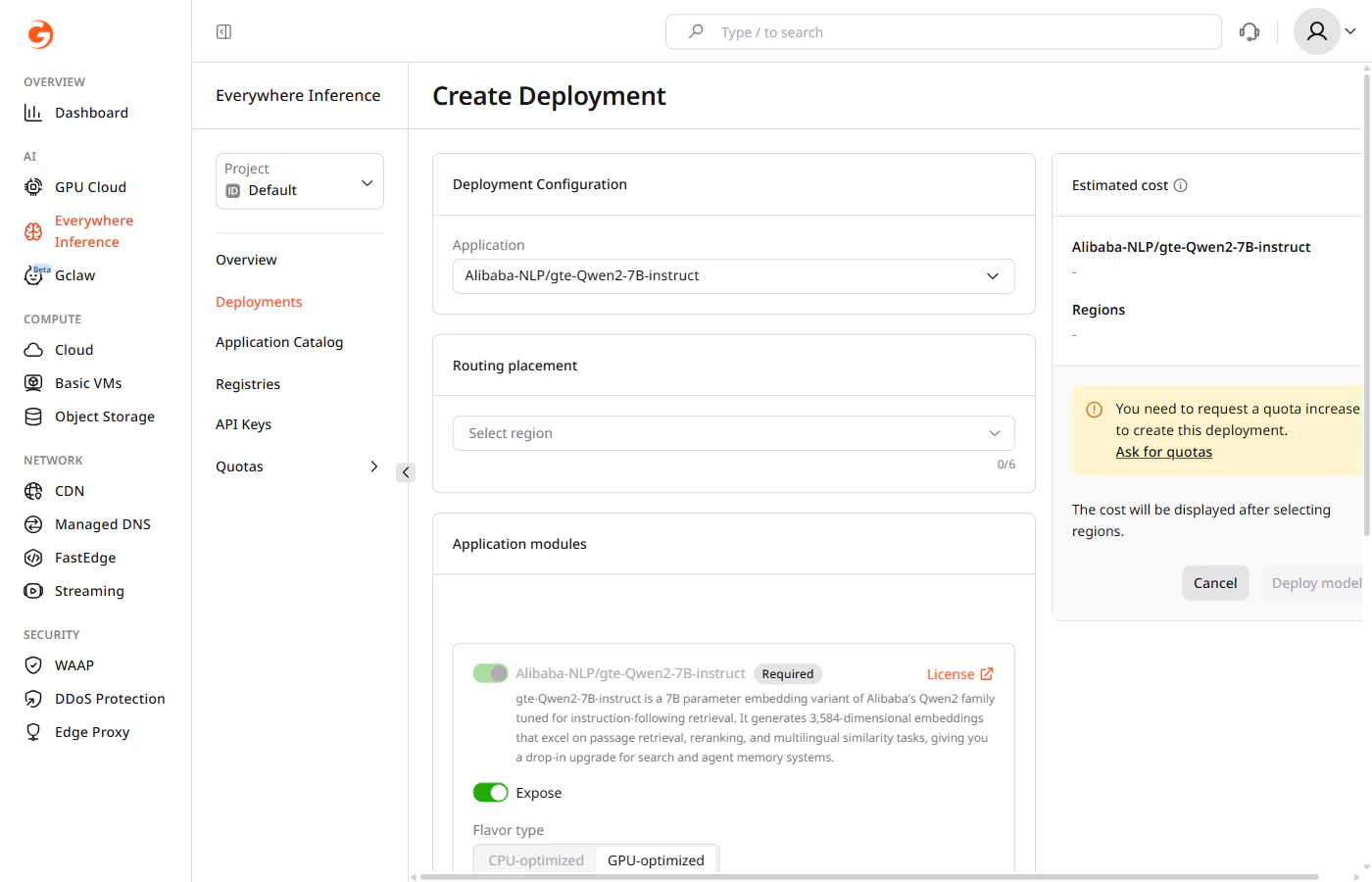
- Flavor type — select CPU-optimized or GPU-optimized depending on the model requirements.
- Flavor — select the hardware configuration from the dropdown.
- Minimum pods — the minimum number of pods to keep running during low-traffic periods.
- Maximum pods — the maximum number of pods Gcore provisions during peak traffic.
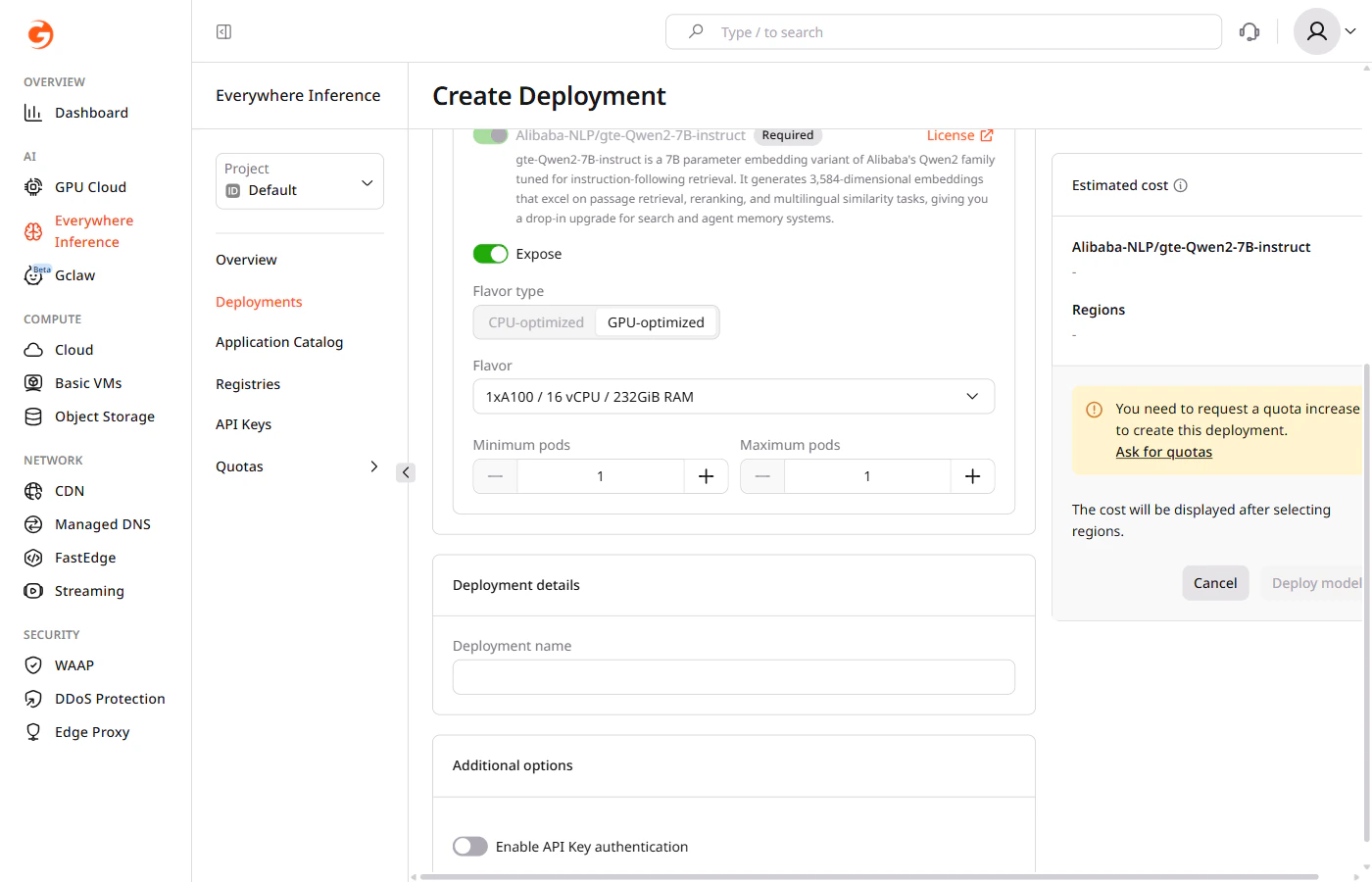
The main application module cannot be removed. The Expose toggle controls whether its endpoint is publicly accessible.
Available models
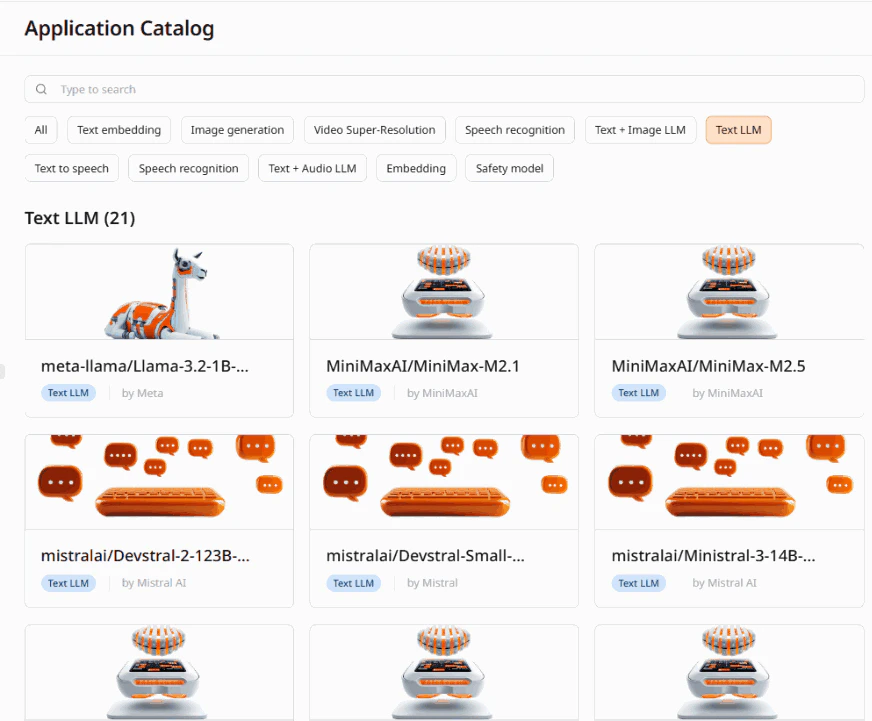
Text LLM (21 models)
Text LLM (21 models)
| Model | Provider |
|---|---|
| meta-llama/Llama-3.2-1B-Instruct | Meta |
| MiniMaxAI/MiniMax-M2.1 | MiniMaxAI |
| MiniMaxAI/MiniMax-M2.5 | MiniMaxAI |
| mistralai/Devstral-2-123B-Instruct-2512 | Mistral AI |
| mistralai/Devstral-Small-2505 | Mistral |
| mistralai/Ministral-3-14B-Reasoning-2512 | Mistral AI |
| openai/gpt-oss-120b | OpenAI |
| openai/gpt-oss-20b | OpenAI |
| Qwen/Qwen3-14B | Qwen |
| Qwen/Qwen3-235B-A22B-Instruct-2507 | Qwen |
| Qwen/Qwen3-30B-A3B | Qwen |
| Qwen/Qwen3-30B-A3B-Instruct-2507 | Qwen |
| Qwen/Qwen3-30B-A3B-Thinking-2507 | Qwen |
| Qwen/Qwen3-32B | Qwen |
| Qwen/Qwen3-Coder-30B-A3B-Instruct | Qwen |
| Qwen/Qwen3.5-122B-A10B | Qwen |
| Qwen/Qwen3.5-35B-A3B | Qwen |
| Qwen/Qwen3.5-397B-A17B-FP8 | Qwen |
| xai-org/grok-2 | xAI |
| zai-org/GLM-4.7 | Z.ai |
| zai-org/GLM-4.7-Flash | Z.ai |
Text + Image LLM (3 models)
Text + Image LLM (3 models)
| Model | Provider |
|---|---|
| google/gemma-3-27b-it | |
| Qwen/QVQ-72B-Preview | Qwen |
| Qwen/Qwen3-VL-235B-A22B-Instruct | Qwen |
Text + Audio LLM (1 model)
Text + Audio LLM (1 model)
| Model | Provider |
|---|---|
| mistralai/Voxtral-Small-24B-2507 | Mistral |
Text embedding (5 models)
Text embedding (5 models)
| Model | Provider |
|---|---|
| Alibaba-NLP/gte-Qwen2-7B-instruct | Alibaba |
| BAAI/bge-m3 | BAAI |
| intfloat/e5-mistral-7b-instruct | Intfloat |
| Qwen/Qwen3-Embedding-4B | Qwen |
| Qwen/Qwen3-Embedding-8B | Qwen |
Embedding (2 models)
Embedding (2 models)
| Model | Provider |
|---|---|
| nvidia/nemotron-colembed-vl-8b-v2 | NVIDIA |
| vidore/colpali-v1.3 | Vidore |
Image generation (7 models)
Image generation (7 models)
| Model | Provider |
|---|---|
| ByteDance/SDXL-Lightning | ByteDance |
| FLUX.1-dev | Black Forest Labs |
| FLUX.1-schnell | Black Forest Labs |
| stable-cascade | Stability AI |
| stable-diffusion-3.5-large | Stability AI |
| stable-diffusion-3.5-large-turbo | Stability AI |
| stable-diffusion-xl | Stability AI |
Speech recognition (4 models)
Speech recognition (4 models)
| Model | Provider |
|---|---|
| facebook/seamless-m4t-v2-large | Meta |
| mistralai/Voxtral-Mini-4B-Realtime-2602 | Mistral AI |
| openai/whisper-large-v3 | OpenAI |
| openai/whisper-large-v3-turbo | OpenAI |
Text to speech (3 models)
Text to speech (3 models)
| Model | Provider |
|---|---|
| microsoft/VibeVoice-1.5B | Microsoft |
| microsoft/VibeVoice-7B | Microsoft |
| ResembleAI/chatterbox | ResembleAI |
Video Super-Resolution (1 model)
Video Super-Resolution (1 model)
| Model | Provider |
|---|---|
| ByteDance-Seed/SeedVR2-7B | ByteDance |
Safety model (3 models)
Safety model (3 models)
| Model | Provider |
|---|---|
| openai/gpt-oss-safeguard-120b | OpenAI |
| openai/gpt-oss-safeguard-20b | OpenAI |
| Qwen/Qwen3Guard-Gen-8B | Qwen |