Unwanted background noise, such as a barking dog or a neighbor’s drill, can disrupt work and personal video calls alike, hampering effective communication and causing frustration to participants. In response, platforms like Google Meet, Microsoft Teams, and Discord use AI-based, cloud-based denoising algorithms—but these solutions often require sending audio data to external servers for processing, demanding significant server resources and introducing additional latency. This article will explore alternatives for enhancing audio quality without compromising performance or increasing cost.
WebRTC Noise Reduction Solutions
To combat disruptive background noises in WebRTC applications, like voice calls and video conferences, two categories of noise reduction methods are available: software and hardware. In this article, we won’t tackle hardware-specific solutions, like Nvidia RTX Voice, as they depend heavily on the end-user’s hardware. Instead, let’s look at some software approaches that can be applied more universally. Software solutions vary from simple noise gate to advanced machine learning algorithms that isolate and remove ambient sounds.
OS Native Noise Cancellation
Many modern operating systems include built-in noise cancellation features within system settings, for example, Microsoft Windows offers Voice Capture DSP, and MacOS offers the Voice Isolation feature in Ventura 13. Here’s how to find and manage this feature in various operating systems.
Windows
- Open the Sound settings by right-clicking the speaker icon in the taskbar and choosing Open Sound settings.
- Click on Device properties for your microphone and select Additional device properties.
- Find the Enhancements tab.
- Check the Noise cancellation box to enable the feature.
macOS
For a video call:
- Click the “Video” button in the menu bar.
- Click the down arrow next to the microphone icon.
- Click the right arrow next to “Mic Mode.”
- Select “Voice Isolation.”
For an audio call in the FaceTime app:
- Click the “Audio” button in the menu bar.
- Select “Voice Isolation.”
Linux
Noise cancellation is available on Linux, usually through the PulseAudio sound server or Cadmus application, but exact steps may vary with your specific Linux distribution.
Pros and Cons of Native Noise Cancellation
Native noise reduction has both advantages and drawbacks.
Pros:
- Once enabled, the feature is always on making it seamless and convenient for users who may not be tech-savvy.
- Processing happens locally, reducing server load and potentially lowering costs for service providers which can be passed on to end users.
Cons:
- Not as effective filtering ambient noise compared to more specialized methods.
- CPU-intensive, which could slow down other local applications or tasks running on the system—especially problematic for older devices with limited computing resources.
- Availability is inconsistent across different operating system versions. For instance, a feature present in the latest version of Windows might not be in older versions, creating a fragmented user experience.
Basic In-Browser Software Solution
In web-based applications, developers can easily activate a basic noise suppression feature by adding the constraint noiseSuppression = true when calling the method that captures an audio stream from the user’s browser. This one-step process works across multiple browsers and requires no manual setup from the end user. You can find further details in the browser’s official documentation.
Pros and Cons of In-Browser Software Solutions
This method also has its advantages and drawbacks.
Pros:
- Easy to implement.
- Widespread browser support makes this an accessible option for many users.
- Processing happens locally, reducing server load and potentially lowering costs for service providers which can be passed on to end users.
Cons:
- Not as effective filtering ambient noise compared to more specialized methods.
- Browsers nowadays are resource intensive, and these solutions add more stress to the CPU, potentially resulting in serious performance issues like overheating, stuttering, or machine freezes.
- Lack of support in Safari limits the reach of this solution among macOS and iOS users.
- Only works within browsers, not for other non-browser applications.
Server-Side Solutions
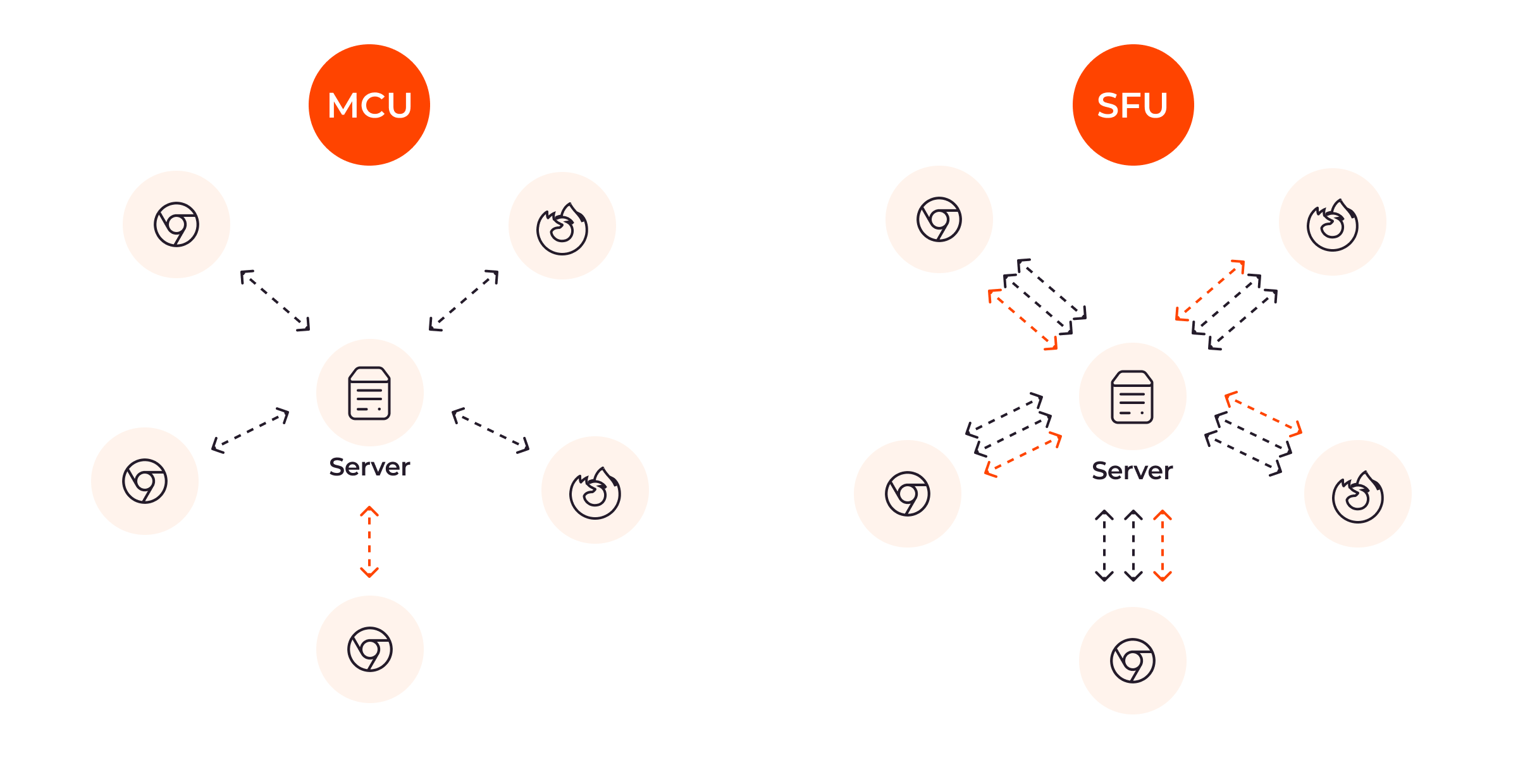
Server-side solutions provide a powerful approach to noise reduction by processing audio streams directly on the server rather than on the client side. This method is particularly effective in applications that employ either a Multipoint Control Unit (MCU) or a Selective Forwarding Unit (SFU). An MCU blends multiple streams into a unified output, enhancing audio quality, while an SFU routes individual video streams to participants without merging them. This allows for optimized audio quality across various communication setups.
Pros and Cons of Server-Side Solutions
The server-side approach has its own advantages and challenges.
Pros:
- Advanced noise suppression algorithms are available for superior audio quality, and can be sourced from projects like the DNS Challenge.
- Option to aggregate multiple audio streams into a single processed stream for efficient delivery to end users, improving user experience.
- Relieves the user’s device from additional audio processing load.
Cons:
- Requires substantial server computational power, complicating system architecture and increasing the costs associated with server maintenance.
- Expenses scale with the number of users, making it less economical for larger deployments and therefore not suitable for all use cases.
RNNoise: Gcore’s Choice
Following a rigorous evaluation process that involved real-world scenarios, we’ve opted to use RNNoise for our Real-Time Video and WebRTC product. Written in C and built on a recurrent neural network, it can easily be compiled into WebAssembly (Wasm) using the Emscripten compiler and integrated into your WebRTC application.
Our team found RNNoise to be the optimal choice for the following reasons:
- Broad-spectrum noise elimination. RRNoise’s effectiveness is rooted in its extensive training on a diverse array of real-world noise conditions, enabling it to reduce all kinds of background noise.
- Resource efficiency. The algorithm’s low CPU usage ensures it’s suitable for real-time applications and a broad spectrum of devices, including smartphones, tablets, and laptops.
- Open-source flexibility. Being open-source, RNNoise allows for customization and control—valuable for organizations looking to fine tune their noise-cancellation solutions.
These attributes made RNNoise a compelling choice in our quest to improve audio quality across our services. Here are some examples:
This is an audio sample with street ambient noises:
And that’s what you will hear with RNNoise enabled:
Another test sample with vacuum cleaner running on the background:
And the same audio sample after RNNoise:
As you can hear, both samples sound much clearer with RNNoise enabled.
Pros and Cons of RNNoise
Let’s summarize RNNoise’s pros and cons.
Pros:
- Offers real-time, high-quality noise suppression.
- Relatively low CPU usage, especially beneficial for older or less powerful devices.
- Audio data is processed directly on the end user’s device, potentially resulting in cost savings for the service provider.
- Allows for WebAssembly compilation, making it feasible for client-side implementation.
Cons:
- RNNoise technology dates from 2018, so it may not include the most recent advancements in noise suppression.
- While effective for general use, RNNoise might lack some advanced features available in proprietary solutions.
How to Integrate RNNoise Into the WebRTC Web Apps
Here’s how to integrate RNNoise into a WebRTC web application:
1. Compile C Source Code to WASM Using Emscripten
To compile C sources to WASM, use Emscripten compiler. The following script compiles librnnoise into a WASM module encapsulated in a JavaScript file:
if [[ `uname` == "Darwin" ]]; then
SO_SUFFIX="dylib"
else
SO_SUFFIX="so"
fi
emcc \
-Os \
-g2 \
-s ALLOW_MEMORY_GROWTH=1 \
-s MALLOC=emmalloc \
-s MODULARIZE=1 \
-s ENVIRONMENT="web,worker" \
-s EXPORT_ES6=1 \
-s USE_ES6_IMPORT_META=1 \
-s WASM_ASYNC_COMPILATION=0 \
-s SINGLE_FILE=1 \
-s EXPORT_NAME=createRNNWasmModuleSync \
-s EXPORTED_FUNCTIONS="[’_rnnoise_process_frame’, ’_rnnoise_init’, ’_rnnoise_destroy’, ’_rnnoise_create’, ’_malloc’, ’_free’]" \
.libs/librnnoise.${SO_SUFFIX} \
-o ./rnnoise-sync.js
This will generate a JavaScript file called rnnoise-sync.js that contains the compiled WASM module.
You can integrate WASM-compiled C code into your WebRTC application for audio processing, efficiently handle frame size mismatches, and manage data transfer between WASM and JavaScript environments.
Now, let’s turn to setting up an audio processing pipeline using Web Audio API. This process comprises steps 2–4.
2. Create Audio Processing Node
Create an audio processing node using the Web Audio API. Each node corresponds to an audio processor class where the actual processing occurs. Given that the only effect you want to apply is noise suppression, one processing node will suffice. In this node we import rnnoise-sync.js to make RNNoise methods available in our JS environment.
The data process will then work as follows:
- Audio samples are received from an audio device, with 128 samples per frame.
- These samples are buffered until they reach the required 480 samples for RNNoise processing.
- The accumulated samples are transferred to the heap and processed by RNNoise.
- Once processed, the samples are returned to the buffer.
- The buffer sends 128 samples per frame to the audio output.
3. Buffering
The processing node gets a frame of 128 samples per one process method call. In other words, the process method gets an array of 128 32-bit floating-point values—this is the input that needs to be processed.
Since Web Audio API’s process method operates on 128-sample frames and RNNoise expects 480-sample frames as an input, you’ll face a frame size mismatch—a common issue for audio processing engineers. To solve this problem, incorporate a circular buffer design pattern. Use the GoogleChromeLabs’ implementation algorithm as a basis.
4. Data Exchange
As the audio processing pipelineis written in JavaScript, while RNNoise is written in C, communication must be established between these environments. To manage data exchange between the JavaScript and Wasm environments, use a heap allocated by the malloc method generated by Emscripten. Float32Array is used for storing audio samples, requiring 4 bytes per sample. Therefore, to accommodate 480 samples (the RNNoise frame size), a heap size of 1920 bytes, or (480 * Float32Array.BYTES_PER_ELEMENT) must be allocated.
Conclusion
Effective noise suppression can make or break the quality of video conferences. RNNoise offers an effective balance of noise elimination and computational efficiency, making it an ideal choice for real-time applications. At Gcore, we use this technology to enhance our WebRTC solution, elevating the audio quality of your virtual interactions.
Curious to experience superior audio quality in your video? Explore Gcore Real-Time Video & WebRTC to find out how we can customize your experience.







