With Gcore Everywhere Inference, you can deploy trained AI models on edge inference nodes. This provides low response times and optimized performance by bringing AI models closer to users. End-user queries are directed to the nearest running model using anycast endpoints, resulting in low latency and an enhanced user experience. This smart routing is automated through a single endpoint, so there’s no need to manage, scale, or monitor the underlying infrastructure—we take care of that on our end.Documentation Index
Fetch the complete documentation index at: https://gcore.com/docs/llms.txt
Use this file to discover all available pages before exploring further.
Getting started
With our global intelligence pipeline, a comprehensive ecosystem that supports the full AI lifecycle, from training to inference, it’s simple to deploy AI models. We empower the seamless development, deployment, and operation of AI models at various scales across multiple regions. To get started, check out our guide on deploying a model.How Everywhere Inference works
Everywhere Inference combines two technologies:- Edge network: Provides low latency via anycast balancing and smart routing.
- Serverless flexible GPU infrastructure: Enables quick initiation, integration, and deployment.
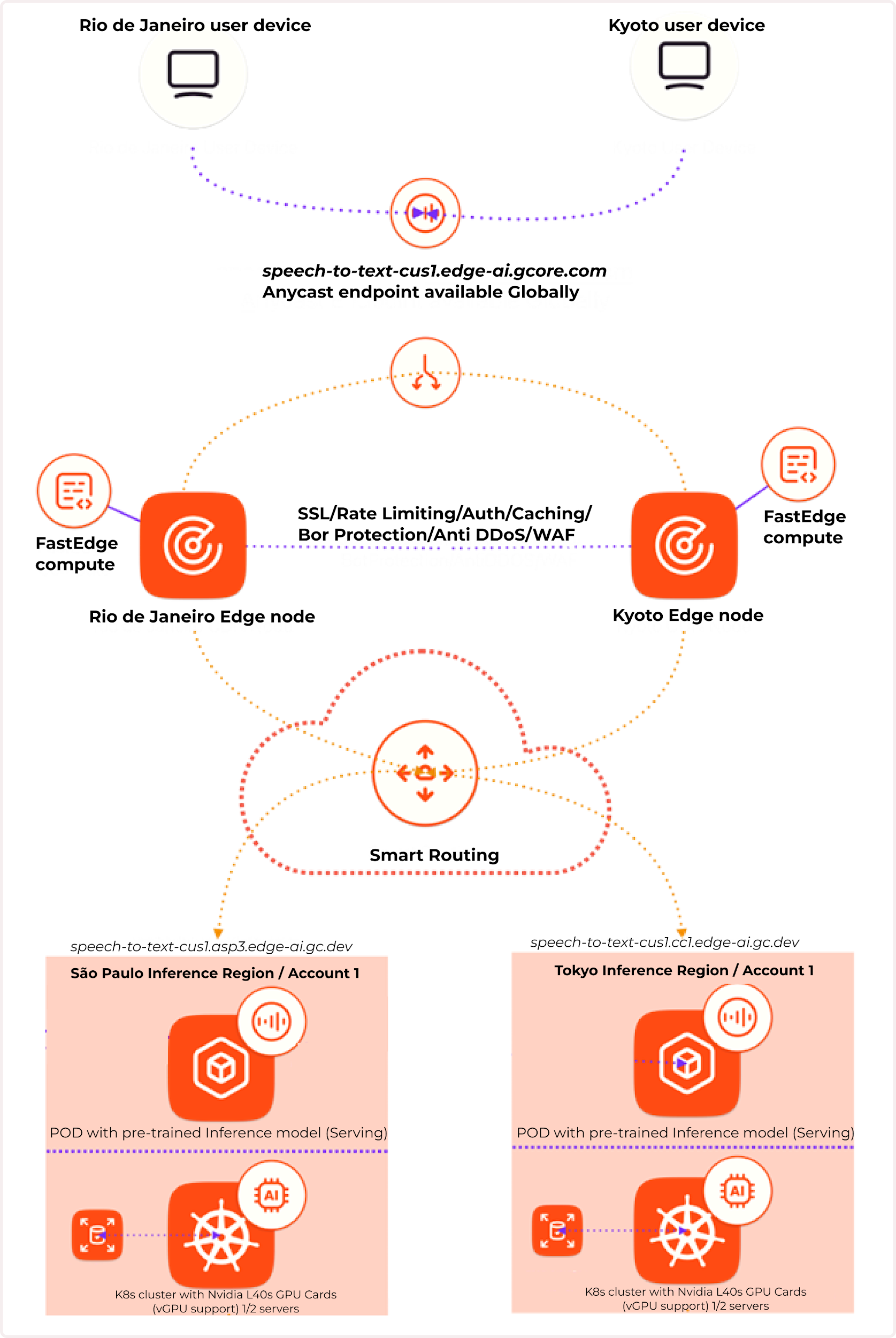
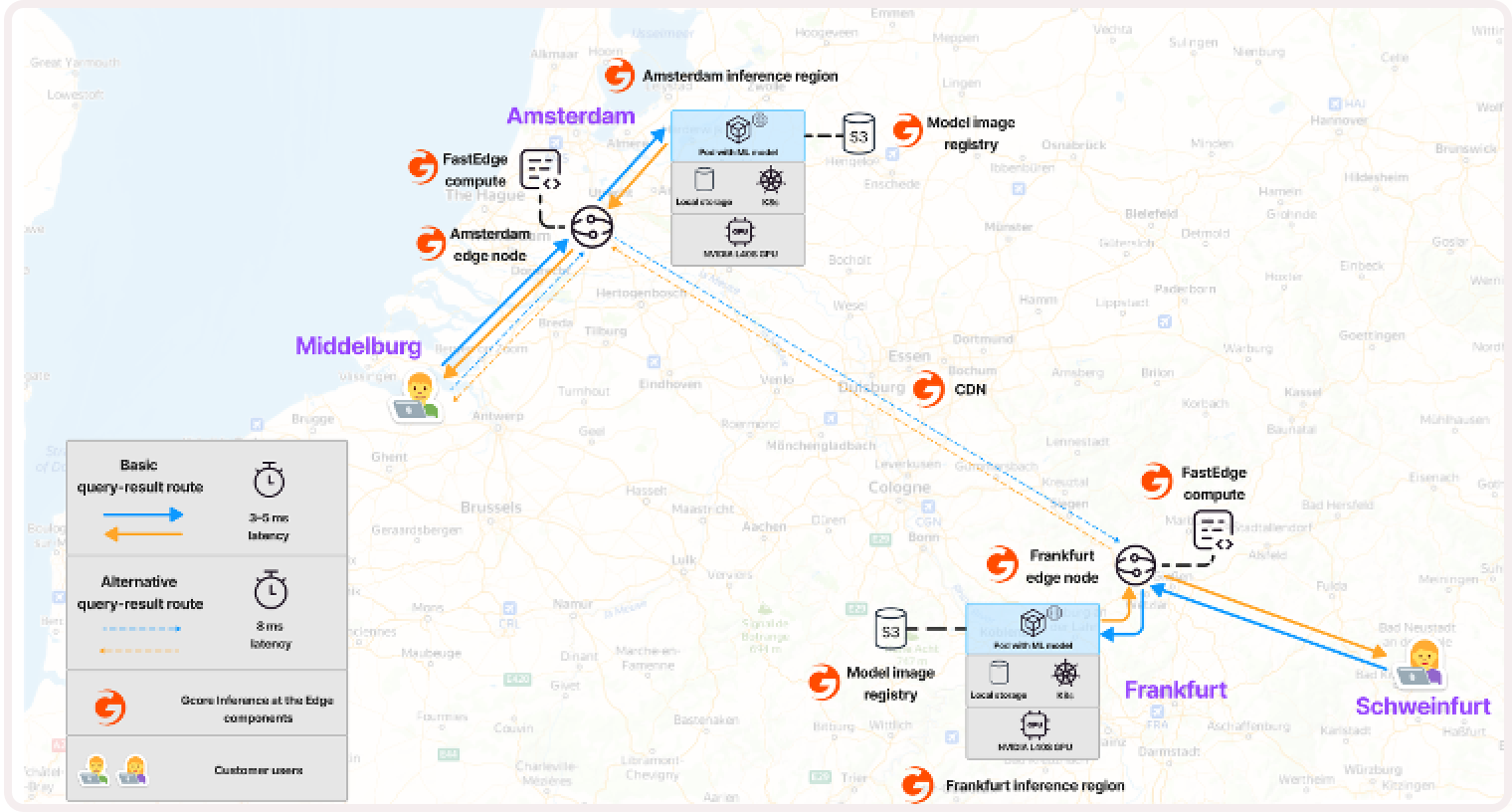
Use cases
Everywhere Inference is a versatile solution for businesses that require low-latency or real-time model responses. It caters to numerous industries, including the following:- Fintech and banking : Enables prompt anti-fraud detection and real-time credit scoring.
- Healthcare : Facilitates medical prescriptions based on data from wearable sensors and the analysis of medical data
- Gaming : Supports automatic opponent selection in competitive games, map generation, and maintaining open worlds.
- Media : Provides content analysis, automated transcribing, and translating of interviews.
- ISP and internet services : Offers AI-based traffic analysis and DDoS protection.
- Industrial and manufacturing : Provides real-time defect detection and fast feedback.
Key benefits
Everywhere Inference offers several key benefits:- Low latency : With over 180 points of presence worldwide, requests are transferred quickly to the nearest Everywhere Inference pod, resulting in low latency for users.
- Flexibility in model selection. Our model catalog offers leading open-source models at the click of a button. Or, opt to deploy your custom models with ease.
- High performance : Everywhere Inference uses the exclusively the latest, purpose-built NVIDIA GPUs to deliver fast model inference capable of handling the most demanding workloads.
- Cost efficiency : Payments are based solely on the runtime of the containers, which automatically scale in and out based on the number of user requests to keep your operations cost-effective.
- Easy control : Global AI infrastructure can be configured with just a few clicks in the Gcore Customer Portal or by API requests, simplifying management and control.
Supported features
Everywhere Inference supports the following features:- Model catalog with more than 20 foundational models
- Custom model deployment
- Various VM flavors (vGPU/vCPU/RAM)
- DDoS and bot protection
- API keys
Supported VM flavors
| vGPUs | vCPUs | Memory in GiB |
|---|---|---|
| - | 4 | 16 |
| - | 8 | 32 |
| 1xL40S | 16 | 232 |
| 2xL40S | 32 | 464 |
| 1xH100 | 16 | 232 |
| 2xH100 | 32 | 464 |
| 4xH100 | 64 | 928 |
| 1xA100 | 16 | 232 |
| 2xA100 | 32 | 464 |
| 4xA100 | 64 | 928 |
| 1xRTX-4000 | 10 | 40 |
| 2xRTX-4000 | 20 | 80 |
| 4xRTX-4000 | 40 | 160 |
Supported AI models
Everywhere Inference supports both custom and open-source models. The following foundational open-source models available in our AI model catalog:| Model | Description |
|---|---|
| aya-expanse-32b | An open-weight research release of a model with highly advanced multilingual capabilities. |
| ByteDance/SDXL-Lightning | An advanced framework designed to accelerate the development and deployment of scalable deep learning models |
| FLUX.1-dev | A 12-billion-parameter rectified flow transformer designed for text-to-image generation. |
| FLUX.1-schnell | A 12-billion-parameter rectified flow transformer designed for rapid text-to-image generation. |
| Llama-3.1-8B-Instruct | A multilingual large language model developed by Meta. |
| Llama-3.1-Nemotron-70B-Instruct | Q large language model customized by NVIDIA to improve the helpfulness of LLM-generated responses to user queries. |
| Llama-3.2-1B-Instruct | A multilingual large language model developed by Meta. |
| Llama-3.3-70B-Instruct | A tuned text-only model optimized for multilingual dialogue use cases. |
| Marco-o1 | A model focused on disciplines with standard answers, such as mathematics, physics, and coding. |
| Mistral-7B-Instruct-v0.3 | An instruct fine-tuned version of the Mistral-7B-v0.3 base model, designed to generate coherent and contextually relevant text. |
| Mistral-Nemo-Instruct-2407 | An instruct fine-tuned version of the Mistral-Nemo-Base-2407. |
| Mistral-Small-Instruct-2409 | A 22-billion-parameter large language model developed by Mistral AI. |
| Pixtral-12B-2409 | A Multimodal Model of 12B parameters plus a 400M parameter vision encoder. |
| Qwen2.5-14B-Instruct-GPTQ-Int8 | The latest generation of Qwen language models. |
| Qwen2.5-7B-Instruct | The latest generation of Qwen language models. |
| Qwen2.5-Coder-32B-Instruct | Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models. |
| Qwen2-VL-7B-Instruct | The latest version of the Qwen-VL model was enhanced to set new standards in visual understanding and interactivity. |
| QwQ-32B-Preview | An experimental research model developed by the Qwen team focused on advancing AI reasoning capabilities. |
| SDXL-Lightning Gradio | A high-performance variant of the Stable Diffusion XL text-to-image generation model designed for speed and efficiency. |
| stable-cascade | A compositional generative model that refines outputs through a staged pipeline. |
| stable-diffusion-3.5-large | An advanced text-to-image generation model featuring 8.1 billion parameters. |
| stable-diffusion-3.5-large-turbo | A distilled version of the Stable Diffusion 3.5 large model. |
| stable-diffusion-xl | A state-of-the-art text-to-image generation model with an enhanced UNet backbone and dual text encoders for improved detail and prompt adherence. |
| whisper-large-v3 | A state-of-the-art model for automatic speech recognition (ASR) and speech translation. |
| whisper-large-v3-turbo | A fine-tuned version of a pruned Whisper large-v3. |