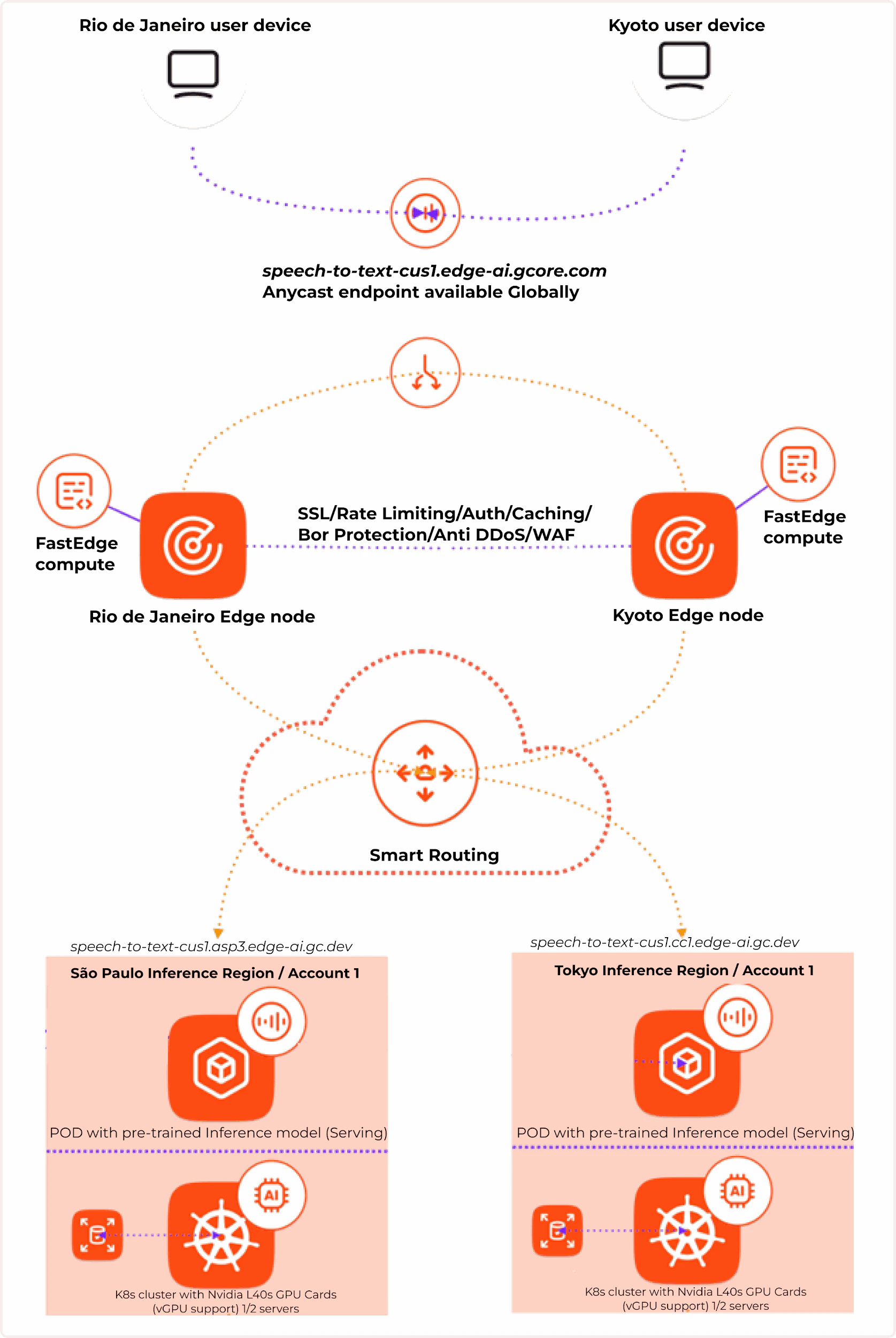
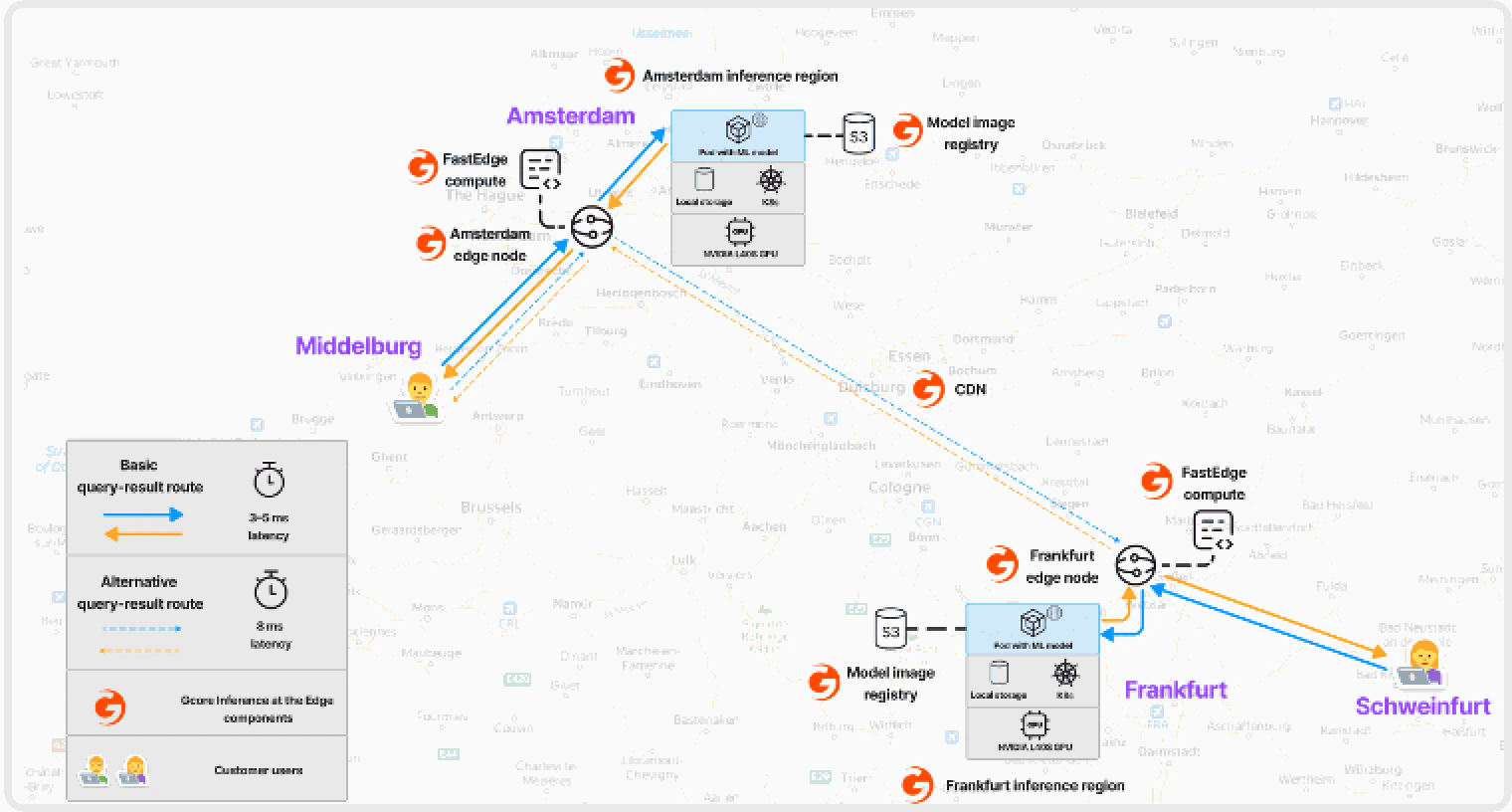
How Everywhere Inference works
It combines two technologies:- Edge network — provides low latency via anycast balancing, smart routing, and built-in DDoS and bot protection.
- Serverless flexible GPU infrastructure — enables deployment of Application Catalog models or custom models on purpose-built NVIDIA GPUs.
Supported VM flavors
The hardware options available to you depend on your account limits and region. To unlock GPU access or add more deployments, submit a quota request.| vGPUs | vCPUs | Memory (GiB) |
|---|---|---|
| — | 4 | 16 |
| — | 8 | 32 |
| 1xL40S | 16 | 232 |
| 2xL40S | 32 | 464 |
| 1xH100 | 16 | 232 |
| 2xH100 | 32 | 464 |
| 4xH100 | 64 | 928 |
| 1xA100 | 16 | 232 |
| 2xA100 | 32 | 464 |
| 4xA100 | 64 | 928 |