
An application’s success can also be its downfall if it’s not able to work effectively at scale with thousands of daily users. If your application infrastructure capacity is initially set too low, you will need to redesign and reimplement your system when your application’s popularity grows in order to handle the increased traffic. This is why your application’s autoscaling capability is crucial. With autoscaling, your application’s server resources can be increased automatically to meet the growing number of user requests. If there are fewer requests, the server resources will instead be decreased, allowing you to optimize the cost of your infrastructure. In this article, we’ll explain what autoscaling is, how it works, and why and how you can effectively and easily apply autoscaling to your future applications.
What Is Autoscaling?
Autoscaling is a feature that allows your applications to adapt to different numbers of user requests automatically. If user requests are low, your server resources are automatically reduced to save costs. If the number of requests increases, resources are automatically added to your application server to handle requests efficiently.
With traditional infrastructure management, if you notice a lot of user requests, you need to increase the application servers’ resources by scaling them manually. This is not an easy task since your app may contain many system components; while you’re scaling the servers, your users will experience significant downtime. After you have increased the resources for your servers, there may be times when the number of user requests is lower, such as on weekdays or in the middle of the night. Constantly running your application servers at high capacity is not cost-efficient.
Types of Autoscaling
There are two types of autoscaling:
- Vertical autoscaling
- Horizontal autoscaling
Let’s look at each in turn.
Vertical Autoscaling
With vertical autoscaling, the size of your server is automatically increased as more resources are needed. Take a blog service as an example. To handle more API requests from users, the size of the server that hosts your PostgreSQL database needs to increase by adding more CPUs, RAM, and disks.
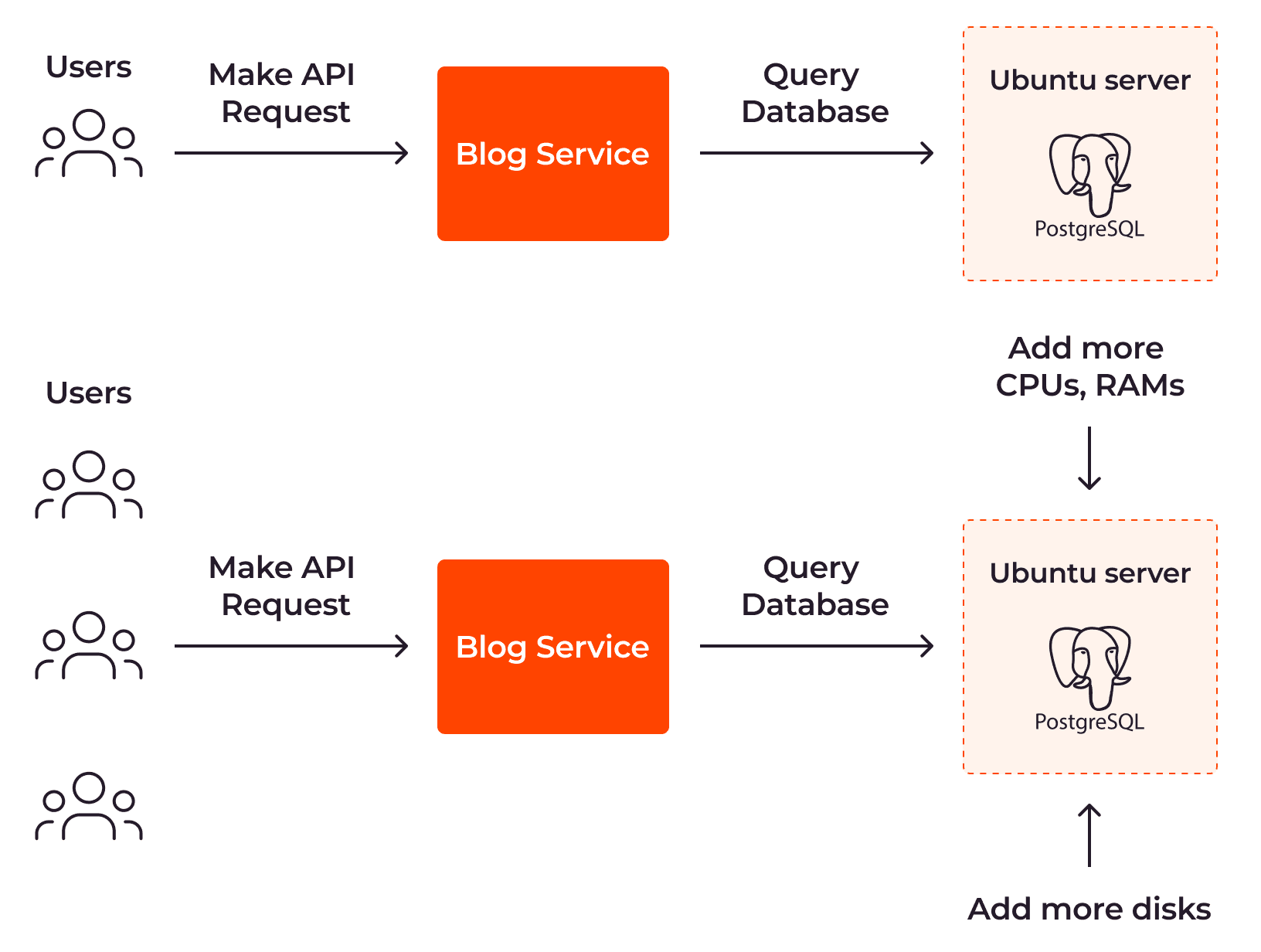
We often use the terms “scale up” and “scale down” when talking about vertical scalability. When scaling up, your resources are increased so that they have more memory or more CPUs to handle more requests. When scaling down, your resources contract to use less memory or fewer CPUs to reduce the cost.
Vertical autoscaling is usually applied to centralized systems, because they are not designed to be distributed across multiple instances. They typically run on a single or tightly coupled group of instances, which makes it difficult to apply horizontal autoscaling.
Horizontal Autoscaling
With horizontal autoscaling, the number of servers is updated automatically and responsively. With this approach, a PostgreSQL node is added to handle the growing number of user requests.
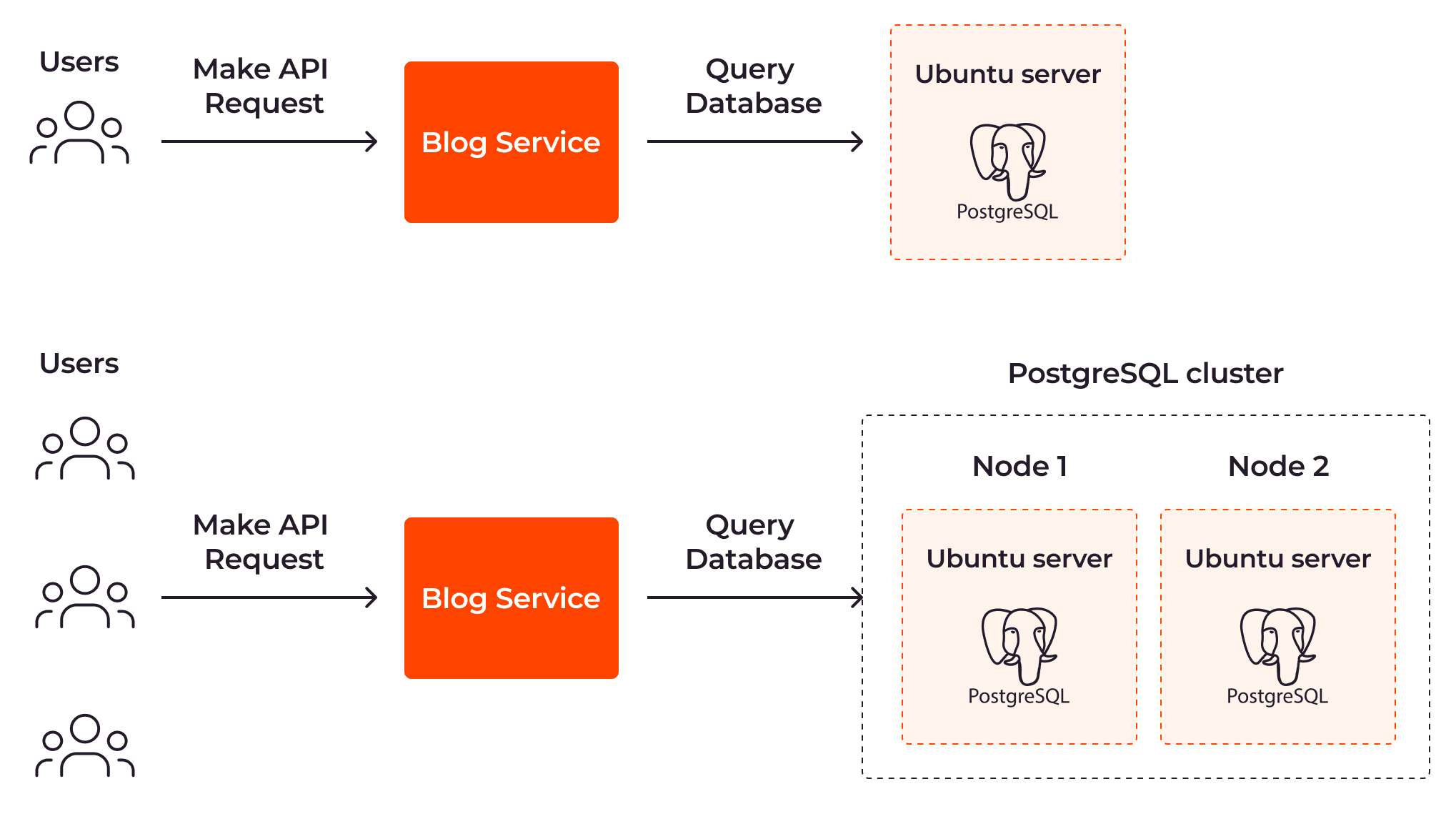
The terms “scale out” and “scale in” are used to refer to horizontal scalability. When scaling out, more instances of your resources are created; when scaling in, existing instances are removed.
Horizontal autoscaling is often applied to distributed systems. Distributed systems are designed to make working with multiple instances in different geographic distributions more efficient. Applying horizontal autoscaling to distributed systems allows them to be scaled efficiently and enhances fault tolerance by spreading the workload across multiple nodes.
How Does Autoscaling Work?
Autoscaling works by dynamically adjusting the server resources according to the current workload generated by users.
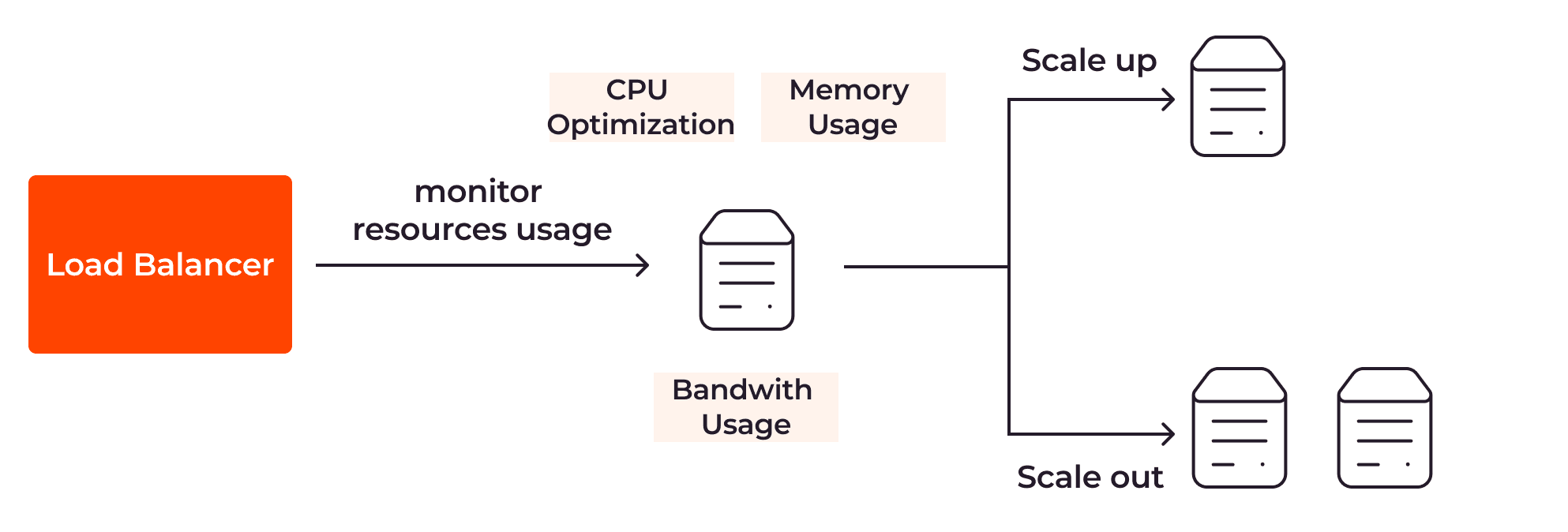
To apply autoscaling, there are a number of tasks involved, including monitoring the servers, triggering the autoscaling, and load balancing user traffic. Let’s break down these tasks to understand how autoscaling works behind the scenes.
Monitoring
Autoscaling uses monitoring tools to continuously collect server metrics such as CPU optimization, memory usage, response time, or network traffic. Each metric has its advantages and disadvantages. For example, CPU optimization data is easy to collect and usually indicates workload intensity. However, this metric is not sufficient for services that use many graphic cards, such as modeling, in which case both GPU optimization and CPU optimization should be monitored. Therefore, the autoscaling mechanism should be applied based on a group of different metrics, instead of depending solely on one.
Triggering
Autoscaling triggers the scaling process differently based on the autoscaling method in place (more on this in the Autoscaling Methods section,) whether through predefined schedules, alerts, or events. If you’re using scheduled autoscaling, it will trigger the scale of the application according to the predefined schedule. If you’re using reactive autoscaling and the thresholds for server metrics are breached, an alert will be created to initiate the scaling process. If you use predictive autoscaling—the autoscaling method that uses AI or machine learning services to identify whether the application needs more resources—an event will be created to trigger the scaling task instead.
Adjusting
Depending on the platform you’re using, the component responsible for adjusting server resources is different. Let’s take Kubernetes as an example. With Kubernetes, to autoscale the pods horizontally, the horizontal pod autoscaling controller (part of the Kubernetes control plane) adjusts the number of pods to handle the application workload. To apply autoscaling to the pods vertically, the vertical pod autoscaling controller inside the Kubernetes control plane adjusts the CPU number and memory size for the current pod instead.
Read: What Is a Kubernetes Cluster?
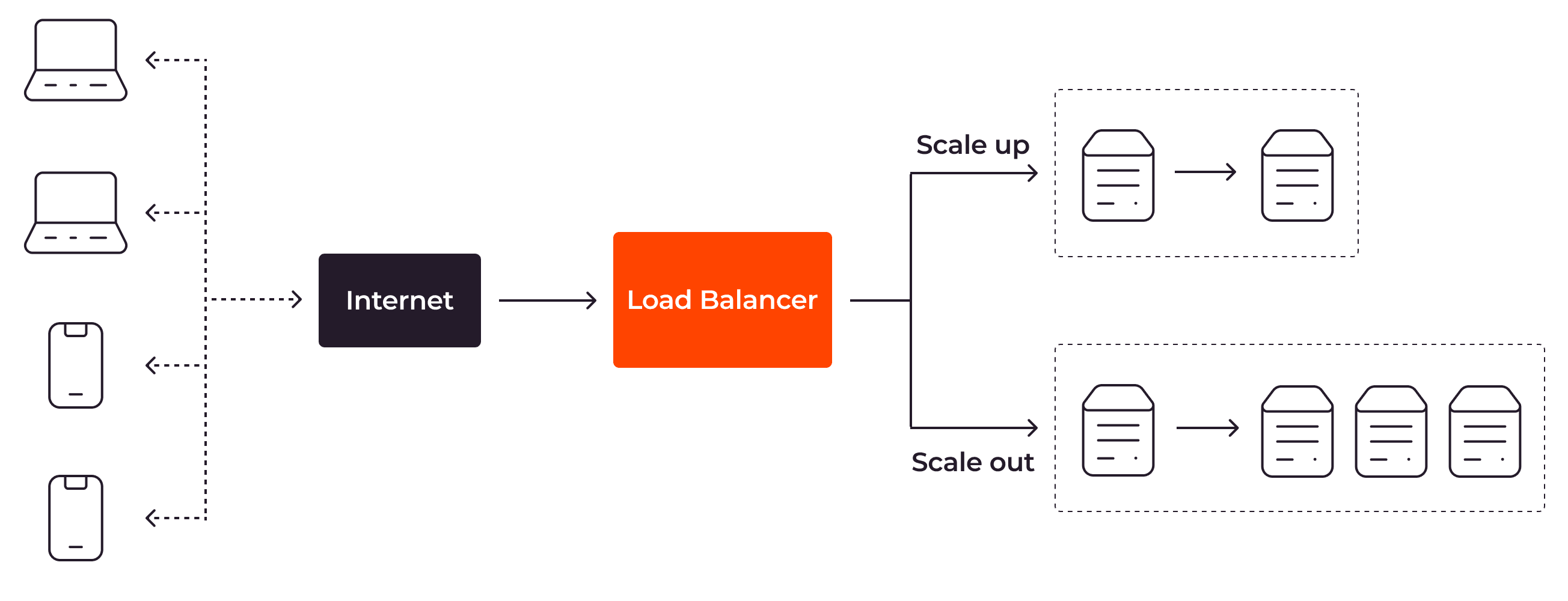
Load Balancing
User requests are distributed by the load balancer across multiple server instances according to certain rules. This prevents any single server from being overwhelmed.
Autoscaling Methods
There are three methods for applying autoscaling to your app: scheduled autoscaling, reactive autoscaling, and predictive autoscaling.
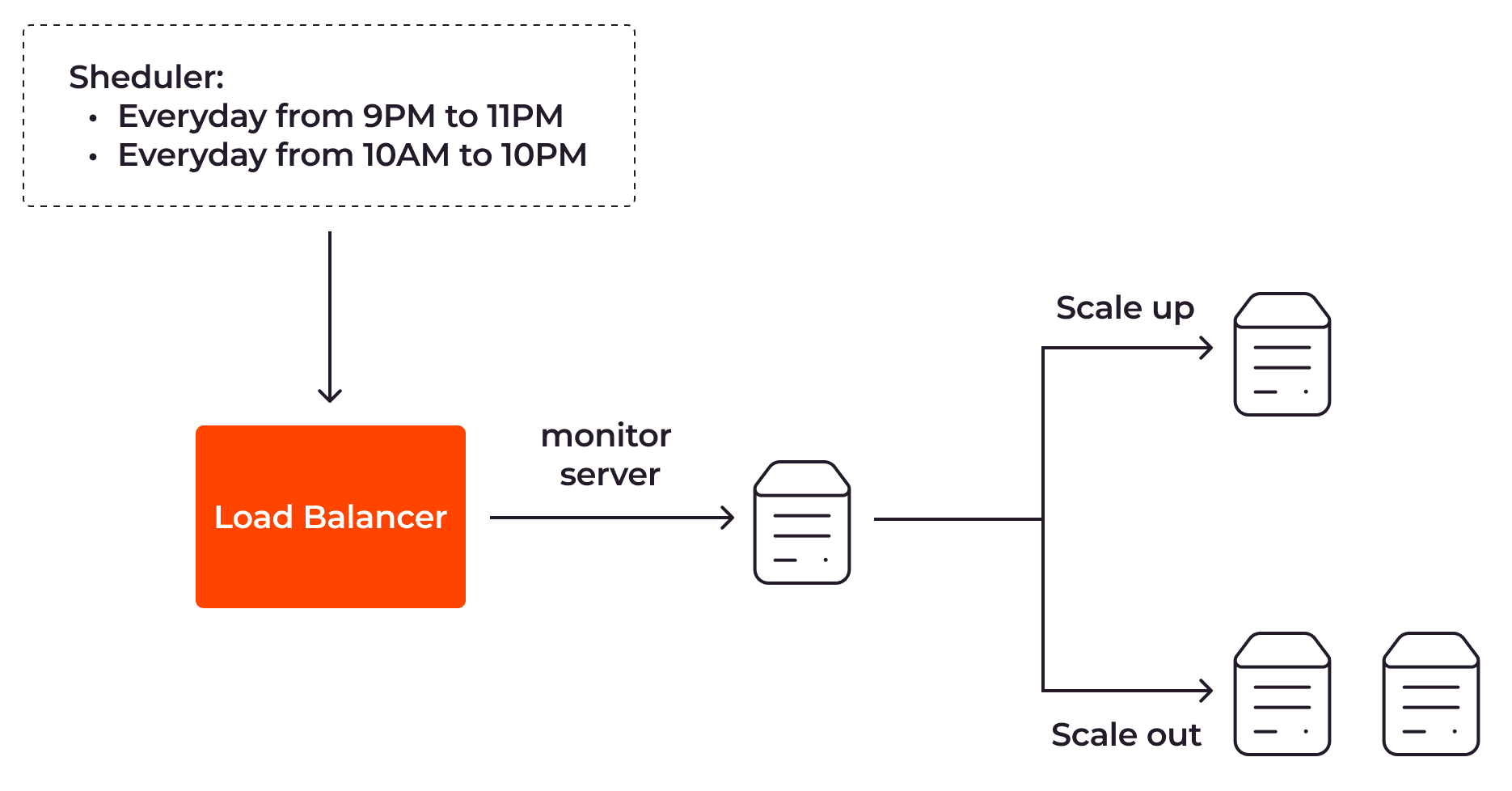
Scheduled Autoscaling
With scheduled autoscaling, your application servers are scaled according to a schedule that you set in advance.
Let’s say you have an online shopping web app that allows your customers to buy shoes and ties. Based on your application logs and metrics, you notice that they often visit the store on the weekend from 10 AM to 10 PM and on weekdays from 9 PM to 11 PM. With scheduled autoscaling, you can set your load balancer to use two servers at those times. At other times, one server instance should be enough.
Scheduled autoscaling is simple to set up and is well-suited for small applications with basic functionalities. However, it is ineffective for complex applications that are distributed globally with users worldwide. In this instance, you might want to use reactive autoscaling.
Reactive Autoscaling
Reactive autoscaling scales the app servers based on metrics such as CPU optimization, memory usage, and disk space.
To apply reactive autoscaling, you need to define the thresholds or conditions for your servers. For instance, if the average CPU optimization score exceeds 90%, the load balancer should add one more server instance. If the score is below 50%, the load balancer should remove one server instance from the server group.
Reactive autoscaling allows your application to scale flexibly in response to users’ interactions with your applications. However, one problem with reactive autoscaling is that the server resources might not be able to scale fast enough to handle the rapidly growing volume of user requests. As a result, users might experience poor performance—or even downtime.
Predictive Autoscaling
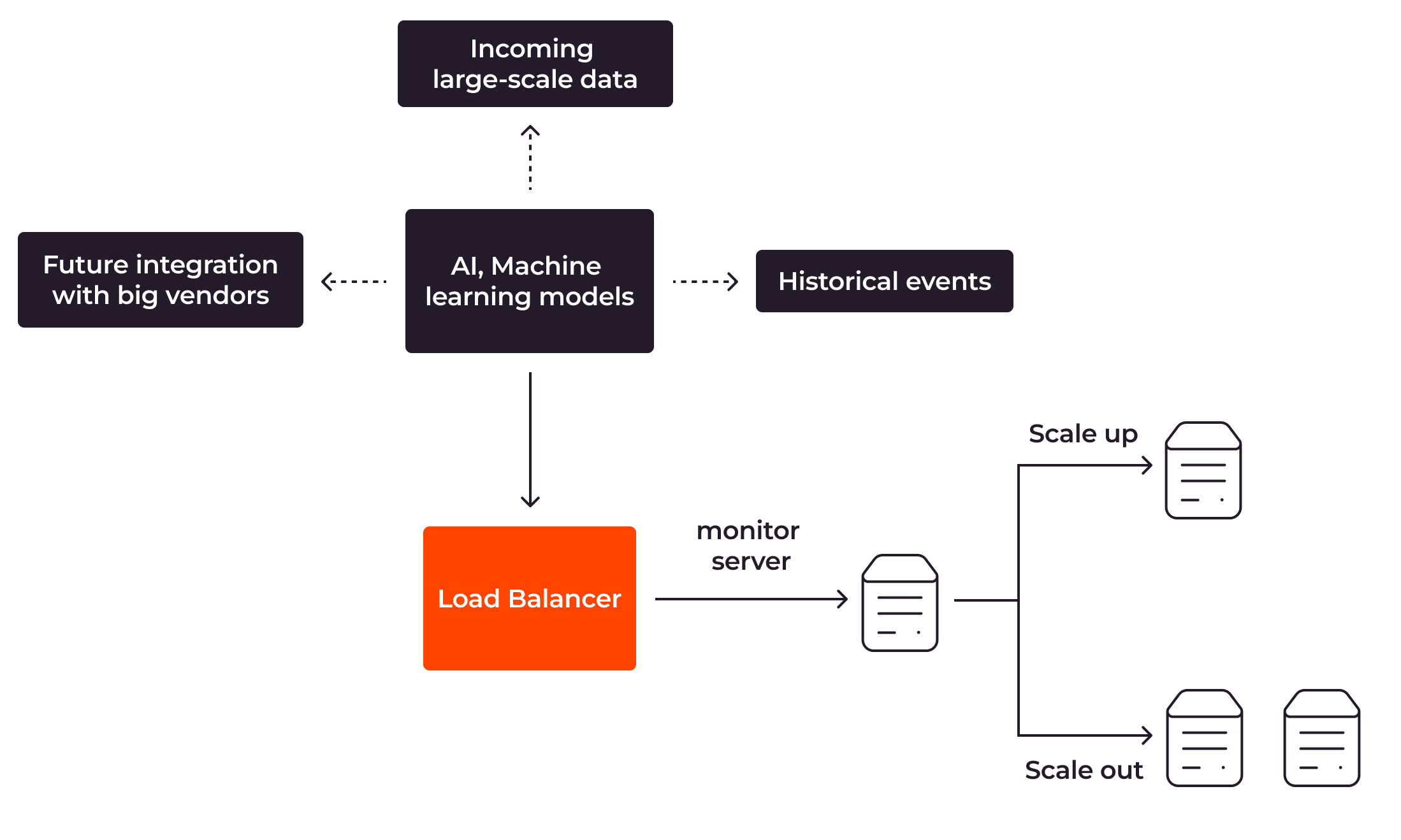
Predictive autoscaling is implemented using artificial intelligence or machine learning. It uses historical events and forecasting techniques to estimate the expected workload and system resource requirements.
Predictive autoscaling allows your application to be scaled right before it becomes necessary. If it is implemented effectively, it can scale your app efficiently without causing performance problems or downtime. However, applying predictive autoscaling is a sophisticated task and hard to implement effectively because it depends heavily on the relevance of the historical data collected and the effectiveness of the forecasting models.
Zero Autoscaling
Most autoscaling methods require you to have at least one server node to begin with. Zero autoscaling allows you to start with no nodes if there is no requirement for server resources yet, and to scale out with nodes when the demand for the resources grows.
Zero autoscaling is helpful for application features that require heavy compute power and advanced technology, such as sequencing the whole genome in the human body. With such tasks, it is prohibitively expensive to keep the server running all the time when there’s no demand for it. Zero autoscaling allows you to optimize the cost of your infrastructure completely.
If you’re interested in using zero autoscaling for your application, check out Gcore Function as a Service (FaaS.) With Gcore FaaS, you can run and update your code in a cloud-made environment with ultimate flexibility. FaaS automatically scales to match the workload as your application gains more users. You get optimized infrastructure costs with the zero autoscaling capability that Gcore FaaS offers.
How to Enable Autoscaling for Applications
Many components play a role in an application running efficiently, including network systems, load balancers, databases, backend services, or frontend services. Autoscaling an application requires all these components to scale. Of them, databases and services are the most important because they are responsible for heavy computational tasks, such as executing complicated queries or running complex machine-learning models.
Autoscaling for Databases
For databases to work effectively, their performance and data storage capabilities must be autoscalable.
Autoscaling for Performance
Performance autoscaling allows you to apply vertical scaling to the databases directly by setting the mechanism to automatically add new server resources—like CPUs or RAM—to the current database node.
For distributed systems, you should autoscale the databases by applying horizontal scaling techniques, such as read replicas or database clustering. Using read replicas, the replicated database nodes are synchronized with the primary node, which helps in offloading read requests or analytics traffic from the primary node, while database clustering adds more servers to the cluster to work as a single powerful database.
Autoscaling for Data Storage
Data storage autoscaling ensures that data storage will be increased automatically when there is no longer enough space to store new data. For instance, if you have a large Hadoop cluster for storing structured and unstructured data, you can set the autoscaling mechanism to add more storage nodes to the existing cluster when the current storage is about to reach its limit.
Autoscaling for Services
To apply autoscaling to backend or frontend services, it’s vital to have access to application and server metrics such as response time, bandwidth usage, or memory usage. Based on these metrics, you can trigger the autoscaling feature by adding more server resources directly to the existing server or horizontal scaling by creating more service instances for more user requests.
Benefits of Autoscaling
Applying autoscaling to your application is a sophisticated task that demands monitoring, triggering, and load-balancing processes for various databases and services. However, the results you receive will justify the effort.
Cost Optimization
With the ability to scale in or down when fewer requests are sent to the server, you can control server costs by reducing wasted expenses. This is crucial, both for startup companies with limited budgets and for global companies with millions of users.
Reduced Downtime
Autoscaling allows new server instances to be added immediately when performance issues are seen on the existing servers. As a result, end users won’t experience the application downtime caused when you must scale the server manually.
Performance Optimization
Autoscaling improves the performance of your application by adding server resources before issues arise.
Lower Energy Consumption
By scaling in or scaling down server resources when they are not needed, autoscaling lowers electricity usage and network bandwidth. It also extends the lifespan of the server facilities. As a result, it’s fair to say that autoscaling even contributes to sustainability efforts in the tech world.
Automation
Autoscaling allows your application to be scaled automatically without human intervention. This removes the need to constantly monitor application metrics and system resources, which is time consuming and mentally exhausting, freeing up your time to work on other tasks, such as setting up the infrastructure for a new project.
Autoscaling Best Practices
To leverage the advantages of autoscaling, you should apply these five best practices:
#1 Ensure that the minimum nodes and maximum nodes values for the autoscaling configuration are different. When configuring the autoscaling mechanism, you usually need to indicate the minimum and maximum number of nodes for your servers. By defining the minimum number of nodes, you ensure that your application will always have enough system resources to run, even if only a few requests are sent to the server. With a limit on the maximum number of nodes, you ensure that if application errors or security incidents such as DDoS attacks happen, the system will not add too many servers. If the minimum nodes and maximum nodes have the same value, your autoscaling setup will not work because the number of nodes is always the same regardless of the workload on the servers.
#2 Choose appropriate performance metrics depending on your application requirements. You must apply the metrics that suit your app for autoscaling to work efficiently. This is especially important for reactive autoscaling based on application and server data, such as CPU optimization, response time, or memory usage. For example, real-time video game applications should use concurrent players’ metrics and other common metrics, such as CPU optimization or memory usage, to apply the autoscaling mechanism efficiently.
#3 Set a conservative threshold for your metrics with buffering in mind. The application of autoscaling is usually accompanied by a delay, so it’s always better to set thresholds for your metrics with buffering in mind. For example, for applications with a high traffic workload, set the maximum CPU optimization to 80% so that if there’s a delay in autoscaling your servers, the existing servers can still withstand the workload.
#4 Set autoscaling notifications. Set autoscaling notifications to alert you when problems arise. For example, you should be notified if the autoscaling mechanism is rapidly adding new servers to handle a growing number of requests. With that information in hand, you can quickly identify the need for DDoS mitigation and take steps to address it.
#5 Opt for reactive or predictive autoscaling over scheduled autoscaling. While scheduled autoscaling is simple to implement, it can easily go wrong if unexpected events occur, leading to performance issues or downtime. For example, a local online shopping site might experience an unpredicted spike of soccer shirt sales before an upcoming championship match.
Autoscaling FAQs
1. What are the differences between autoscaling and load balancing?
Although these two processes have functions that overlap, they differ from one another. Autoscaling is the process of applying automatic scaling to your application. Load balancing is one of the steps in that process: the distribution of the workload according to rules across server instances.
2. What are the differences between autoscaling and high availability?
Autoscaling allows you to scale your app automatically. As a result, users won’t experience application downtime, because your app can scale quickly and efficiently. High availability ensures that your application is live and accessible so that users do not encounter downtime issues. Autoscaling is one of the factors that contributes to high availability.
3. Can I apply infinite autoscaling to my app?
With horizontal scaling you can autoscale your app almost infinitely since you can have thousands—or even millions—of server instances. With vertical scaling, you are bound by the limited resources a single server can provide.
4. Is there a way to apply autoscaling to a centralized system?
Yes, you can apply autoscaling to a centralized system using a vertical scaling approach. However, unlike a distributed system, a centralized system encounters scalability-limitation issues.
Conclusion
Autoscaling allows your application to handle the application workload in a flexible, reactive, and predictive manner, without human intervention. It also helps you to optimize the cost of your infrastructure, a critical need for your company’s operational efficiency.
If you’re using Kubernetes to orchestrate your application containers, check out Gcore Managed Kubernetes. With Gcore Managed Kubernetes, you can quickly apply autoscaling for your Kubernetes in a matter of minutes, so that you can spend your time developing and deploying new features, instead of manually configuring the Kubernetes cluster from scratch. If you want to quickly implement a new feature to extend the functionality of your application, such as creating a notification service to send messages to Slack when a new user signs up, check out Gcore Function as a Service. Gcore FaaS allows you to run and update code in a ready-made environment so that you can deploy your new feature to solve your business needs right away.
Interested in Gcore Managed Kubernetes and Gcore FaaS? Start with managed Kubernetes services now.
Related articles





Imagine discovering that migrating your company's data to a new cloud provider will cost hundreds of thousands of dollars in egress fees alone, before you've even touched the re-engineering work. Or worse, picture being in Synapse Financial

Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.