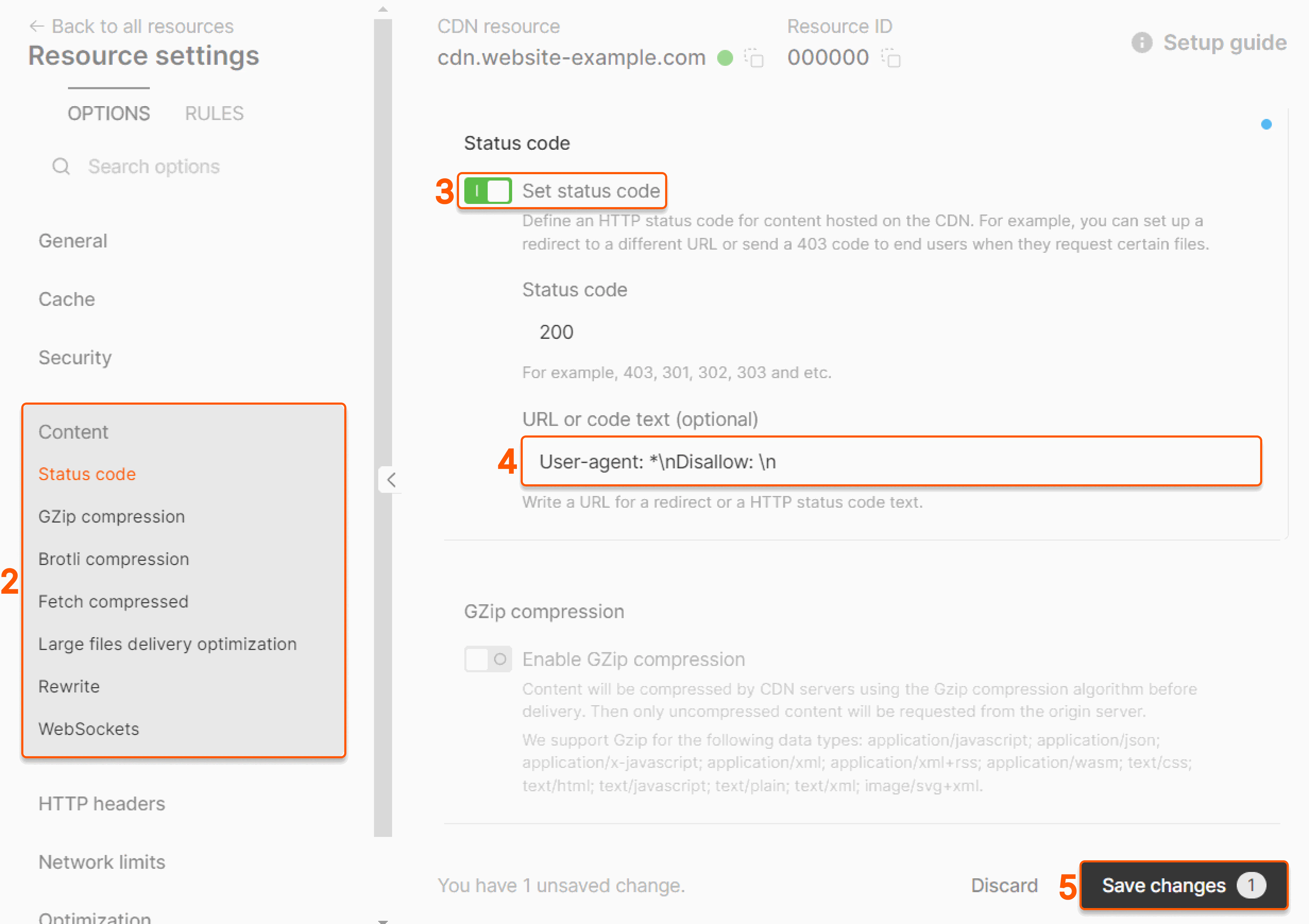
What is the problem with CDN custom domain indexing?
When you create a CDN resource for static assets for your original website, part of your content is available from the main (e.g., website-example.com/image.png) and CDN custom domains (e.g., cdn.website-example.com/image.png.) This can lead to duplicated content in search results which negatively affects SEO, degrading your site’s position on search engines like Google. By using the Status code option, you can forbid crawlers from indexing custom domains hence avoiding duplicate content.How to prohibit web crawlers from indexing your CDN custom domain
1. Go to the CDN resource and click the custom domain of the CDN resource you want to prohibit from indexing.