Introducing faster, lower-cost LLM inference with NVIDIA Dynamo
- February 25, 2026
- 5 min read
Imagine if you could click a button and suddenly your GPUs increase their throughput by 6x. Or reduce latency by 2x. Or route inference requests seamlessly across different GPU types.
That's the experience we're bringing to our inference customers by integrating NVIDIA Dynamo. Dynamo is an open-source, high-throughput, low-latency inference framework. It has the potential to transform GPU efficiency in ways that can make unicorn optimization a reality. It helps developers scale and serve generative AI models across large, distributed GPU environments.
At Gcore, we're proud to offer Dynamo to our inference customers today with all of its power. Our customers know we're all about making AI efficient to use, so we're offering Dynamo as a fully managed solution. With Gcore, you can benefit from Dynamo at the click of a button across public cloud, private cloud, hybrid, and on-prem inference environments.
Read on to find out what problems Dynamo helps solve, how it works behind the scenes, when it's a good fit, and how you can deploy it for your inference workloads with Gcore in just one click. But first, here's the TL;DR from Tamara Gapic, Gcore's Lead Cloud Pre-Sales Manager.
The challenge: efficient, futureproof inference at scale
In 2026, we're entering an inference-first era with AI deployments growing in size and complexity. That means even minor underutilization or small inefficiencies can translate into noticeable latency and reduced ROI. Dynamo is designed to tackle these efficiency issues at scale.
Inference workloads today commonly face the following challenges:
- Optimizing GPU utilization: Disaggregated inference can boost overall GPU utilizations. During prefill, utilization can exceed 90%. But during decode, it can drop as low as 10% because token generation is bottlenecked by the rest of the inference pipeline.
- Fluctuating demand and static allocation: Traditional inference allocates GPUs statically (one GPU per request or model instance) even though demand fluctuates and decode phases can leave the GPU mostly idle. This mismatch between fluctuating load patterns and rigid allocation is inefficient and leads to wasted capacity.
- Key Value (KV) cache recomputation expense: When KV caches can't be stored or reused efficiently, GPUs must recompute KV values instead of reading them from memory or storage. This increases compute cost and latency.
- Memory bottlenecks: Running large inference workloads with substantial sequence length and batch size means you need serious KV cache storage. Large models and long prompts can overwhelm GPU memory. That limits the number of concurrent requests and can force eviction or recomputation of cached values.
- Data transfer inefficiency: Dynamic inference workloads require fast coordination between GPUs for routing requests, moving KV blocks, load balancing, and scaling workers in real time. But most communication libraries were designed for static, training-style workloads rather than token-by-token inference. This leads to overhead, synchronization delays, and suboptimal use of interconnect bandwidth.
These challenges are becoming more pressing as workloads grow bigger and more complex. Dynamo targets these challenges in a single solution, and Gcore makes that solution easy to access as a one-click managed service.
The solution: Gcore serves NVIDIA Dynamo
Dynamo reimagines how GPUs are scheduled and utilized for inference workloads. Rather than focusing on GPU kernel optimizations, Dynamo introduced system-level improvements. With Dynamo, inference gets a distributed, high-utilization serving architecture. And by deploying on Gcore, you can deploy Dynamo in just one click.
This addresses all five challenges above, resulting in GPU efficiency improvements that can translate into increased ROI and decreased latency: good news for businesses, developers, and end users.
Two more pieces of good news about Dynamo:
- If you're running multi-turn chat, long contexts, or agentic tasks, Dynamo's scheduling and utilization benefits compound over time.
- If you're running single GPU deployments, Dynamo sets you up with a future-ready serving architecture, without requiring you to redesign your existing models or pipelines.
NVIDIA Dynamo is open source. You can check out the complete codebase and get involved on GitHub.
Here's how intuitive it is to deploy Dynamo on Gcore. You just pick your model and deploy in one click.
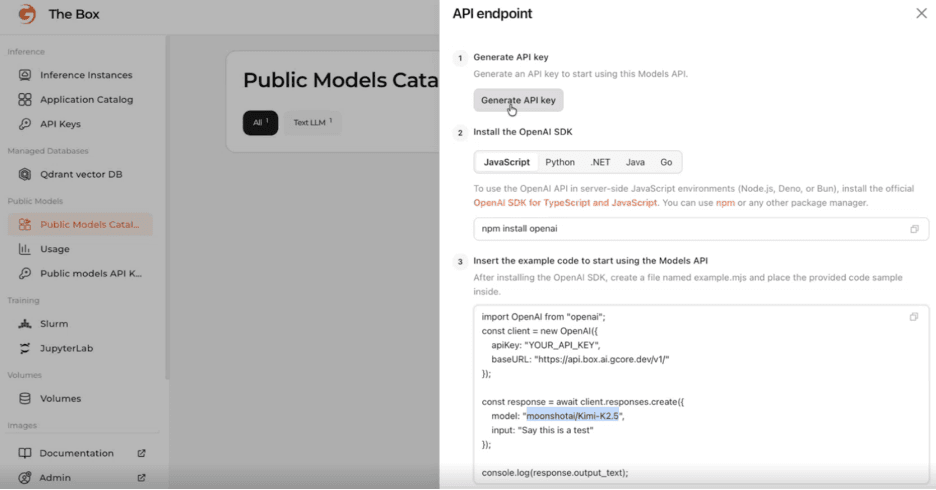
How it works
The architecture introduces: disaggregated serving, smart KV cache management, and intelligent routing.
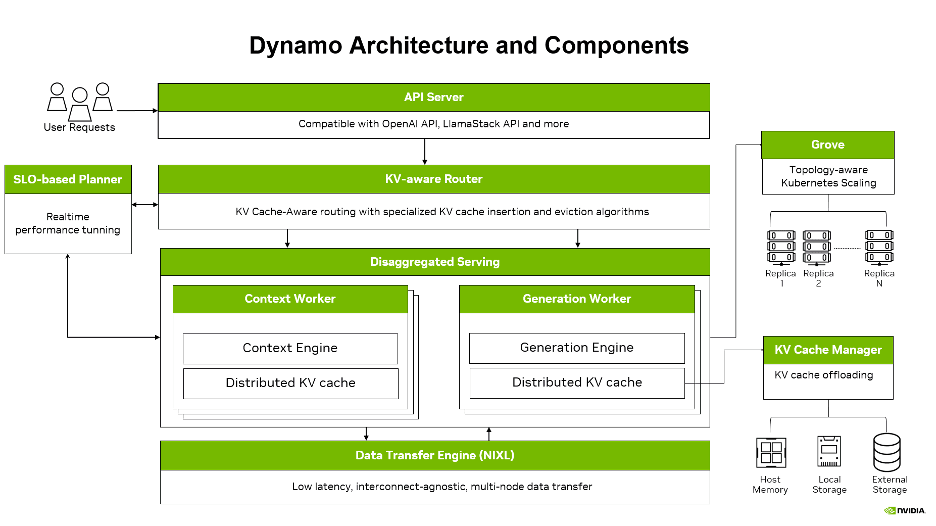
All these elements are modular, meaning you can turn on what you need and leave what you don't, giving a high level of control over Dynamo's offerings.
Disaggregation
Disaggregated serving is the ability to split inference requests across multiple GPUs for optimization. For example, you might want to use one GPU type for prefill and another for decode, since prefill needs more compute and decode needs more memory. It also allows you to separate out the prefill and decode stages, creating more opportunities for parallel processing and more efficient parallel processing when it happens. You can decide whether to prioritize prefill or decode depending on the use case for the best end-user experience.
Here's how it compares to traditional serving.
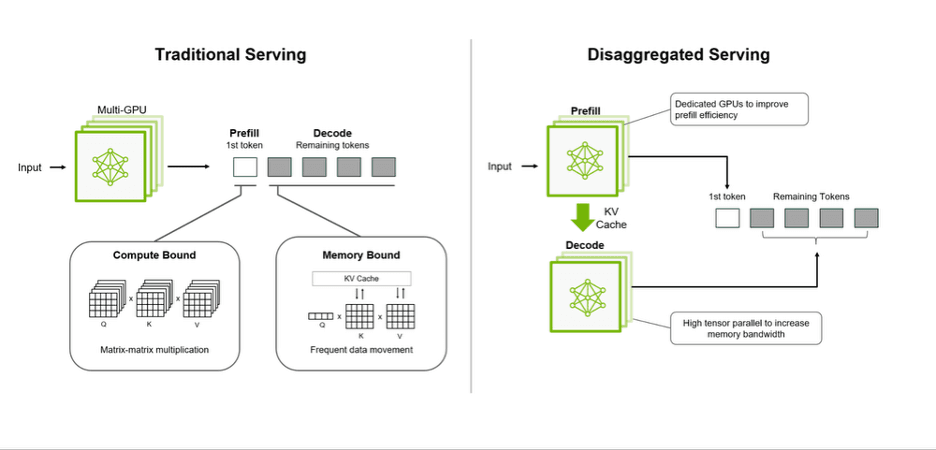
Disaggregation means fewer idle GPU resources and faster responses, which translates to better performance at a lower cost.
But getting these different GPU types to collaborate is challenging. Round robin routing doesn't cut it anymore. So Dynamo also offers intelligent routing.
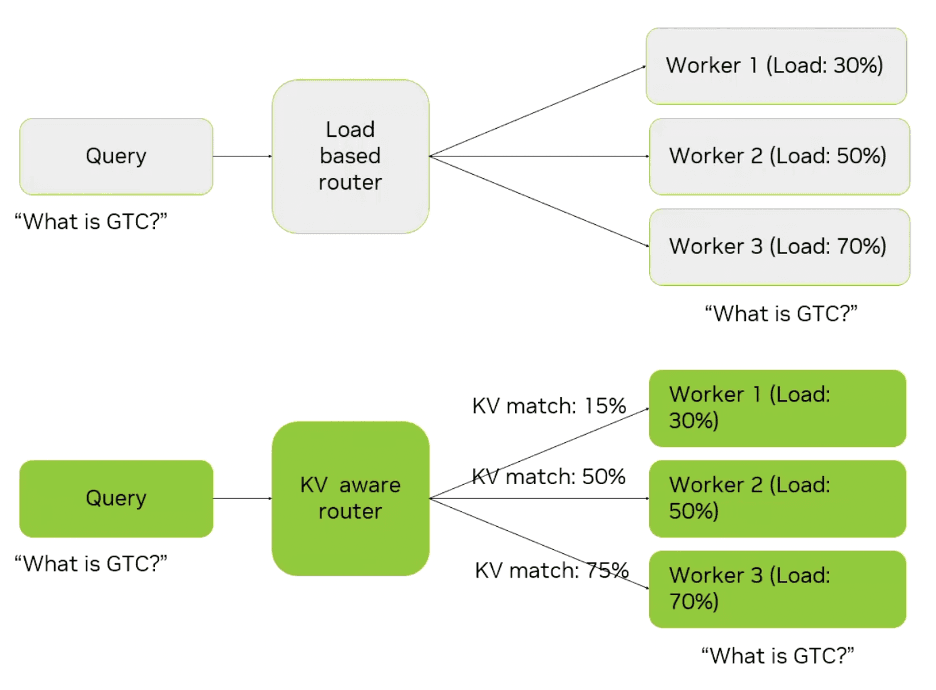
Intelligent routing
Dynamo offers KV cache-aware routing that directs each request to the worker with the best cache hit rate while maintaining load balance. Each worker gets assigned a score based on current load and KV cache hit accuracy, so a heavily loaded worker can be selected if it has a higher score based on the cache hit rate. Without Dynamo, the cache wouldn't be accessed.
That's great news for decoding speed and efficiency, reducing end-to-end latency by up to 2x.
More KV cache wins:
- You can load and prefetch the KV cache right when you need it. That's big news for multi-turn chat or long context.
- You can offload/prefetch for time-specific tasks exactly when needed. This is especially relevant for agentic tasks where tool call traditionally takes a frustratingly long time.
Data transfer
So, your inference is now split across different GPUs (disaggregation) and routed to the best worker for each request (intelligent routing). But that's all irrelevant unless the data can move really, really fast across nodes.
And that hasn't been the case in traditional communication libraries, which were designed for big, static, predictable training jobs, not for fast, token-by-token inference sprints. As a result, they introduce overhead and synchronization delays to inference workloads.
NVIDIA Inference Transfer Library (NIXL) takes care of this problem. It is a high-throughput, low-latency point-to-point communication library tailored for Dynamo's inference communication patterns. It provides a consistent data movement API to move data rapidly and asynchronously across different tiers of memory and storage and supports nonblocking, noncontiguous data transfers. Even without the rest of Dynamo, NIXL reduces TTFT by 1.8x and acts as the backbone that makes Dynamo work.
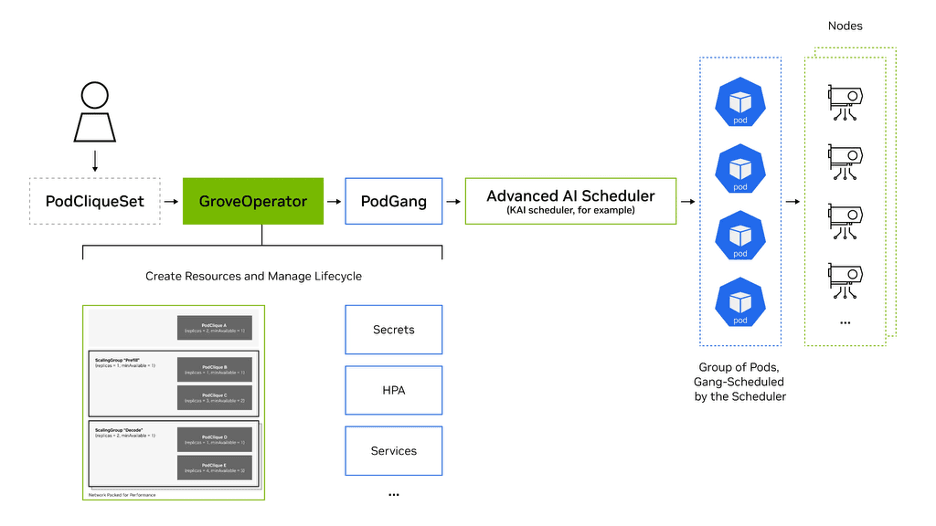
Kubernetes scaling with Grove
NVIDIA Dynamo includes NVIDIA Grove as a modular component. Grove is a Kubernetes-native API for orchestrating modern, multicomponent AI inference systems as a single logical deployment. Instead of scaling individual pods, Grove lets you define an entire serving stack (such as prefill, decode, routing, and other roles) as a single Custom Resource with varying hierarchies, coordinating them with awareness of dependencies and resource needs.
Due to the flexibility of the API, Grove can support hierarchical gang scheduling, topology-aware placement, multilevel autoscaling, and explicit startup ordering. This ensures the right components scale together, start in the correct sequence, and are placed for optimal GPU and network performance. By treating inference systems as unified operational units, Grove improves reliability, resource efficiency, and scalability—from single replicas to data center scale—while reducing operational complexity.
Who benefits from Dynamo?
You might be thinking that Dynamo sounds amazing for every inference use case. After all, who wouldn't want to benefit from efficiency gains, lower latency, and increased ROI?
To a large extent, we'd agree with that.
Dynamo delivers the greatest benefits to customers with demanding workloads, such as:
- Frontier Mixture of Experts (MoE) reasoning models
- Multi-turn chat with long context windows
- Agentic applications that combine LLMs with external tools and services
- Deployments spanning multiple GPUs, nodes, or GPU types where utilization and coordination are critical
One-click Dynamo deployment on Gcore AI
Dynamo is available today on Gcore Inference and Everywhere AI. Gcore customers know we're all about making AI efficient to use, so we're offering Dynamo as a fully managed solution for selected LLMs. We handle all routing, KV-cache logic, and GPU scheduling behind the scenes, so you can benefit from Dynamo at the click of a button. This makes Gcore the simplest way to benefit from Dynamo across public cloud, private cloud, hybrid, and on-prem inference environments.
NVIDIA is actively evolving Dynamo with more features expected soon, and we'll continue to deliver those updates to our inference customers with the same deployment simplicity you've come to expect from Gcore.
Get Dynamo on Gcore today: all the power, none of the complexity.
Dynamo is available in public, private, and hybrid cloud and on-prem environments. Discover what else Everywhere AI has to offer, or get in touch for a Dynamo demo.

Related articles

For many startups, infrastructure decisions are mostly about performance, pricing, and developer experience. For Melious AI, they are also about trust.Melious AI is a German startup building a European AI platform around privacy, transparen

As enterprises move AI from experimentation into production, they face a new infrastructure challenge. AI applications, models, and data are no longer confined to a single cloud or data center. Instead, they are distributed across multiple


2025 quietly became the year DDoS stopped being a "big company" problem. The bandwidth record was broken several times in a single year, each new peak holding for weeks rather than years. In one quarter alone, providers blocked roughly 20 m

Panels about AI sovereignty tend to follow a predictable arc. Someone invokes GDPR. Someone else mentions hyperscalers. A politician says something optimistic. Everyone applauds and goes home.Last week's Gcore AI panel in Luxembourg didn't
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.