Create a new pool in a cluster
You can create a pool during cluster creation or add a new pool to an existing cluster in the cluster settings. The latter approach is described in the following steps: 1. In the Gcore Customer Portal, navigate to Cloud > Managed Kubernetes. 2. Find the required cluster and click its name to open the settings.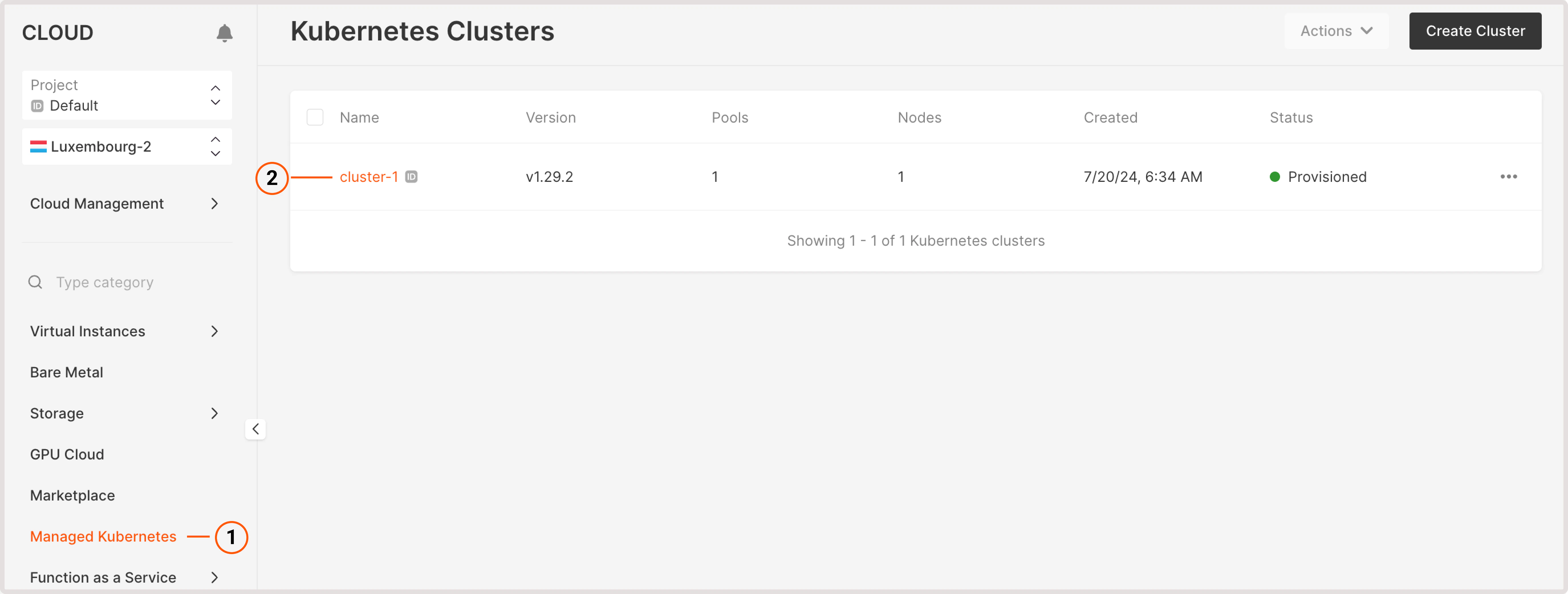
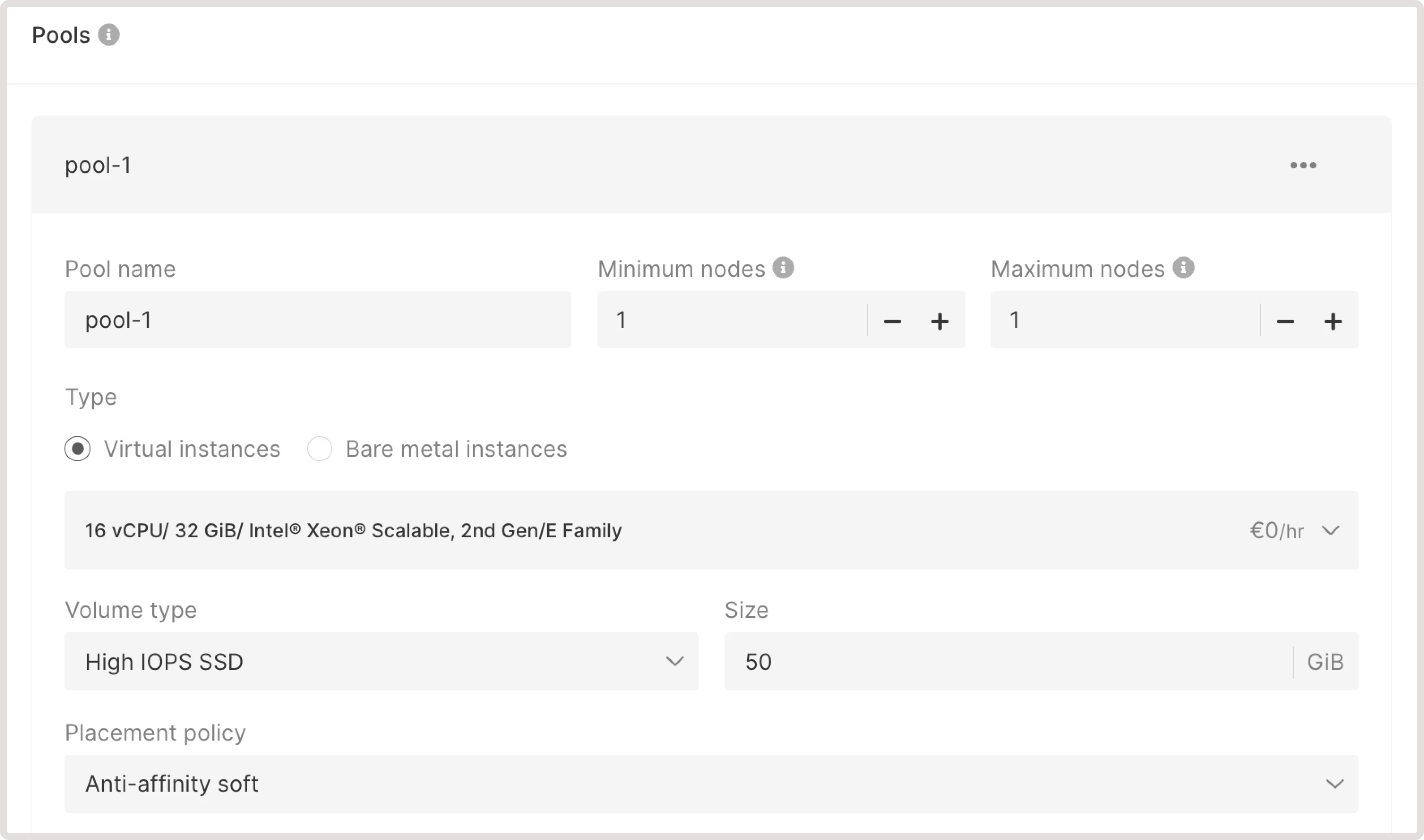
- Enter the pool name
- Set the minimum nodes and maximum nodes for autoscaling. Autoscaling will regulate the number of nodes within the specified limits by removing unnecessary nodes during low load and deploying new ones during high loads.
- Select the type of a worker node: a Virtual Machine (VM) or a Bare Metal server. For VMs, you should select a flavor, volume size in GiB, and the volume type.
- Choose the relevant placement policy: affinity, anti-affinity soft, or anti-affinity hard.
-
Adjust the optional settings:
- Add labels : Provide labels with extra information about the pool.
- Add taints : Taints define which pods can be scheduled on nodes. A pool can only be scheduled on a node that has a matching toleration. If you apply taints to a pool, it’ll affect all nodes within that pool.
- Autohealing nodes : Automatically replace failed nodes with working ones.
- Public IPv4 address : Assing a public address to the pool. You can assign a public IPv4 address during cluster creation and it can’t be configured for the existing cluster.
- If you want to configure advanced settings, check out the Configure advanced pool settings section for detailed instructions. Note that you can’t adjust advanced settings for an already created pool.

Configure advanced pool settings
If your cluster contains several pools, you can configure different combinations of settings for those pools. This gives you more granular control over cluster subsets and recourse usage. You can add a pool with advanced configuration during cluster creation or in the settings of an existing cluster. To do so, find the Advanced pool settings section and click the Configure settings link. The advanced pool settings are divided into two parts: Kubelet configuration and Container runtime interface configuration (CRI-O).Kubelet configuration
Customize how Kubelet manages pod scheduling and execution on every node. You can read more about these settings in the official Kubernetes documentation.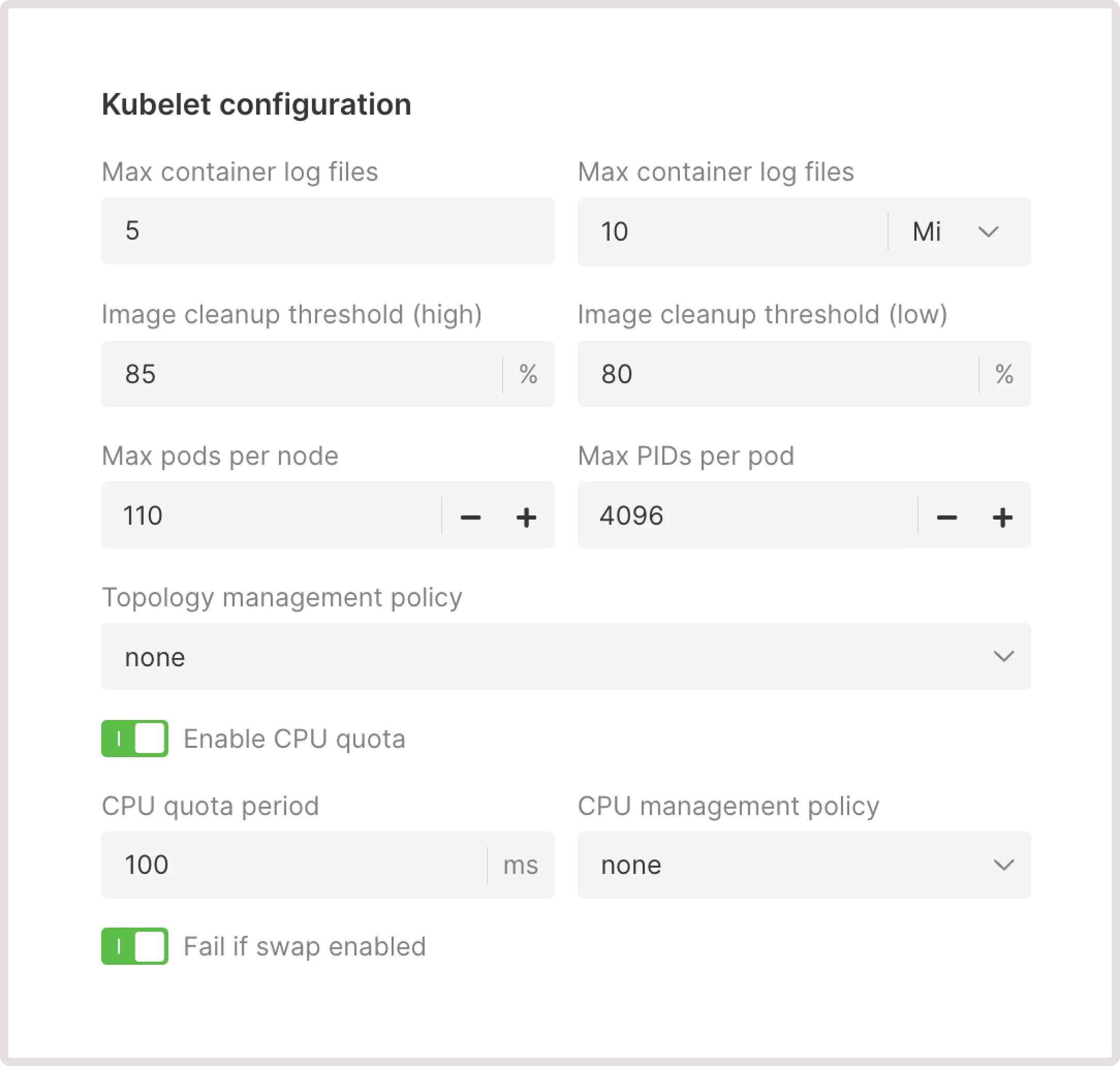
Max container log files
The maximum number of log files retained for a container. Once the limit is reached, the system will automatically delete the oldest log files to free up space for new ones.Max container log size
The maximum size a log file can reach before it’s rotated.Image cleanup threshold (high)
When the disk usage exceeds the threshold, Kubelet will start deleting unused images until the percentage drops below the low cleanup threshold.Image cleanup threshold (low)
When this threshold is reached, Kubelet will stop deleting unused images.Max pods per node
The maximum number of pods that can be scheduled on a node to prevent overcommitting of resources.InfoThe maximum allowed limit for Max pods per node is 110.
Max PIDs per pod
The maximum number of process IDs (PIDs) that can be used within a pod. This helps to prevent a single pod from exhausting system resources and affecting other pods on the same node.Topology management policy
Determines how Kubelet will coordinate the Container Runtime Interface (CRI) to allocate the resources:- none (default). Apply no topology arrangement. This policy can be used for workloads where performance isn’t significantly affected by the placement of resources.
- best-effort : Kubelet will try to allocate the pod’s resources from the same NUMA (Non-Uniform Memory Access) node. If that’s not possible, the resources will be allocated from multiple nodes. This policy can be used for workloads that require a balance of performance and flexibility.
- restricted : A pod is only allowed to run on a node if its resources can be allocated on a single NUMA node. Otherwise, the pod won’t start in that node. This policy is used for workloads where performance is important, and the cost of accessing memory or devices across NUMA nodes might negatively affect the workload’s efficiency.
- single-numa-node : Kubelet will only allow pods with a single NUMA alignment of CPU and device resources. This is applicable when the performance is critical and all the resources have to be as close together as possible.
Enable CPU quota (optional)
Sets limits on much memory and CPU the workload can use. You might disable this toggle in cases when you run a single application on a node and don’t need to limit its CPU usage.- CPU quota period : The frequency, in milliseconds, at which Kubernetes checks for CPU quota usage. If the allocated CPU quota is exceeded during this interval, Kubernetes will throttle CPU resources for the workload.
-
CPU management policy : Defines how CPU resources are allocated and managed for pods.
- none (default): The system has no strategy for allocating CPU resources, which lan be less effcient for workloads with frequently changing CPU demands.
- static: Distribution of allocated resources is predefined. Certain pods get dedicated CPU resources, and other pods share the remaining CPU.
Resource reservation for static policy
Resource reservation for static policy
When you enable the static policy, we reserve part of available CPUs and memory resources for Kubernetes components that run on each node.CPU resource reservation:
- 6% of the first core
- 1% of the next core (up to 2 cores)
- 0.5% of the next 2 cores (up to 4 cores)
- 0.25% of any cores above 4 cores
- 25% of the first 4 GiB of memory
- 20% of the next 4 GiB of memory (up to 8 GiB)
- 10% of the next 8 GiB of memory (up to 16 GiB)
- 6% of the next 112 GiB of memory (up to 128 GiB)
- 2% of any memory above 128 GiB
Fail if swap enabled
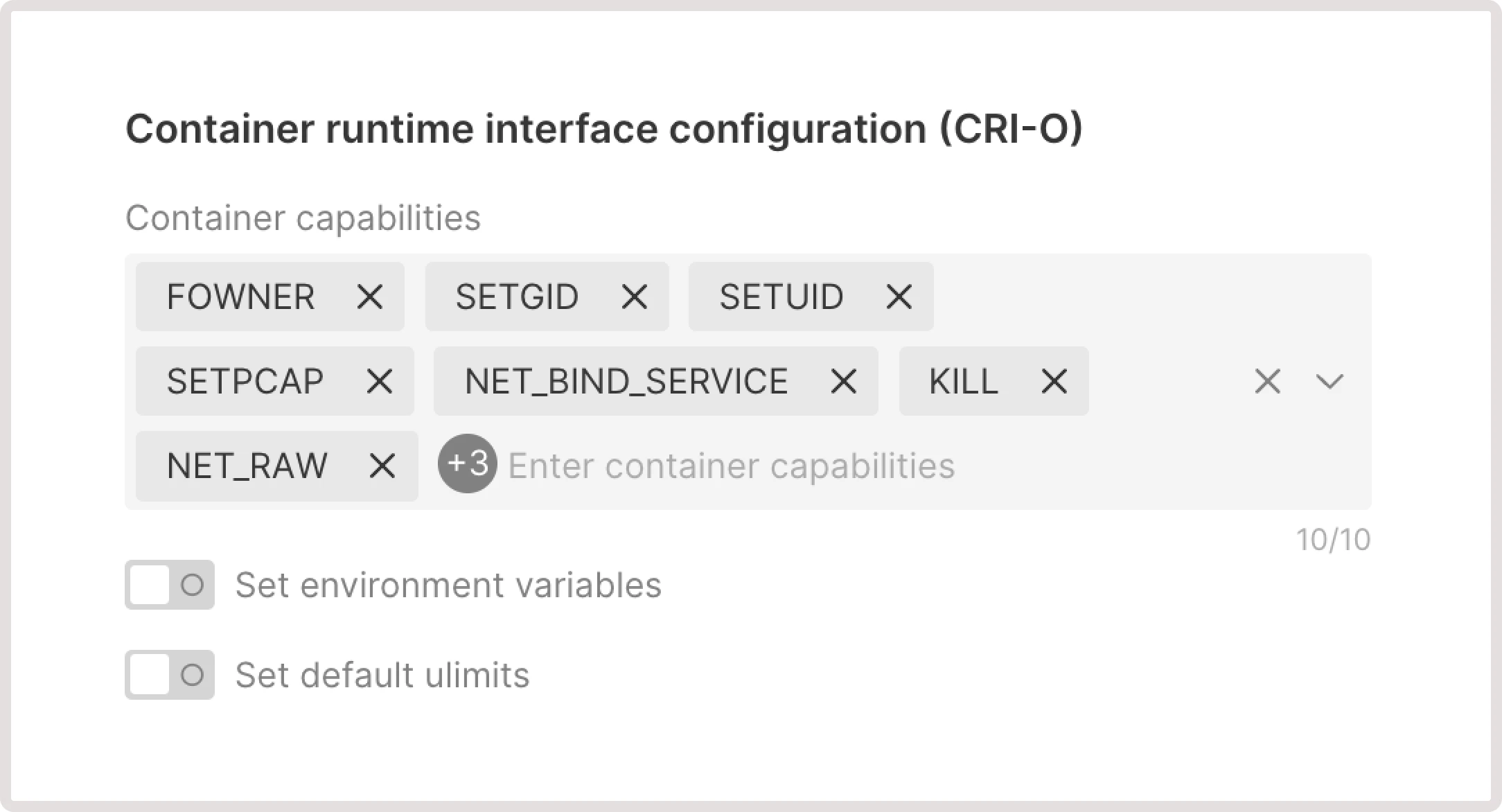
Determines whether the Kubelet should start if the Linux kernel swap space is enabled on the host machine.Container runtime interface configuration
Adjust container runtime settings (CRI-O) and specify how containers are executed and managed within the Kubernetes environment.