X-API-Key header — requests without a valid key receive an HTTP 401 response.
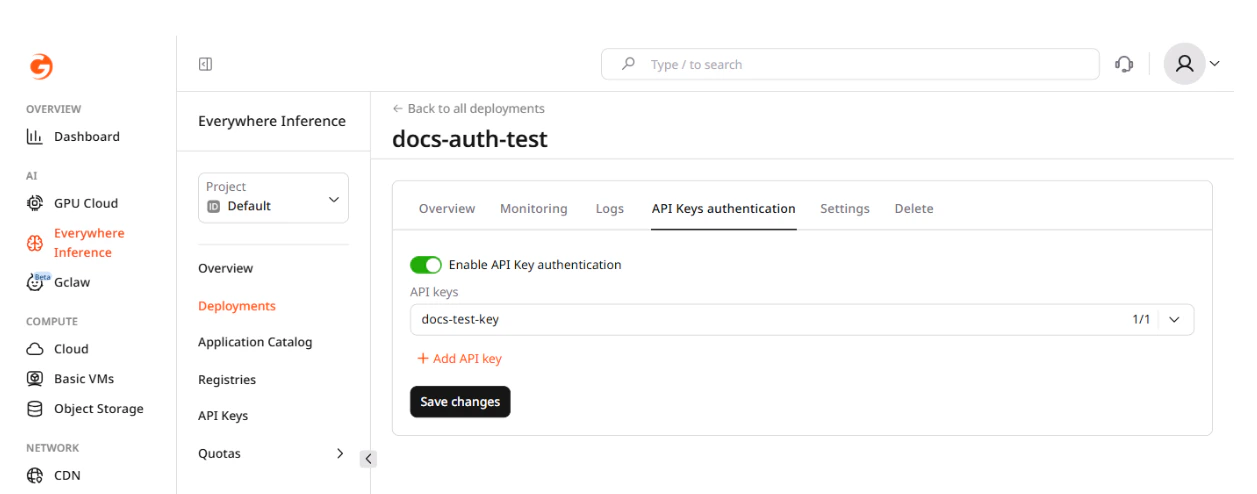
API keys are managed at the project level in Everywhere Inference > API Keys. A single key can be linked to multiple deployments, and a deployment can have multiple keys linked simultaneously.
API key creation
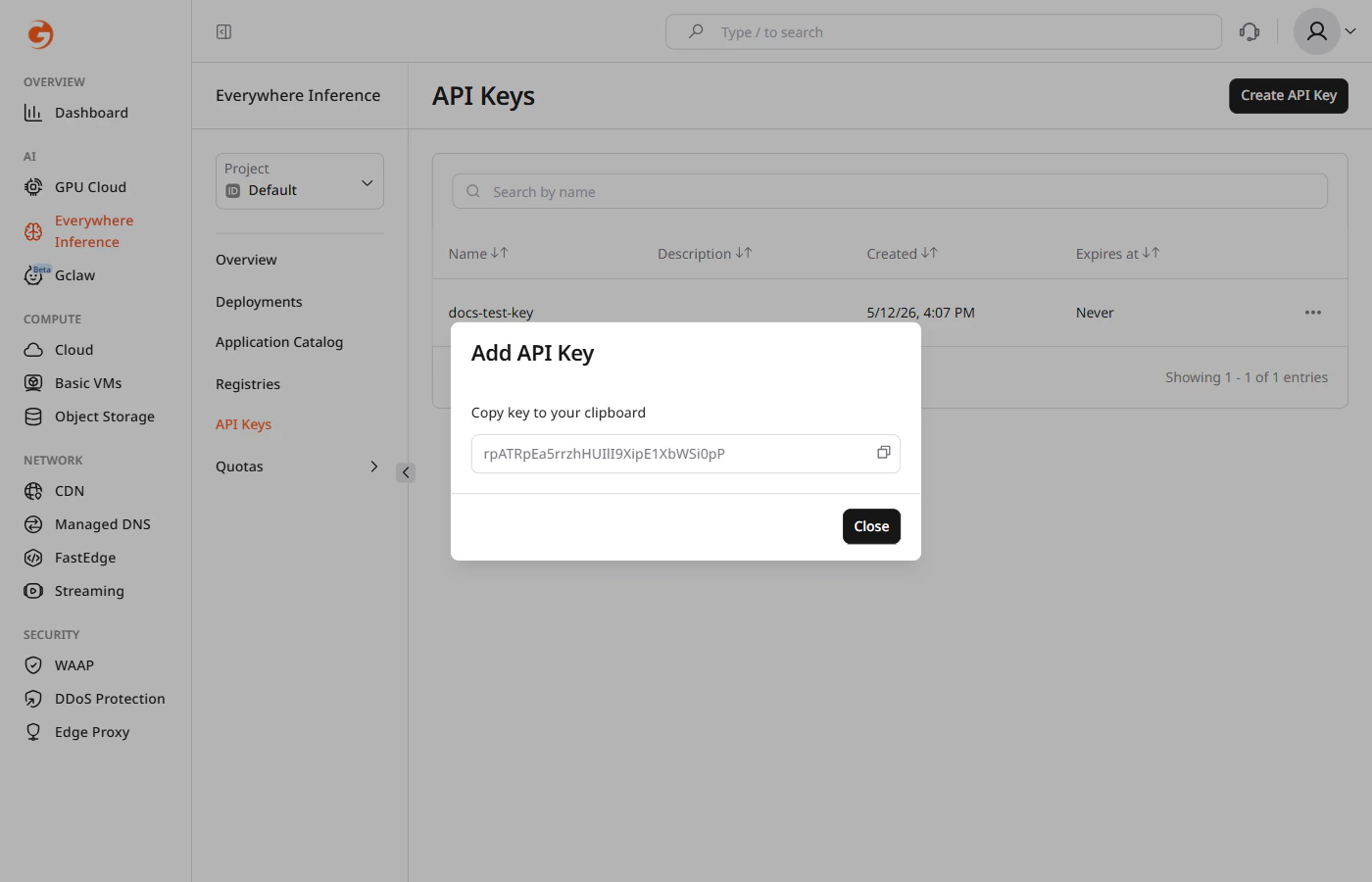
In the Gcore Customer Portal, navigate to Everywhere Inference > API Keys and click Create API Key.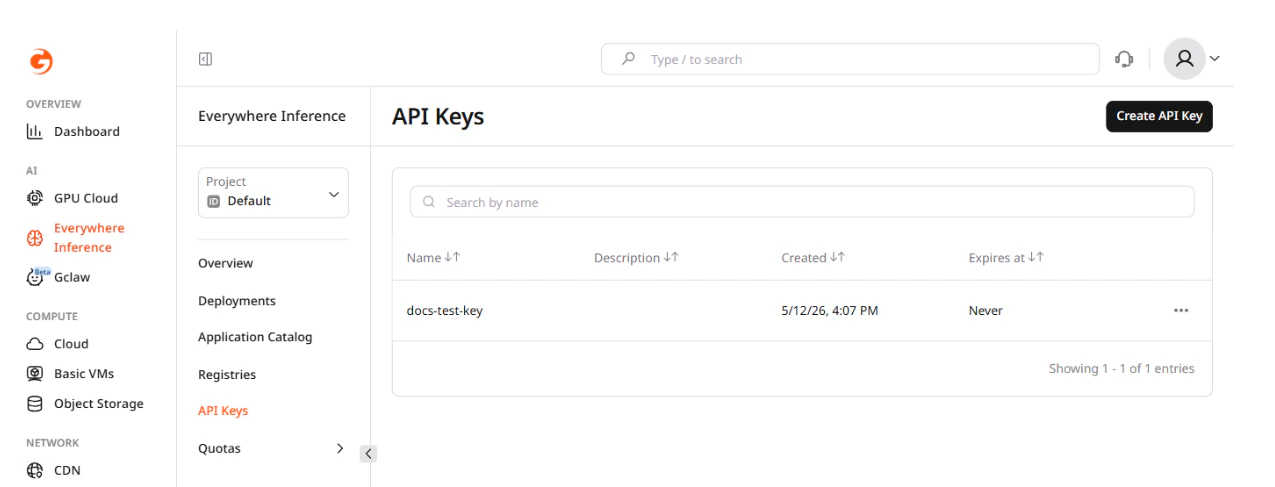
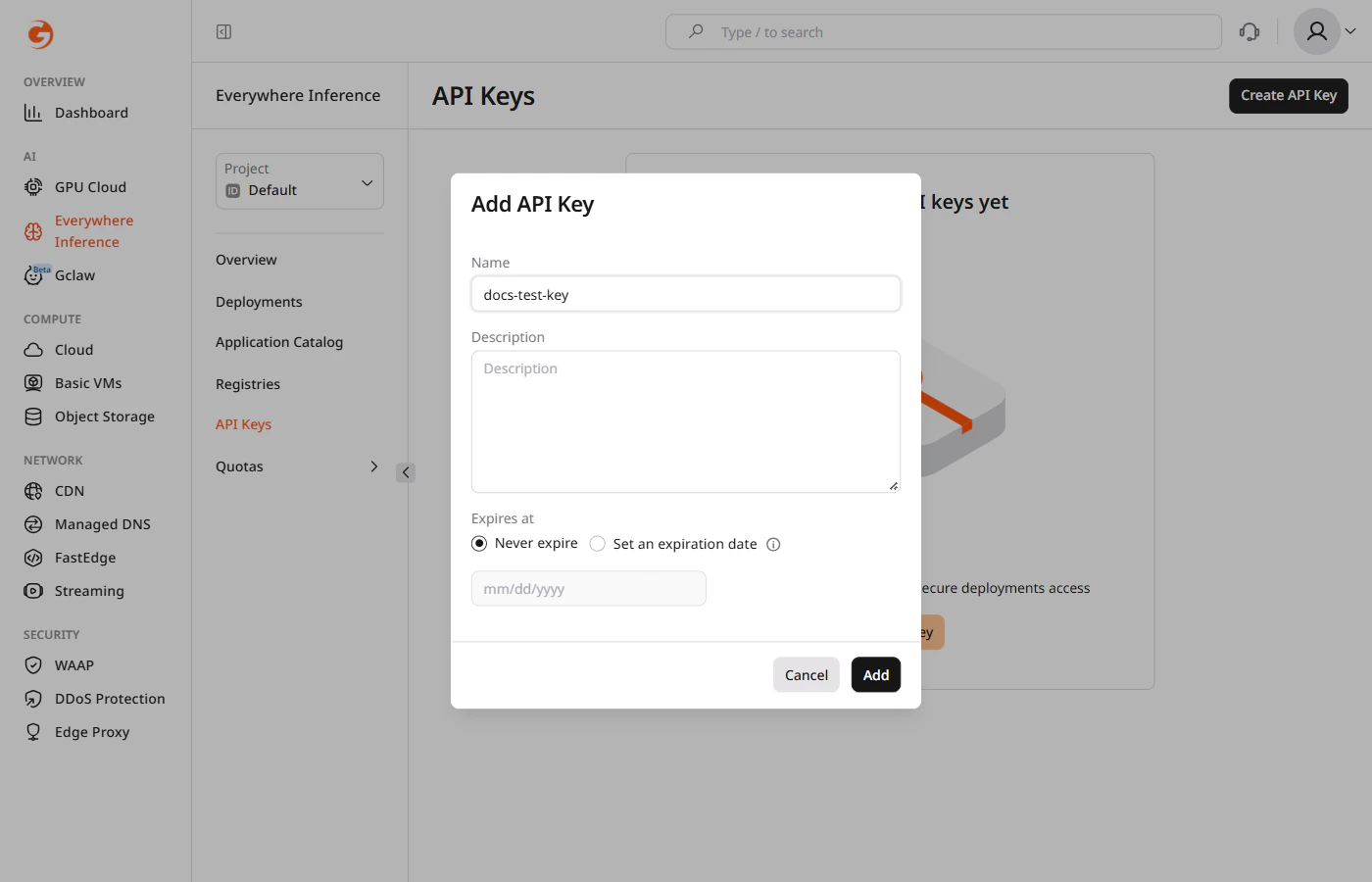
- Name — a label to identify the key across deployments.
- Description — optional note describing the key’s purpose or owner.
- Expires at — set a fixed expiration date or leave as Never expire for a permanent key.
Deployment authentication
API key authentication is configured during deployment. The steps below use meta-llama/Llama-3.2-1B-Instruct deployed from the Application Catalog. The same Additional options section is available when deploying a custom model.Step 1. Deployment form
In the Gcore Customer Portal, navigate to Everywhere Inference > Application Catalog, select a model, and click Deploy Application. The Create Deployment form opens.Step 2. Additional options
Scroll to the Additional options section and enable the Enable API Key authentication toggle. A dropdown labeled API keys appears, showing all keys created in the project. Select one or more keys to link to this deployment.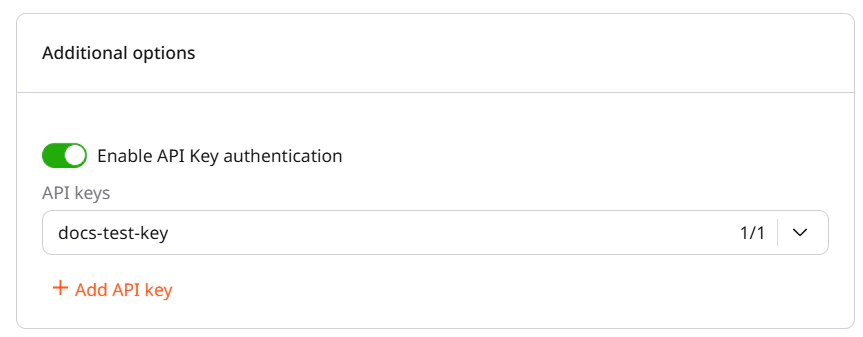
Authenticated requests
Include the API key in theX-API-Key header on every request. The endpoint rejects requests that omit the header or provide a key not linked to the deployment.
The OpenAI Python client requires a non-empty
api_key parameter even when the endpoint does not validate it. Pass any string, and provide the actual key via extra_headers.API Keys authentication tab
The API Keys authentication tab on the deployment detail page shows which keys are currently linked and allows adding or removing keys without redeploying. Changes take effect on the next request after saving.